GLM-4.7-Flash vs GLM-4.7: 어떤 모델이 당신의 프로젝트에 맞을까?

안녕하세요, 저는 Dora입니다. 이 말이 낯익다면, 당신만 그런 게 아닙니다. 저도 겪어봤어요: 빠르고 견고한 답변만 필요한 작은 반복 프롬프트들의 대기열을 바라보면서, 한편에는 복잡한 다단계 추론 작업들이 조용히 훨씬 더 큰 처리 능력을 요구하고 있는 상황 말입니다.
그래서 결국 큰 목소리로 질문했어요: 가볍고 번개 같이 빠른 GLM-4.7-Flash가 정말로 빛나는 곳은 어디이고, 더 무겁고 신중한 GLM-4.7을 가져와야 하는 곳은 어디일까요? 이것이 제가 찾아낸 솔직한 답입니다 - 실제 실행, 중요한 벤치마크, 그리고 일상적인 스택을 눈에 띄게 가볍게 만드는 조용한 목표에 바탕을 두고 있습니다. 만약 “이 경우에 어떤 모델을 써야 하지?”라고 한 번이라도 멈춘 적이 있다면, 이 글이 당신을 위한 것입니다.
30초 답변
속도와 낮은 비용이 당신의 주요 요소라면, GLM-4.7-Flash이 적절할 가능성이 높습니다. 만약 당신의 작업이 추론 깊이, 도구 사용, 또는 더 높은 충실도의 결과물에 의존한다면, GLM-4.7이 더 안정적인 선택입니다. 나머지는 지연시간 예산, 컨텍스트 크기, 그리고 압력 속에서 프롬프트가 어떻게 동작하는지에 대한 세부사항입니다.
Flash를 선택해야 할 경우…
Flash는 “더 약한” 게 아닙니다 - 그냥 자신이 잘하는 게 뭔지 매우 솔직할 뿐입니다.
- 많은 작은 작업들을 배치하는 경우: 요약, 태그, 초안, 빠른 변환.
- 지연시간이 마지막 10% 품질을 짜내는 것보다 더 중요한 경우.
- 실험 중이거나, 프로토타이핑 중이거나, 즉시 반응해야 하는 UI 상호작용을 구축하는 경우.
- 긴 추론 단계에서 가끔의 흔들림이 당신을 탈선시키지 않을 경우.
- 더 저렴한 기본 모델을 원하고, 필요할 때만 GLM-4.7로 확대할 수 있는 경우.
GLM-4.7을 선택해야 할 경우…
이것이 “실패하면 안 되는” 모델입니다.
- 코드 신뢰성, 다단계 추론, 또는 도구 사용 정확도를 신경 쓸 경우.
- 프롬프트가 길거나, 지시사항이 엄격하거나, 결과물이 일관성이 있어야 할 경우.
- 평가기, 테스트, 또는 한 번의 실수가 비용이 큰 워크플로우를 실행할 경우.
- 코딩 및 장문맥 작업에서 더 강력한 결과가 필요한 경우.
- 더 나은 결과를 위해 더 높은 비용과 조금 더 많은 지연시간을 감수할 수 있는 경우.
아키텍처 차이점
 저는 스포츠처럼 매개변수 개수를 쫓지는 않지만, 아키텍처는 동작에 대해 많은 것을 설명합니다: 왜 한 모델은 빠르게 느껴지고 다른 하나는 신중하게 느껴지는지를 말입니다.
저는 스포츠처럼 매개변수 개수를 쫓지는 않지만, 아키텍처는 동작에 대해 많은 것을 설명합니다: 왜 한 모델은 빠르게 느껴지고 다른 하나는 신중하게 느껴지는지를 말입니다.
매개변수 개수 및 활성 전문가
GLM-4.7은 더 큰 백본을 실행하는 것으로 보이며, (공개 정보에 따르면) 추론을 우선시하는 전문가 라우팅을 사용합니다. Flash는 처리량에 최적화되어 있으며, 더 가벼운 라우팅, 토큰당 더 적은 활성 전문가, 그리고 공격적인 효율성 설정을 가지고 있습니다. 실제로는 다음과 같이 나타나는 경향이 있습니다:
- Flash: 토큰당 더 낮은 계산, 빠른 첫 토큰 시간, 하지만 스트레스 아래에서 추론 체인을 놓칠 수 있습니다.
- GLM-4.7: 토큰당 더 많은 계산, 더 안정적인 추론 경로, 더 나은 도구 호출 선택.
제공자 다이어그램을 훑어보면, 혼합 전문가 (MoE)와 활성화 희소성의 힌트를 볼 수 있습니다. 정확한 숫자는 버전에 따라 변하므로, 저는 이를 절대값이 아닌 방향 지시로 취급합니다. 큰 아이디어: Flash는 토큰당 더 적은 “생각”을 소비하므로 더 빨리 이동합니다; GLM-4.7은 더 길게 생각하고 엣지 케이스에 덜 걸립니다.
컨텍스트 윈도우 및 출력 제한
두 가지 실질적인 질문이 헤드라인 컨텍스트 숫자보다 더 중요합니다:
- 긴 프롬프트 깊숙이 들어갈수록 품질이 어디까지 유지되는가?
- 출력이 길어질 때, 모델이 맥락을 잃는가?
Flash는 보통 건전한 컨텍스트 윈도우를 광고하지만, 매우 긴 프롬프트나 촘촘한 지시사항을 사용할 때 품질이 일찍 떨어지는 경향이 있습니다. GLM-4.7은 긴 컨텍스트 깊숙이 일관성을 유지하고, 긴 출력에서 구조에 대해 더 복종합니다. 만약 당신이 지식 기반을 집어넣는 중이라면, GLM-4.7이 더 안전한 기본값입니다. 만약 당신이 입력을 청크하거나 검색을 사용해서 프롬프트를 슬림하게 유지한다면, Flash는 종종 충분합니다 - 그리고 훨씬 더 빠릅니다.
벤치마크 비교
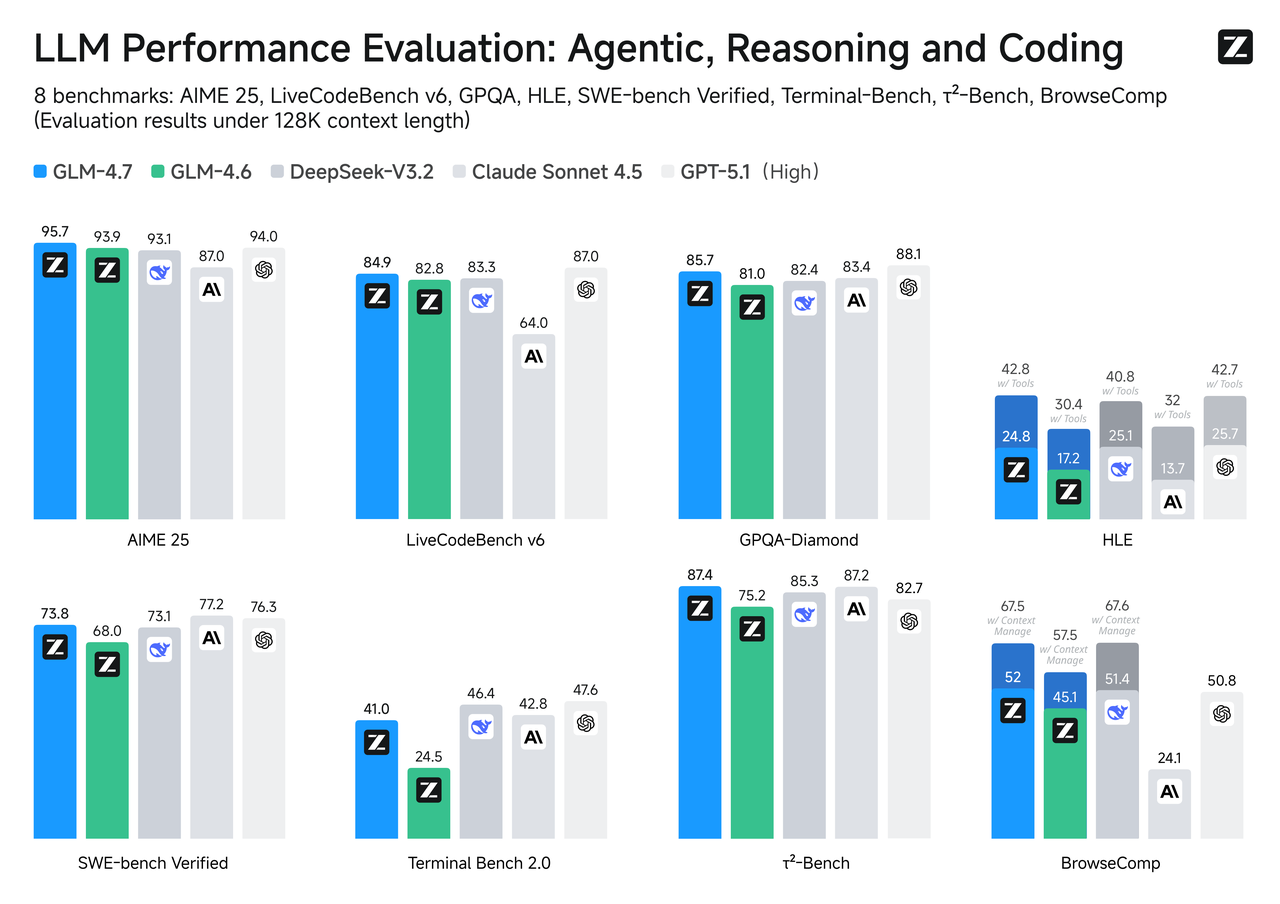 벤치마크가 전부는 아니지만, 특히 당신의 사용 사례가 작업과 일치할 때 유용한 나침반입니다.
벤치마크가 전부는 아니지만, 특히 당신의 사용 사례가 작업과 일치할 때 유용한 나침반입니다.
SWE-벤치 확인
실제로 컴파일되고 테스트를 통과해야 하는 코드 변경의 경우, GLM-4.7은 Flash 형제보다 더 높은 순위를 기록하는 경향이 있습니다. 그것은 추론 깊이와 도구 사용을 위해 조정된 모델에서 기대할 수 있는 것과 일치합니다. Flash는 수정 사항을 작성하고 코드를 잘 설명할 수 있지만, 패치가 여러 파일에 걸쳐 몇 가지 조정된 편집이 필요할 때, GLM-4.7이 단계를 놓치지 않고 체인을 따를 가능성이 더 높습니다.
만약 당신의 파이프라인이 자동 PR이나 수리 루프를 포함한다면, 작은 샘플로 먼저 건전성 검사를 하는 것이 가치 있습니다. 차이는 멀티홉 문제에서 싱글 파일 조정보다 더 많이 나타납니다.
LiveCodeBench / τ²-벤치
라이브 또는 시간 회전 코딩 벤치마크에서, GLM-4.7은 더 무거운 추론 예산이 주어졌을 때 일반적으로 상위 계층에 더 가깝게 추적합니다. 속도에 최적화된 Flash는 약간 낮은 계층에 앉지만, 빠르게 응답합니다. 만약 당신의 제품이 상호작용 속도보다 코드 합성 품질에 더 의존한다면, GLM-4.7이 보수적인 선택입니다. 만약 코드가 권고적이고 (어차피 당신이 검토할 테니) 반응성이 중요하다면, Flash가 올바른 균형일 수 있습니다.
속도 및 지연시간
여기가 분할이 가장 명확하게 느껴지는 곳입니다. Flash는 종종 첫 토큰을 눈에 띄게 더 빠르게 반환하며, 마지막 토큰까지의 총 시간도 짧은 그리고 중간 길이의 출력에서 낮게 유지됩니다. 만약 당신이 많은 작은 호출을 실행하거나 UI로 스트리밍한다면 이것이 누적됩니다.
GLM-4.7은 더 느리게 시작하고 더 무겁게 실행되지만, 긴 생성이나 복잡한 도구 호출 시퀀스에서 더 안정적입니다. 더 적은 정지, 더 적은 이상한 우회로, 그리고 함수 스키마에 대한 더 나은 준수를 볼 것입니다.
만약 당신이 시스템을 구축하고 있다면:
- 고트래픽 UX 순간에 Flash를 사용하세요: 자동완성, 빠른 요약, 인라인 도움말.
- 느린 차선에 GLM-4.7을 사용하세요: 평가기, 코드 작업, 정책 확인, 최종 패스.
간단한 라우팅 규칙이 종종 비용을 충당합니다: Flash로 시작하고, 신뢰도가 떨어지거나 임계값을 초과할 때 GLM-4.7로 확대합니다. 규칙이 결정하도록 하세요, 당신이 결정하지 말고.
가격 분석
가격은 지역과 제공자에 따라 변하므로, 저는 숫자를 변화하는 목표로 취급하고 구조를 안정적으로 유지합니다.
Flash 무료 계층 대 GLM-4.7 종량제
-
Flash: 많은 플랫폼이 Flash 같은 모델에 대해 무료 또는 저비용 계층을 노출하며, 플래그십 모델과 비교할 때 넉넉한 속도 제한이 있습니다. 프로토타이핑, 배경 작업, UI 개선에 좋습니다.
-
GLM-4.7: 보통 더 높은 요금으로 토큰당 청구됩니다. 심각한 작업에서 더 나은 비용-가치, 하지만 기본으로 남겨두면 과비용하기 쉽습니다.
 실질적인 팁:
실질적인 팁: -
기본적으로 출력 토큰을 제한하세요. 필요한 라우트에서만 제한을 올리세요.
-
검색을 사용해서 프롬프트를 짧게 유지하세요: 전체 코퍼스를 윈도우에 붓지 마세요.
-
결정론적 하위 결과(정규식 맵, 스키마 스니펫, 몇 가지 샷 블록)를 캐시하세요, 그래서 다시 비용을 내지 않아도 됩니다.
-
라우트당 토큰 비용을 기록하세요. 당신이 실제로 읽을 리포트는 당신의 주간 워크플로우에 앉아있는 것이지, 차트가 가장 많은 것이 아닙니다.
의심스러울 때, 저렴하게 시작하고, 측정하고, 그 다음 승격하세요. 확대가 낙관주의를 이깁니다.
사용 사례별로 선택하세요
제가 이들을 배치할 방법은 다음과 같습니다 - 목표가 더 적은 골치일 때:
- 높은 회전 콘텐츠 작업 (스니펫, 주제 줄, 메타데이터): Flash. 승리는 낮은 비용에서의 처리량과 일관성입니다.
- 지원 매크로 및 빠른 심사: Flash 먼저, 그 다음 탐지가 복잡성이나 정책 위험을 플래그할 때 GLM-4.7로 확대합니다.
- 연구 노트, 합성, 구조화된 요약: 스키밍의 경우 Flash; 소스에 충실하고 잘 스캐폴드된 패스의 경우 GLM-4.7.
- 코드 지원: 설명과 “이게 뭐 하는 거야?”의 경우 Flash; 멀티 파일 편집, 마이그레이션, 테스트 인식 변경의 경우 GLM-4.7.
- 데이터 정리 및 변환: 간단한 매핑의 경우 Flash는 좋습니다; 엄격한 스키마, 검증, 다단계 조인의 경우 GLM-4.7.
- 에이전트 및 도구 사용: GLM-4.7. 더 신뢰할 수 있는 함수 인수와 더 적은 재시도를 얻을 것입니다.
- 긴 문맥 읽기 또는 문서 기반 QA: 윈도우를 밀어붙이는 경우 GLM-4.7; 청크를 슬림하게 유지하는 경우 Flash.
몇 가지 필드 노트는 가까이 유지합니다:
- 짧은 프롬프트는 차이를 숨깁니다. 간격이 지시사항이 촘촘하거나 출력이 구조를 따라야 할 때 나타납니다.
- 라우팅이 도움이 됩니다. 간단한 규칙도, “프롬프트 > N 토큰이 아닌 한 Flash, 그러면 GLM-4.7”, 드라마 없이 돈을 절약합니다.
- 가드레일은 반복 작업에 모델 선택보다 더 중요합니다. 검증, 재시도, 그리고 작은 체커가 다운스트림 혼란을 방지합니다.
- 속도를 숭배하지 마세요. 1초 미만이 대부분의 사용자에게 “즉시”로 느껴집니다. 그 이후로는, 100ms를 깎아내는 것보다 안정적인 동작이 낫습니다.
왜 이것이 중요한가: 도구들은 정신 부담을 줄일 때 잘 나이 들어갑니다. Flash는 작은 것들을 가볍게 유지합니다. GLM-4.7은 그들을 떨어뜨리지 않고 무거운 상자를 운반합니다. 대부분의 스택은 둘 다 필요합니다.
만약 당신이 확실하지 않다면, Flash를 기본값으로 시작하고 GLM-4.7을 위한 명확한 차선을 만들세요. 기분이 아니라 라우트가 결정하게 하세요. 당신의 경험은 다를 수 있고, 그건 괜찮습니다.
저는 여전히, 조용한 날에, 이 분할이 결정 피로를 어떻게 감소시키는지 주목합니다. 화려한 게 없습니다 - 그냥 더 적은 골치입니다.
제가 실제로 이 분할을 실행하는 방법
 빠른 작업을 Flash로 라우팅하고, 더 무거운 작업을 GLM-4.7로 확대해야 할 때, 스크립트를 감시하지 않으면서, 저는 WaveSpeed를 사용합니다 - 우리 자신의 플랫폼입니다.
빠른 작업을 Flash로 라우팅하고, 더 무거운 작업을 GLM-4.7로 확대해야 할 때, 스크립트를 감시하지 않으면서, 저는 WaveSpeed를 사용합니다 - 우리 자신의 플랫폼입니다.
우리는 모델 전환, 동시성, 그리고 배치 호출을 깔끔하게 다루기 위해 그것을 구축했으므로, “Flash 먼저, 필요할 때 확대” 패턴은 취약하지 않고 간단하게 유지됩니다.
만약 당신이 많은 작은 호출을 실행 중이고, 라우팅 로직이 유지할 또 다른 것이 되기를 원하지 않는다면, Wavespeed를 시도해보세요!
자주 묻는 질문: GLM-4.7-Flash 대 GLM-4.7
1. GLM-4.7-Flash와 GLM-4.7 사이의 주요 차이점은 무엇인가요?
GLM-4.7-Flash는 GLM-4.7의 가볍고 최적화된 변형입니다. 활성 전문가의 수를 줄이고, 라우팅을 단순화하고, 효율성 조정을 적용하여 더 빠른 추론과 낮은 비용을 달성합니다. GLM-4.7은 더 큰 백본과 더 강력한 추론 능력을 유지하며, 복잡한 다단계 추론, 장문맥 일관성, 그리고 정확한 도구 호출에서 우수합니다.
간단히: Flash는 일부 지능을 속도로 교환합니다; GLM-4.7은 깊이와 신뢰성을 우선시합니다.
2. 어느 모델이 더 빠르며, 속도 차이가 가장 눈에 띄는 시나리오는 어느 것인가요?
GLM-4.7-Flash는 현저히 낮은 첫 토큰 시간(TTFT)과 토큰당 지연시간을 가집니다. 실시간 UI 상호작용, 콘텐츠 요약, 메타데이터 생성, 빠른 프로토타이핑과 같은 높은 처리량, 낮은 지연시간 사용 사례에서 빛납니다.
GLM-4.7은 더 높은 시작 오버헤드와 더 무거운 계산을 가지지만, 긴 출력이나 복잡한 도구 호출 시퀀스에서는 더 안정적입니다. 실제로는, Flash는 짧은에서 중간 길이 출력(500 토큰 미만)에서 눈에 띄게 더 빠릅니다.
3. 어느 모델이 지능과 추론에서 더 강한가요?
GLM-4.7은 다단계 추론, 코드 신뢰성, 도구 사용, 그리고 장문맥 작업에서 Flash를 능가합니다. 예제:
- SWE-벤치 확인: GLM-4.7은 멀티 파일 코드 편집과 조정된 패치에서 주도합니다.
- LiveCodeBench / τ²-벤치: GLM-4.7은 특히 깊은 추론 시나리오에서 더 높은 품질의 코드를 제공합니다.
Flash는 인간의 검토를 용인하는 싱글 파일 편집이나 보조 작업에 적합하지만, 긴 추론 체인이나 촘촘한 프롬프트에서는 더 빠르게 악화됩니다.
4. 컨텍스트 길이와 출력 제한은 어떻게 비교되나요?
두 모델 모두 유사한 컨텍스트 윈도우를 공유하지만, GLM-4.7은 매우 긴 컨텍스트(>32k 토큰)나 촘촘한 프롬프트에서 더 나은 일관성과 지시 준수를 유지합니다. Flash는 극단적인 프롬프트 길이나 밀도 아래에서 더 빠르게 악화됩니다 - 최적의 결과를 위해 청킹이나 RAG와 쌍을 이루세요.
5. 가격 및 비용 관리에 따라 어떻게 선택해야 하나요?
GLM-4.7-Flash는 보통 더 높은 무료 할당량과 더 낮은(또는 심지어 0) 토큰당 가격을 제공하므로, 프로토타이핑, 배경 작업, 그리고 높은 용량 저위험 호출에 이상적입니다. GLM-4.7은 더 높은 토큰당 비용을 가지지만, 중요한 작업에서 더 나은 가치를 제공합니다.
권고: Flash를 기본값으로 설정하고, 복잡한 작업을 위해 GLM-4.7로 확대하고, 항상 과비용을 방지하기 위해 토큰 제한과 캐싱을 설정하세요.
관련 기사

Seedance 2.0, WaveSpeedAI에 출시 예정: 네이티브 오디오가 포함된 ByteDance의 차세대 비디오 모델

Seedance 2.0 완벽 가이드: 멀티모달 비디오 생성

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: 최고의 비디오 생성 비교

Seedream 5.0-Preview 완벽 가이드: 지능형 이미지 생성

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 완벽한 비교
