WaveSpeedAI X DataCrunch: FLUX Real-Time Image Inference on B200

WaveSpeedAI has teamed up with European GPU cloud provider DataCrunch to achieve a breakthrough in generative image and video model deployment. By optimizing the open-weight FLUX-dev model on DataCrunch’s cutting-edge NVIDIA B200 GPU, our collaboration delivers up to 6× faster image inference compared to industry-standard baselines.
In this post, we provide a technical overview of the FLUX-dev model and the B200 GPU, discuss the challenges of scaling FLUX-dev with standard inference stacks, and share benchmark results demonstrating how WaveSpeedAI’s proprietary framework significantly improves latency and cost-efficiency. Enterprise ML teams will learn how this WaveSpeedAI + DataCrunch solution translates to faster API responses and significantly reduced cost per image – empowering real-world AI applications. (WaveSpeedAI was founded by Zeyi Cheng, who leads our mission to accelerate generative AI inference.)
This blog is cross-posted to DataCrunch blog.
FLUX-Dev: SOTA image generation model
FLUX-dev is a state-of-the-art (SOTA) open-source image generation model capable of text-to-image and image-to-image generation. Its capabilities include good world understanding and prompt adherence (thanks to the T5 text encoder), style diversity, complex scene semantics and composition understanding. The model output quality is comparable to or can surpass popular close-source models like Midjourney v6.0, DALL·E 3 (HD), and SD3-Ultra. FLUX-dev has rapidly become the most popular image generation model in the open-source community, setting a new benchmark for quality, versatility, and prompt alignment.
FLUX-dev uses flow matching, and its model architecture is based on a hybrid architecture of multimodal and parallel diffusion transformer blocks. The architecture has 12B parameters, approximately 33 GB fp16/bf16. Therefore, FLUX-dev is computationally demanding with this large parameter count and iterative diffusion process. Efficient inference is essential for large-scale inference scenarios where user experience is crucial.
NVIDIA’s Blackwell GPU architecture: B200
Blackwell architecture includes new features such as 5th-generation tensor cores (fp8, fp4), Tensor Memory (TMEM) and CTA pairs (2 CTA).
-
TMEM: Tensor Memory is a new on-chip memory level, augmenting the traditional hierarchy of registers, shared memory (L1/SMEM), and global memory. In Hopper (e.g. H100), on-chip data was managed via registers (per thread) and shared memory (per thread block or CTA), with high-speed transfers via the Tensor Memory Accelerator (TMA) into shared memory. Blackwell retains those but adds TMEM as an extra 256 KB of SRAM per SM dedicated to tensor-core operations. TMEM does not fundamentally change how you write CUDA kernels (the logical algorithm is the same) but adds new tools to optimize data flow (see ThunderKittens Now Optimized for NVIDIA Blackwell GPUs).
-
2CTA (CTA Pairs) and Cluster Cooperation: Blackwell also introduces CTA pairs as a way to tightly couple two CTAs on the same SM. A CTA pair is essentially a cluster of size 2 (two thread blocks scheduled concurrently on one SM with special sync abilities). While Hopper allows up to 8 or 16 CTAs in a cluster to share data via DSM, Blackwell’s CTA pair enables them to use the tensor cores on common data collectively. In fact, the Blackwell PTX model allows two CTAs to execute tensor core instructions that access each other’s TMEM.
-
5th-generation tensor cores (fp8, fp4): The tensor cores in the B200 are notably larger and ~2–2.5x faster than the tensor cores in the H100. High tensor core utilization is critical for achieving major new-generation hardware speedups (see Benchmarking and Dissecting the Nvidia Hopper GPU Architecture).
Performance numbers without sparsity
| Technical Specifications | ||
|---|---|---|
| H100 SXM | HGX B200 | |
| FP16/BF16 | 0.989 PFLOPS | 2.25 PFLOPS |
| INT8 | 1.979 PFLOPS | 4.5 PFLOPS |
| FP8 | 1.979 PFLOPS | 4.5 PFLOPS |
| FP4 | NaN | 9 PFLOPS |
| GPU Memory | 80 GB HBM3 | 180GB HBM3E |
| GPU Memory Bandwidth | 3.35 TB/s | 7.7TB/s |
| NVLink bandwidth per GPU | 900GB/s | 1,800GB/s |
Operator level micro-benchmarking of GEMM and attention shows the following:
- BF16 and FP8 cuBLAS, CUTLASS GEMM kernels: up to 2x faster than cuBLAS GEMMs on H100;
- Attention: cuDNN speed is 2x faster than FA3 on H100.
The benchmarking results suggest that the B200 is exceptionally well-suited for large-scale AI workloads, especially generative models requiring high memory throughput and dense computing.
Challenges with Standard Inference Stacks
Running FLUX-dev on typical inference pipelines (e.g., PyTorch + Hugging Face Diffusers), even on high-end GPUs like H100, presents several challenges:
- High latency per image due to CPU-GPU overhead and lack of kernel fusion;
- Suboptimal GPU utilization and idle tensor cores;
- Memory and bandwidth bottlenecks during iterative diffusion steps.
The optimization objectives of serving large-scale and cheap inference are higher throughput and lower latency, reducing the image generation cost.
WaveSpeedAI’s Proprietary Inference Framework
WaveSpeedAI addresses these bottlenecks with a proprietary framework purpose-built for generative inference. Developed by founder Zeyi Cheng, this framework is our in-house high-performance inference engine optimized specifically for state-of-the-art diffusion transformer models such as FLUX-dev and Wan 2.1. Key innovations in the inference engine include:
- End-to-end GPU execution eliminating CPU bottlenecks;
- Custom CUDA kernels and kernel fusion for optimized execution;
- Advanced quantization and mixed precision (BF16/FP8) using the Blackwell Transformer Engine while maintaining the highest precision;
- Optimized memory planning and preallocation;
- Latency-first scheduling mechanisms that prioritize speed over batching depth.
Our inference engine follows an HW-SW co-design, fully utilizing the B200’s compute and memory capacity. It represents a significant leap forward in AI model serving, allowing us to deliver ultra-low latency and high-efficiency inference at the production scale.
We decompose the problem of efficient AI inference into multiple dimensions, like quantization, kernel optimizations, distributed inference (see ParaAttention) and algorithmic efficiency using DiT caching — some images require fewer denoising steps to attain a reasonable quality than others (e.g. AdaCache).
We decompose the problem of efficient AI inference into multiple dimensions, like quantization, compiler level with kernel optimizations, distributed inference (see ParaAttention) and algorithmic efficiency using DiT caching — some images require fewer denoising steps to attain a reasonable quality than others (e.g. AdaCache).
We evaluate how these optimizations impact output quality, prioritizing lossless vs. loosely optimizations. That is, we do not apply optimization that could significantly reduce model capabilities or completely collapse visible output quality, like text rendering and scene semantics.
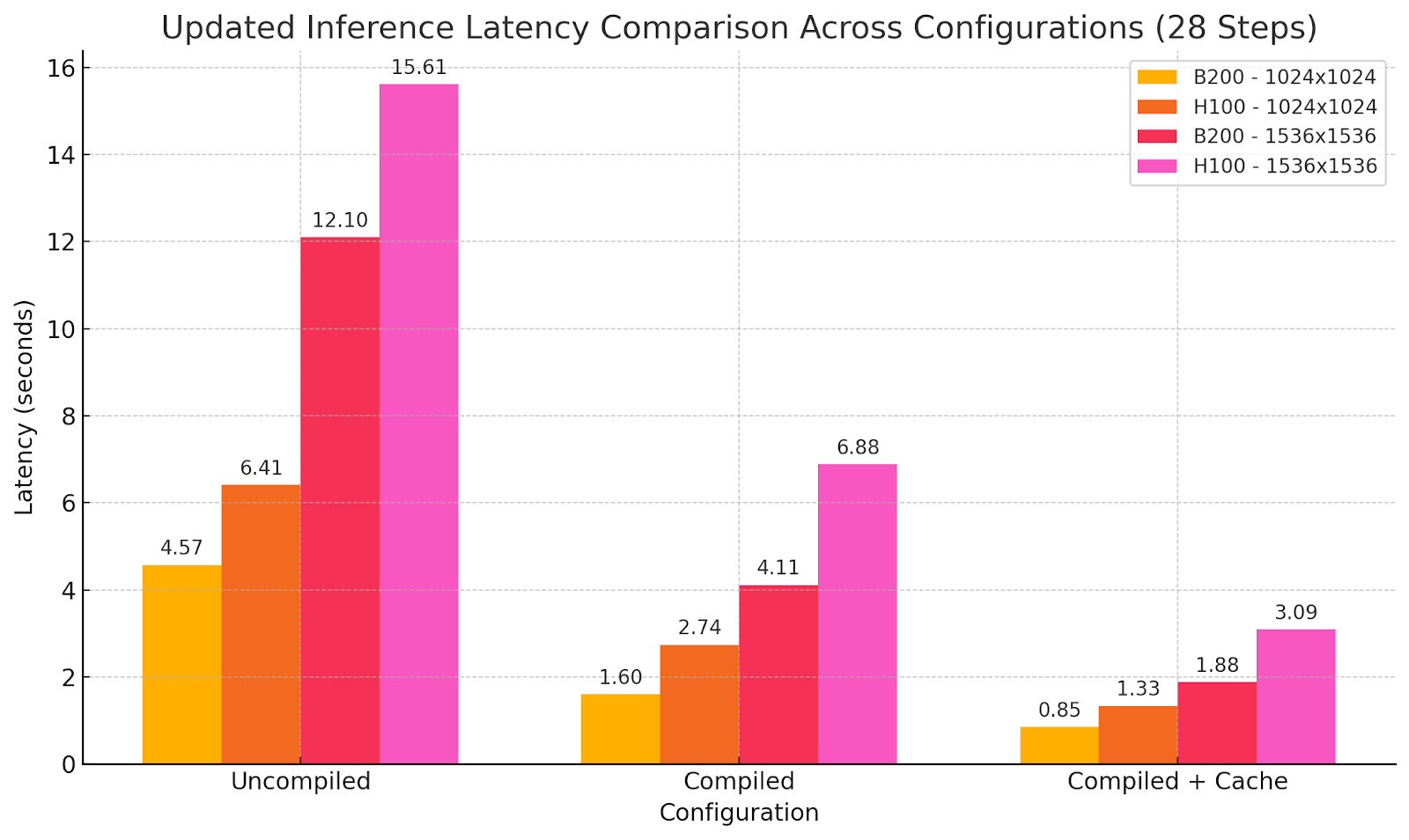
Benchmark: WaveSpeedAI on B200 vs. H100 Baseline
Model outputs using different optimizations settings:

Prompt: photograph of an alternative female with an orange bandana, light brown long hair, clear frame glasses, septum piecing [sic], beige overalls hanging off one shoulder, a white tube top underneath, she is sitting in her apartment on a bohemian rug, in the style of a vogue magazine shoot
Implications
The performance improvements translate into:
- AI algorithm design (e.g. DiT activation caching) and system optimization, using GPU architecture-tuned kernels, for better HW utilization;
- Reduced inference latency leading to new possibilities (e.g. Test-Time Compute in diffusion models);
- Lower cost per image due to improved efficiency and reduced hardware utilisation.
We have achieved B200 equal H100 cost-performance ratio but half the generation latency. Thus, the cost per generation doesn’t increase while now enabling new real-time possibilities without sacrificing model capabilities. Sometimes more isn’t more but different, and here we have achieved a new stage of performance, providing a new level of user experience in image generation using SOTA models.
This enables responsive, creative tools, scalable content platforms, and sustainable cost structures for generative AI at scale.
Conclusion and Next Steps
The FLUX-dev using B200 deployment demonstrates what is possible when world-class hardware meets best-in-class software. We are pushing the frontiers of inference speed and efficiency at WaveSpeedAI, founded by Zeyi Cheng — creator of stable-fast, ParaAttention, and our in-house inference engine. In the next releases, we will focus on efficient video generation inference and how to achieve close to real-time inference. Our partnership with DataCrunch represents an opportunity to access cutting-edge GPUs like B200 and the upcoming NVIDIA GB200 NVL72 (Pre-order NVL72 GB200 clusters from DataCrunch) while co-developing a critical inference infrastructure stack.”
Get Started Today:
- WavepSpeedAI Website
- WaveSpeedAI All Models
- WaveSpeedAI API Documentation
- DataCrunch B200 on-demand/spot instances
Join us as we build the world’s fastest generative inference infrastructure.
© 2025 WaveSpeedAI. All rights reserved.
