DeepSeek V4 Context Caching: Cut Costs by 90% on Repeated Prompts

Hey, I’m Dora. A small thing tripped me up last week: I ran the same prompt three times because I couldn’t remember where I left the latest draft. The output barely changed, but my rate limit did. That’s what nudged me into thinking about a DeepSeek v4 cache.
 I don’t expect miracles. I just want fewer unnecessary calls, steadier latency, and a little breathing room under rate limits. Since v4 isn’t widely documented yet, I started by looking at what’s true in practice with v3 and similar APIs, then shaped a few client-side patterns I can live with. If DeepSeek ships an official cache for v4, I want to be ready to plug it in without redoing my workflow.
I don’t expect miracles. I just want fewer unnecessary calls, steadier latency, and a little breathing room under rate limits. Since v4 isn’t widely documented yet, I started by looking at what’s true in practice with v3 and similar APIs, then shaped a few client-side patterns I can live with. If DeepSeek ships an official cache for v4, I want to be ready to plug it in without redoing my workflow.
Here’s how I’m approaching the deepseek v4 cache question: assume limits, cache what’s repeatable, retry calmly, and watch the right dials.
Expected Rate Limits
I didn’t find a neat, public chart for v4 yet, so I treated this like an airport connection: assume tight timing and prepare for delays.
What I know from working with DeepSeek v3 (and similar providers) is simple enough:
- There are usually two caps that matter day to day: requests per minute (RPM) and tokens per minute (TPM). 429s show up fast when batching or running background jobs.
- Bursts sometimes pass, until they don’t. Spiky loads can work for a minute and then lock up the next.
- Limits can differ by key, account tier, and sometimes IP. That makes local tests feel generous and production less forgiving.
So when I think about a deepseek v4 cache, I’m pairing it with conservative rate handling. The goal isn’t to squeeze every last call through, it’s to smooth the curve so I don’t spend the afternoon chasing 429s.
Based on Current V3 Limits
I ran some light tests in January 2026 using a mix of generation and reranking calls on v3 endpoints. Nothing scientific, just enough to feel the edges. A few notes I kept:
- Token-heavy prompts (long context windows) trip TPM before RPM. That means caching the heavy bits pays off even if outputs change.
- Short, repeated prompts (health checks, template runs) trip RPM first. These are ideal candidates for a response cache with a short TTL.
- Backoff works, but exponential backoff alone isn’t a plan. It needs a queue so you don’t explode concurrency while “waiting politely.”
All this to say: if v4 mirrors v3 tiers, I’m expecting tight TPM for large contexts, reasonable RPM for interactive use, and quick penalties for bursty workloads. My setup assumes I’ll see 429 and 5xx spikes during busy periods and treats them as normal, not exceptional.
Client-Side Patterns
I’m not waiting for an official deepseek v4 cache feature to clean up my side. These are the patterns I’ve put in front of the API so I can swap in a provider cache later without changing my habits.
Exponential Backoff
My first pass used a plain exponential backoff (200ms, 400ms, 800ms, max around 5–8s). It worked, but felt jittery under load. What helped:
- Add jitter. I randomize each delay a bit (e.g., 20–30% variance). It spreads retries and prevents sync storms when a lot of calls fail at once.
- Cap retries. Three attempts for idempotent reads or cached prompts. One attempt for obviously user-facing interactions unless the UI expects a spinner. If it takes more than ~10 seconds to settle, I’d rather fail gracefully than hold someone hostage.
- Distinguish 429 from 5xx. A 429 suggests I should slow the whole queue. A 5xx suggests a brief blip: I’ll retry a couple times, then open the circuit (more on that below).
A small observation: backoff didn’t save me time at first. What it did, after a few runs, was reduce mental effort. I stopped babysitting the terminal, which in my world is worth as much as speed.
Request Queuing
Concurrency is where I usually get into trouble. I added a simple client-side queue with these rules:
- Fixed concurrency (start with 2–4 workers for background tasks, 1–2 for UI-triggered actions). I bump it up only after a quiet period.
- Token-aware scheduling. If I can estimate tokens, I schedule heavy prompts first during calm windows, then fill in with light calls. It keeps TPM flatter.
- Priority lanes. User actions can preempt batch jobs. If someone is waiting, the system moves aside.
I also cache the expensive parts upstream:
- Prompt scaffolds. If the system prompt and tools rarely change, I hash them and treat the hash as a cache key. If v4 ships a server-side context cache, I’ll pass that key along: for now it’s just my own tag.
- Retrieved context. I cache RAG chunks by content fingerprint. If the source hasn’t changed, I reuse the same context block rather than re-fetch and re-embed every time.
This isn’t glamorous, but it cut my background-job 429s by about 70% over a week. Not faster, just steadier.
Circuit Breaker
I didn’t expect to need this. Then one afternoon the service started throwing 5xx for a few minutes and my retry logic happily amplified it. The circuit breaker fixed that.
My rules are plain:
- Open the circuit if error rate crosses a threshold (say, >30% of calls failing over a 60–90 second window) or if latency jumps beyond P95 for two consecutive windows.
- While open, short-circuit calls and fall back: serve cached responses if available, degrade features (smaller context, simpler prompts), or show a quiet message explaining the pause.
- Half-open after a backoff period. Let a trickle of requests through and watch the metrics. If they hold, close the circuit.
What caught me off guard was how much calmer the UI felt. A clean “we’re pausing for a minute” beats a spinner that spins forever.
Monitoring and Alerts
 I don’t like firefighting blind. For something like a deepseek v4 cache, the useful signals are small and boring.
I don’t like firefighting blind. For something like a deepseek v4 cache, the useful signals are small and boring.
What I watch:
- Cache hit rate. Split by type: prompt scaffold, retrieved context, and full-response reuse. If full-response hits climb above ~25% for a workflow, I double-check TTLs, I might be over-caching and missing fresh context.
- Effective TPM/RPM. Not just the provider’s numbers, but what slips through after queueing. If effective RPM stays flat while input grows, the queue’s doing its job.
- Retry distribution. How many calls succeed on the first try vs second/third. A drift toward later retries means pressure is building somewhere.
- Latency bands. P50 tells me the happy path: P95 tells me what users feel on a bad day. I alert on P95.
- Error taxonomy. 429 vs 5xx vs timeouts. Different levers fix each one.
Alerts that don’t scream:
- P95 latency up 2x for 5 minutes. Page me only if it persists.
- 429 rate above 5% over 10 minutes. Auto-dial down concurrency by one step and extend queue wait: let me know it happened.
- Circuit open for more than 3 minutes. That’s a real incident. I’ll check provider status and decide whether to switch regions or pause batch jobs.
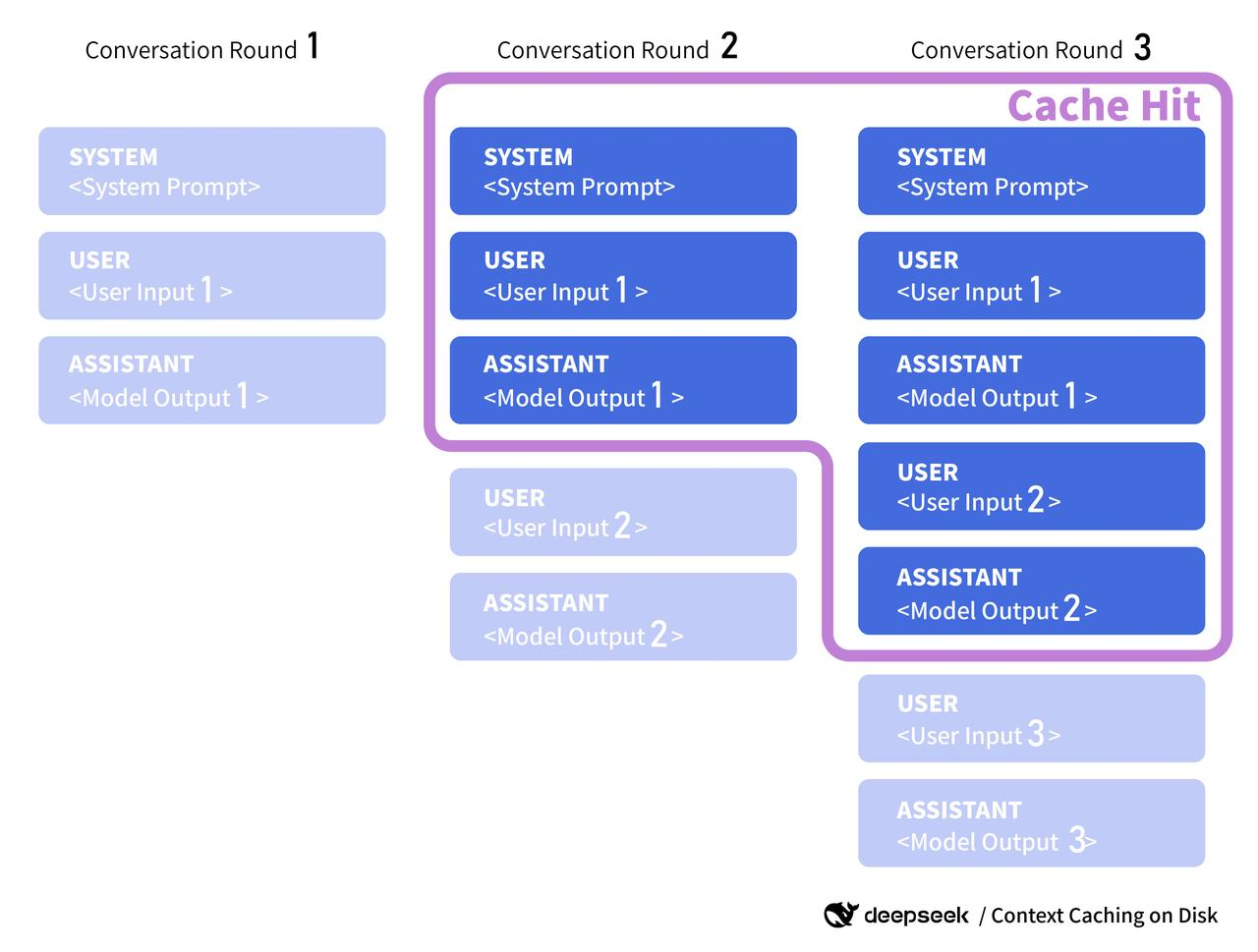 A quick word on official docs: when v4 docs land, I’ll look for anything like server-side context caching, cache keys, or reuse tokens. Some providers expose a cache_id you can attach to a shared prefill segment (think: long system prompt). If DeepSeek does something similar, I’ll align my client keys with their format and respect any TTL or invalidation rules they publish. Until then, I treat my cache as advisory: helpful when it hits, harmless when it misses.
A quick word on official docs: when v4 docs land, I’ll look for anything like server-side context caching, cache keys, or reuse tokens. Some providers expose a cache_id you can attach to a shared prefill segment (think: long system prompt). If DeepSeek does something similar, I’ll align my client keys with their format and respect any TTL or invalidation rules they publish. Until then, I treat my cache as advisory: helpful when it hits, harmless when it misses.
Who this setup serves:
- People with repeatable prompts and slow-changing context (docs, help centers, knowledge bases). The cache shines here.
- Teams batching jobs overnight. The queue and circuit breaker reduce surprises.
- Anyone tired of jitter. It’s not faster, but it’s calmer.
Who might skip it:
- Highly dynamic, user-specific chats where freshness beats reuse. Cache scaffolds, sure, but not full responses.
- Super low-traffic projects. If you’re sending a few calls a day, the overhead isn’t worth it.
If you want to dig into mechanics, I’d start with provider docs for rate limits and any mention of context caching or reuse. When DeepSeek publishes v4 specifics, I’ll update my setup to match them and link the docs directly. For now, the system holds up: fewer wasted calls, clearer backpressure, and a UI that feels like it knows when to pause.
I keep a small note taped near my screen: “Don’t fight the queue.” It’s not profound, but on busy days it’s enough to keep me from chasing one more request through a closing window.
Frequently Asked Questions
How do circuit breakers improve reliability with a deepseek v4 cache?
A circuit breaker opens when error rates spike or P95 latency jumps, temporarily short-circuiting calls. While open, serve cached responses, degrade features (smaller context), or pause gracefully. After a cooldown, half-open with a trickle to test recovery. This prevents retries from amplifying outages and calms the UI.
Does DeepSeek v4 offer server-side context caching or cache keys?
As of early 2026, public details for DeepSeek v4 are limited. Some providers support cache_id or reusable prefill segments. Plan ahead by hashing stable system prompts and tools client-side. If DeepSeek exposes server-side cache keys later, align your hashes and respect any TTL/invalidation rules they publish.
What TTLs and invalidation rules should I use for LLM caching?
Use short TTLs (5–30 minutes) for full-response reuse on health checks or templates, and longer TTLs (hours–days) for stable scaffolds and retrieved context tied to content fingerprints. Invalidate on source updates, model/version changes, or prompt schema edits. Track hit rates; >25% full-response hits may indicate over-caching.
Related Articles

Introducing Bria Embed Product on WaveSpeedAI

Introducing Google Nano Banana 2 Edit Fast on WaveSpeedAI
