WaveSpeed 배치 생성: 매일 1,000개 이상의 이미지 요청을 자신감 있게 실행

안녕하세요, 여러분! 저는 Dora입니다. 이것은 작은 불편함에서 시작되었습니다. 테스트를 위해 수백 개의 변형 이미지가 필요했는데, 일반적인 단일 요청 루프가 바퀴가 고정된 쇼핑카트를 밀고 가는 것처럼 느껴졌습니다. Batch Generation이 WaveSpeed에서 대량 작업을 처리할 수 있다는 말을 자주 들었습니다. 화려한 결과가 필요한 것은 아니었습니다. 그저 작업이 더 가벼워지기를 원했을 뿐입니다.
그래서 12월 말과 이번 주에 걸쳐 WaveSpeed에 간단한 배치 파이프라인을 설정하고 1,000개 이상의 이미지 요청을 실행하도록 했습니다. 거창한 것은 없었고, 안정적인 처리량, 명확한 상태, 그리고 깔끔한 재시도만 있었습니다. 아래는 제게 효과적이었던 구조, 방해가 되었던 부분, 그리고 제 주의가 다른 곳에 있을 때 비용과 오류가 증가하지 않도록 한 작은 선택들입니다.
배치 아키텍처 개요
Producer / Queue / Worker / Storage
의도적으로 각 부분을 단순하게 유지했습니다. 작은 producer 스크립트가 프롬프트와 메타데이터를 수집하고, 큐가 작업을 보유하며, 상태를 유지하지 않는 worker들이 WaveSpeed 이미지 API를 호출하고, 저장소가 결과를 저장합니다. 각 부분은 전체 시스템을 무너뜨리지 않고도 실패할 수 있습니다.
- Producer: 프롬프트와 이미지별 설정(모델, 크기, 시드)의 CSV를 읽습니다. 행당 하나의 작업을 멱등성 키와 소프트 마감일과 함께 큐에 씁니다.
- Queue: Redis Streams를 한 번 사용했고 RabbitMQ를 한 번 사용했습니다. 둘 다 작동했습니다. 이미 둘 중 하나를 실행하지 않는다면 Redis를 시작하는 것이 더 가볍습니다.
- Workers: 작업을 가져와서 WaveSpeed를 호출하고, 결과를 객체 저장소(저는 S3을 사용했음)에 쓰고, 상태를 업데이트하는 컨테이너화된 프로세스입니다. 상태를 유지하지 않으므로 확장은 손잡이이지, 재구축이 아닙니다.
- Storage: 이미지용 버킷 하나, JSON 메타데이터용 버킷 하나입니다. 날짜와 배치 ID별 간단한 폴더가 정리 상태를 유지합니다.
놀라웠던 점은 100개에서 1,200개 이미지로 확장할 때 코드가 거의 변하지 않았다는 것입니다. 대부분의 문제는 속도와 중복 방지에 관한 것이었고, 처리량이 아니었습니다.
간단한 아키텍처 다이어그램
제가 머리에 그렸던 그림입니다:
Producer → Queue → Workers → WaveSpeed API → Storage
↓ ↑
State DB ←────────→ Metrics/Alerts- State DB는 동일한 Redis 또는 가벼운 Postgres 테이블이 될 수 있습니다.
- Metrics는 오류율이나 비용이 이상할 때 경고를 피드합니다.
영리하지 않습니다. 그것이 바로 핵심입니다. API가 간헐적인 429/5xx를 반환할 때, 큐가 그것을 흡수합니다. worker가 실행 중간에 죽을 때, 다른 하나가 가시성 타임아웃 후에 이를 계속 진행합니다.
동시성 전략
안전한 병렬 처리 수준
제 실행에서 5개의 worker로 시작했고, 각각 2개의 in-flight 요청을 수행했습니다. 이것은 제한을 트리거하지 않으면서 안정적인 초당 8-10개 이미지를 제공했습니다. 동시 요청을 20개로 늘리는 것은 잠시 작동했지만, 재시도가 급증하는 것을 보았습니다. 최고의 설정은 가장 빠른 피크가 아니었고, 가장 평평한 평균이었습니다.
이것을 시도하려고 한다면: 큐가 증가하지 않도록 하는 가장 작은 worker 수를 찾으세요. 그런 다음 천천히 증가시키세요. 무언가를 만지기 전에 10-15분 동안 p95 지연 시간과 오류율을 확인하세요.
속도 제한 인식
WaveSpeed는 문서에서 속도 제한 지침을 발표하지만, 모델과 계정에 따라 제한이 여전히 다릅니다. 두 가지 안전장치를 추가했습니다:
- Client-side token bucket: 각 worker는 API를 호출하기 전에 토큰을 획득합니다. 토큰은 계획의 유효 RPS에서 보충됩니다. 모델을 변경할 때, 나는 보충을 조정했습니다.
- Backoff discipline: 429와 5xx는 jitter를 사용한 지수 백오프를 트리거하며, 30초에서 상한선입니다. 이것은 짧은 중단 후에 쇄도를 방지했습니다.
또한 각 작업에 모델 + 크기로 태그를 지정했으므로 필요할 때 모델별로 별도의 동시성 상한선을 설정할 수 있었습니다. 화려하지는 않지만, 작은 switch 문일 뿐인데, 이것은 국소적 핫스팟을 피하는 데 도움이 되었습니다.
재시도 및 멱등성
중복 이미지 방지
제 첫 배치에는 조용한 버그가 있었습니다. worker가 API 호출이 반환된 후, 저장소에 쓰기 전에 충돌했습니다. 큐가 작업을 재시도했고 저는 동일한 생성에 대해 두 번 비용을 지불했습니다. 즐겁지 않았습니다.
이를 방지하기 위해 저는 저장소 경로를 멱등성 키와 입력 해시에서 결정론적으로 만들었습니다. 재시도가 이미 쓰인 이미지를 발견하면, 그것은 단락되고 작업을 성공으로 표시합니다. 저렴한 수정, 큰 안도감입니다.
멱등성 키 구현
정규화된 프롬프트 + 모델 + 시드 + 크기 + 지도의 SHA-256을 사용했습니다. 그 해시는 다음이 됩니다:
- API 멱등성 키(SDK에 따라 헤더 또는 페이로드 필드로 전송됨)
- 저장소 파일명 접두사
- 작업의 데이터베이스 기본 키
WaveSpeed의 API가 멱등성 키를 존중하면(엔드포인트의 문서 확인), 동일한 키로 반복 호출하면 추가 비용 없이 동일한 결과를 반환합니다. 그렇지 않으면, 저장소 우선 확인이 여전히 두 번 비용을 지불하는 중복을 방지합니다.
실패한 작업 복구
모든 실패가 다른 시도를 받을 자격이 있는 것은 아닙니다. 저의 일반적인 규칙:
- 재시도: 429, 5xx, 네트워크 타임아웃, “모델 사용 중” 또는 일시적 저장소 오류
- 재시도하지 않기: 검증 오류, 누락된 매개변수 또는 명백히 잘못된 입력이 있는 4xx
5회 재시도를 지수 백오프로 제한합니다. 그 후, 작업은 오류 페이로드가 있는 dead-letter 큐에 도착합니다. 하루에 한 번, 나는 DLQ 작업을 정리합니다. 일부는 수정된 입력과 함께 다시 큐에 들어가고, 다른 것들은 메모와 함께 보관됩니다. 이것은 1,200개 이미지 실행에 대한 전체 실패율을 1.5% 미만으로 유지했습니다.
작업 상태 관리
상태: pending/running/success/failed
몇 가지 상태 형태를 시도했습니다. 가장 단순한 것이 고착되었습니다:
- pending: 큐에 들어감, 아직 worker에 의해 임차되지 않음
- running: worker에 의해 임차됨, 임차 만료 포함
- success: 이미지 및 메타데이터가 쓰임, 확인 통과
- failed: 터미널, 오류 코드 및 마지막 시도 타임스탬프 포함
두 개의 선택적 필드를 추가했는데, 그것이 효과를 발휘했습니다: attempt_count와 last_response_code입니다. 이것들은 대시보드를 더 읽기 쉽게 만들었고 디버깅을 덜 추측적이게 만들었습니다.
작업 타임아웃 처리
두 가지 타임아웃이 중요합니다:
- Lease timeout: worker가 실행 중간에 죽으면, 작업은 N초 후에 pending으로 돌아가야 합니다. 나는 120초를 사용했습니다.
- API timeout: WaveSpeed가 N초 내에 응답하지 않으면, 중단하고 백오프를 사용하여 재시도하세요. 나는 호출당 60초를 사용했습니다.
API가 느릴 때, 이 둘은 싸울 수 있습니다. 중복 작업을 피하기 위해, 나는 임차 만료 후에만 running → pending을 표시하고 worker의 하트비트가 멈출 때만 합니다. 하트비트는 단지 10초마다 Redis 해시 업데이트였습니다. 하트비트가 신선하면, 나는 임차를 연장했습니다.
모니터링 및 경고
오류율 추적
실행 중에 세 가지 숫자를 감시했습니다:
error_rate_5m: 실패한 시도의 5분 롤링 비율p95_latency: 모델별, 크기별retry_depth: 시도 ≥ 2인 작업 수
error_rate_5m > 5%가 10분 동안 지속되면, 자동으로 동시성을 반으로 줄이고 자신에게 메모를 보냅니다. 대부분의 스파이크는 수동 조정 없이 5분 내에 정착했습니다.
비용 스파이크 경고
비용은 증가할 수 있습니다. 저는 다음을 기록했습니다:
- cost_per_image: WaveSpeed에서 보고됨(이용 가능한 경우), 그렇지 않으면 계획에서 추정됨
- duplicate_prevented: 저장소 단락 횟수
- total_estimated_cost: 누적
cost_per_image가 지난 시간의 평균보다 30% 이상 증가하면, 나는 새로운 작업 수집을 일시 중지하고 큐를 비워 둡니다. 두 번, 이것은 청구서가 변하기 전에 의도하지 않은 매개변수 변경(더 큰 크기, 다른 모델)을 포착했습니다. 이와 같은 조용한 안전장치는 몇 줄의 코드의 가치가 있습니다.
참고 구현
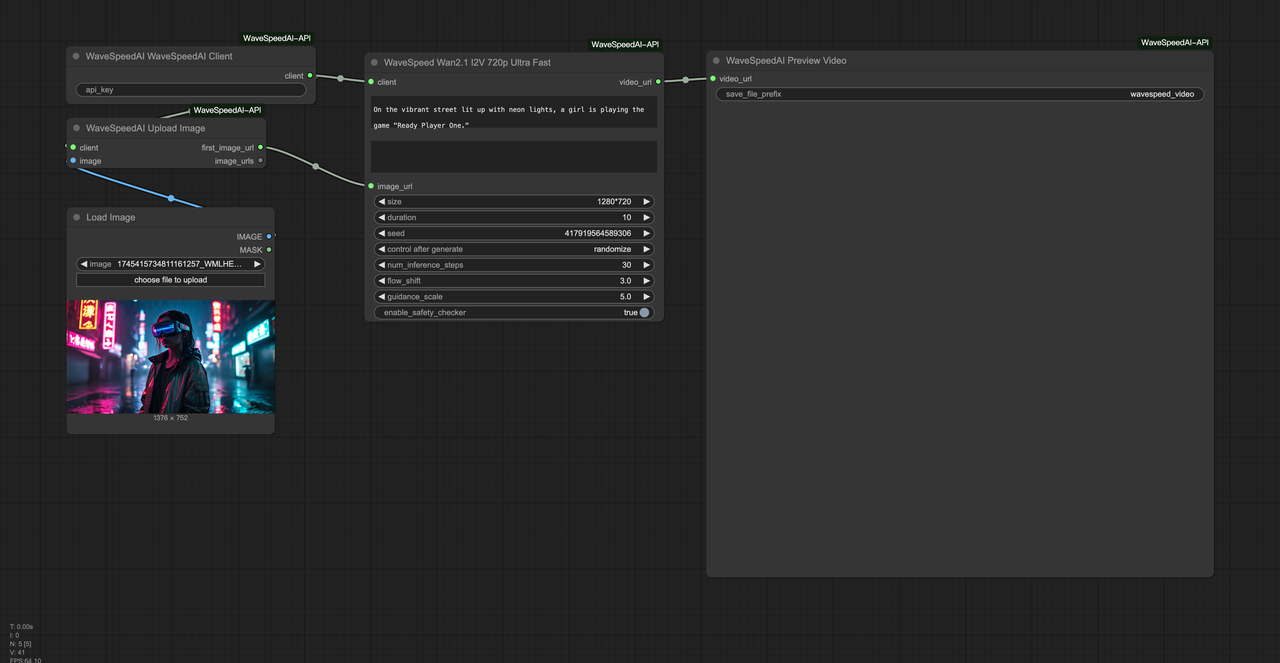
Python 의사 코드 아래는 내가 사용한 형태입니다. 완전한 코드가 아니라 뼈대일 뿐입니다:
# producer.py
for row in csv_rows:
key = hash_inputs(row)
job = { "id": key, "inputs": row, "deadline": now+6*3600 }
queue.push(job)
# worker.py
while True:
job = queue.lease(timeout=120)
if not job:
sleep(1)
continue
try:
record_heartbeat(job.id)
resp = wavespeed.generate_image(inputs=job.inputs, idempotency_key=job.id, timeout=60)
path = storage_path(job.id, job.inputs)
if not storage.exists(path):
storage.write(path, resp.image)
storage.write(path+'.json', resp.metadata)
mark_success(job.id)
except Retryable as e:
mark_retry(job.id, e)
backoff_sleep(job.attempt)
except Fatal as e:
mark_failed(job.id, e)
finally:
queue.release(job)Node.js 의사 코드
// producer.mjs
for (const row of rows) {
const key = hashInputs(row);
queue.push({ id: key, inputs: row, deadline: Date.now() + 6 * 3600e3 }); // 6 hours
}
// worker.mjs
while (true) {
const job = await queue.lease(120); // lease timeout in seconds
if (!job) { // 원래의 ".job" 개정됨
await delay(1000);
continue;
}
try {
await heartbeat(job.id);
const resp = await wavespeed.generateImage(
{ ...job.inputs, idempotencyKey: job.id },
{ timeout: 60000 } // 60 seconds
);
const path = makePath(job.id, job.inputs);
if (!(await storage.exists(path))) { // 원래의 ".(await ...)" 수정됨
await storage.write(path, resp.image);
await storage.write(path + '.json', resp.metadata);
}
await markSuccess(job.id);
} catch (e) {
if (isRetryable(e)) {
await markRetry(job.id, e);
} else {
await markFailed(job.id, e);
}
} finally {
await queue.release(job);
}
}설정 권장사항
- 작게 시작: 5-10개의 동시 요청, 그런 다음 천천히 증가시킵니다. 단순 처리량이 아닌
p95와error_rate_5m을 확인하세요. - 모델별 별도 설정: 동시성, 타임아웃 및 비용 예상은 모델 및 크기에 따라 변경됩니다.
- 어디서나 멱등성: 요청의 키, 결정론적 저장소 경로 및 동일한 값으로 키가 지정된 작업 테이블입니다.
- 하트비트 및 임차: 성가신 것처럼 보이지만, 유령 중복을 방지합니다.
- 간단한 대시보드: 6-8개 패널이면 충분합니다 — 큐 길이, 성공/분, 오류/분, p95, 재시도 깊이 및 비용.
이미 다른 곳에서 배치 작업을 실행하고 있다면, 이것이 친숙할 것 같습니다. WaveSpeed는 재사고가 필요하지 않았고, 단지 몇 가지 신중한 안전장치가 필요했습니다. 그것이 제가 원했던 것입니다.

제 실행에서 마지막 한 가지 주의 사항: 가장 부드러운 배치는 제가 거의 감시하지 않았던 것들이었습니다. 그것이 “설정 후 망각하기”였기 때문이 아니라, 시스템이 주의가 필요할 때를 알려주고 필요 없을 때는 조용했기 때문입니다. 그것이 올바른 종류의 속도처럼 느껴집니다.
당신은 어떻습니까? 최근에 WaveSpeed로 이미지를 배치 처리하고 있습니까? 동시성에 대한 당신의 최적값은 무엇입니까(저는 현재 8-10 정도로 일관되게 유지하고 있습니다)? 아니면 몰래 숨은 버그(중복 청구 같은)가 있었습니까? 저장소, 함정 또는 팁을 댓글로 공유하세요!
관련 기사

Seedance 2.0, WaveSpeedAI에 출시 예정: 네이티브 오디오가 포함된 ByteDance의 차세대 비디오 모델

Seedance 2.0 완벽 가이드: 멀티모달 비디오 생성

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: 최고의 비디오 생성 비교

Seedream 5.0-Preview 완벽 가이드: 지능형 이미지 생성

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 완벽한 비교
