HunyuanImage-3.0: Advancing Open-Source Multimodal Imaging
AI image generators are everywhere, but let’s be honest — the results can be hit or miss, especially with tricky prompts or a lot of details.
That’s where HunyuanImage-3.0 comes in! It’s the first open-source, industrial-grade multimodal model built for image generation, excelling in reasoning, style, and even long-text rendering.
The Core Advantages
Aesthetic Excellence
HunyuanImage-3.0 shows a deep understanding of Eastern aesthetics, including traditional festivals, opera, and cultural symbols. The model can generate authentic and visually impressive results. It also adapts effectively to various artistic styles, from classical Western art to modern design and cross-cultural projects, always staying true to the intended aesthetic.
World Knowledge Reasoning
Think of AI as having a brain that understands world knowledge. Powered by a vast knowledge base, HunyuanImage-3.0 can interpret even simple prompts, like creating a comic-style tutorial—and turn them into clear, creative, and contextually rich visuals.
Powerful Semantic Understanding
Most AI image generators struggle with long passages or fine print, but HunyuanImage-3.0 performs exceptionally well in these scenarios. It has strong text understanding, allowing it to accurately depict detailed textual content within images and produce impressive results.
Superior Quality
Trained on curated datasets and refined with RLHF, the model builds strong contextual awareness, enabling it to generate outputs that are not only logically consistent but also visually stunning.
See It in Practice
To demonstrate these capabilities. Now time for some examples!!
World Knowledge Reasoning
Since the model is loaded with all kinds of fun knowledge, let’s see if it can guide us through making ice cream.
Prompt: Create a comic tutorial on how to make ice cream.

How well does the model understand math? Let’s give it a shot!
Prompt: Draw the following system of binary linear equations and the corresponding solution steps on the blackboard: 5x+2y= 26; 2x-y= 5.

The model clearly shows a strong understanding of mathematical equations, solving each step correctly. To add some fun, let’s have it generate some emojis!
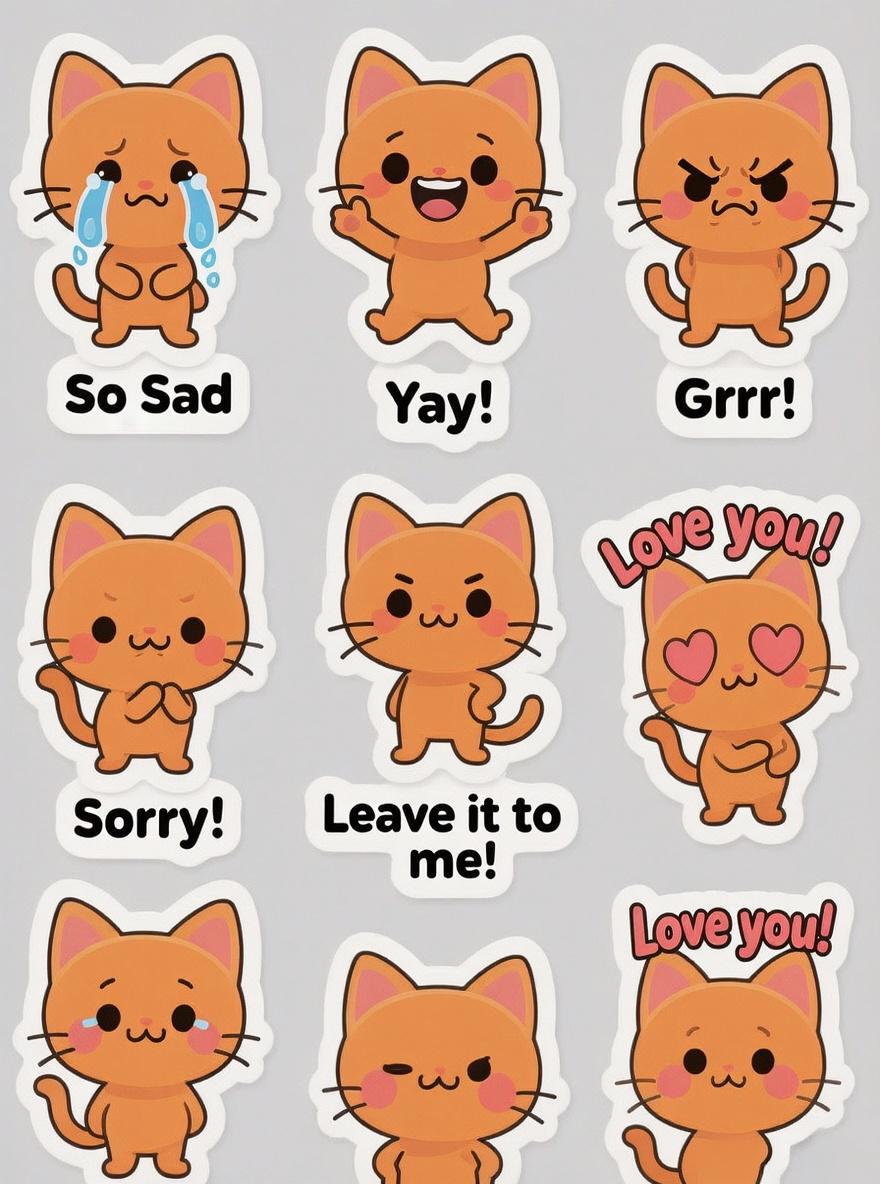
Prompt: Sticker sheet of a cute and expressive orange chibi cat. A set of 12 stickers, each showing a different emotion or action like crying, cheering, angry, sorry, and confident. Each sticker has a corresponding text label (e.g., “Sorry!”, “Love you!”, “Leave it to me!”). The style is clean, minimalist vector illustration with a thick white border, perfect for printing.
Super Strong Semantic Understanding
To evaluate the model’s ability with text, we’ll skip the simple tasks and move directly to the challenging part: writing long passages on the blackboard!
Prompt: A wide image taken with a phone of a glass whiteboard from a front view, in a room overlooking the Bay ShenZhen. The field of view shows a woman pointing to the handwriting on the whiteboard. The handwriting looks natural and a bit messy. On the top, the title reads: “HunyuanImage 3.0”, following with two paragraphs. The first paragraph reads: “HunyuanImage 3.0 is an 80-billion-parameter open-source model that generates images from complex text with superior quality.”. The second paragraph reads: “It leverages world knowledge and advanced reasoning to help creators produce professional visuals efficiently.” On the bottom, there is a subtitle: “Key Features”, following with four points. The first is ”🧠 Native Multimodal Large Language Model”. The second is ”🏆 The Largest Text-to-Image MoE Model”. The third is ”🎨 Prompt-Following and Concept Generalization”, and the fourth is ”💭 Native Thinking and Recaption”.

Awesome! The effect is fantastic!
Aesthetic Excellence
The last highlight is the model’s remarkable grasp of Eastern aesthetics.
Prompt: A Chinese beauty in a colorful Peking Opera costume, with a Chinese trend Huadan opera, a half-body close-up focusing on her captivating eyes. The image adopts a macro photography style, high-definition, imaginative, real-person photo shoot, emphasizing detail and realism. The composition uses a close-up perspective, with the beauty at the center of the frame, her eyes dominating the position, and the background blurred to highlight the deep charm of her eyes. Mysterious cold light shines diagonally from above, creating a cold and stern blue atmosphere, with soft and concentrated light to enhance the charm and mystery of her eyes. f/2.8 aperture, 100mm macro lens, shallow depth of field, 8K resolution.

Prompt: A cute pet cat displayed in a 3x3 grid on a clean, bright off-white solid background, showcasing nine Mid-Autumn Festival-themed poses:1. Wearing a small maple leaf hair clip, sticking out its tongue to lick mooncake crumbs on its nose, with a mischievous expression.2. Wearing a caramel-colored small sweater (with exquisite jade rabbit embroidery), sitting upright, holding a mini Chinese lantern with its front paws.

Final Thoughts
HunyuanImage-3.0 elevates text-to-image generation from simply functional to genuinely intelligent and professional-grade. With WaveSpeedAI acceleration, its advancements are practical too — they are quick, deployable, and cost-efficient.
Together, HunyuanImage-3.0 and WaveSpeedAI are transforming the future of multimodal creation: smarter, faster, and more accessible!
Additionally, you can reach us on social media below.
© 2025 WaveSpeedAI. All rights reserved.