GLM-4.7-Flash를 로컬에서 실행하기: Ollama, Mac 및 Windows 설정

안녕하세요, 저는 Dora입니다. 며칠 전, 작은 불편함이 저를 이 상황으로 몰아냈습니다: 작은 초안 작업을 위해 원격 완료를 계속 기다리고 있었습니다. 몇 분이 아니라, 이메일로 표류하고 맥락을 잃기에 충분한 정도의 지연이었습니다. 지난주(2026년 1월), 저는 GLM-4.7-Flash를 로컬에서 실행해보기로 했습니다. 이 몇 초를 줄이는 것이 실제로 더 명확하게 생각하는 데 도움이 될지 확인하기 위해서였습니다.
간단히 말해서: 도움이 되었지만, 화려한 이유 때문은 아니었습니다. GLM-4.7-Flash는 헤드라인 모델보다 안정적인 어시스턴트처럼 느껴졌습니다. 흐름을 유지할 수 있을 만큼 충분히 빠르고, 노트북에서 실행할 수 있을 만큼 가벼웠습니다. 무엇이 작동했는지, 어디서 막혔는지, 그리고 좋은 방식으로 지루함을 유지한 설정을 공유하겠습니다.
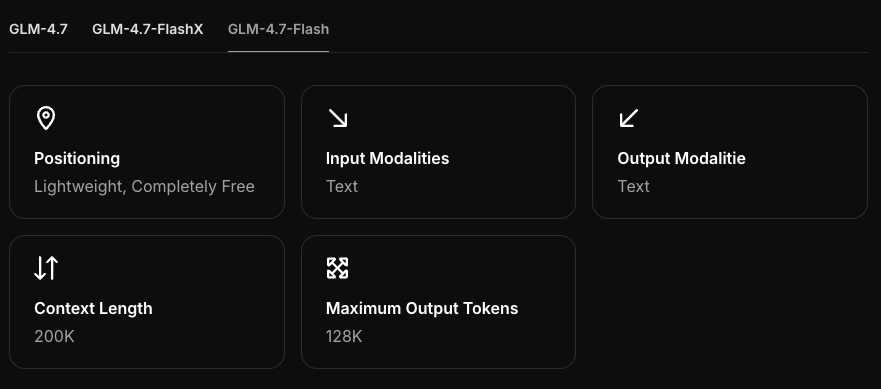
하드웨어 요구사항
최소 GPU / RAM
저는 GLM-4.7-Flash를 세 대의 컴퓨터에서 실행했습니다:
- MacBook Pro M3 Pro (12코어 CPU / 18코어 GPU, 36GB RAM)
- Mac mini M2 (24GB 통합 메모리)
- RTX 4090이 있는 Windows 데스크톱 (24GB VRAM)
이러한 테스트를 통해 실질적인 최소 사양:
- CPU만 사용 (Mac/Windows/Linux): 16GB 시스템 메모리로 충분하고, 32GB가 더 낫습니다. 첫 토큰이 느릴 것으로 예상하세요.
- Apple Silicon (Metal): 4비트/5비트 양자화와 적절한 컨텍스트(2~4K)를 사용하면 16GB 통합 메모리가 사용 가능합니다. 8GB는 불충분했습니다.
- NVIDIA: 4비트 양자화의 경우 최소 8~12GB VRAM이 필요합니다. 16GB 이상이 더 안정적입니다.
GLM-4.7-Flash는 중간 크기 모델처럼 느껴집니다(1012B 매개변수 이하라고 생각하세요). 4비트 양자화에서는 대개 약 56GB의 장치 메모리와 KV 캐시가 필요합니다. 긴 컨텍스트나 많은 병렬 프롬프트를 사용하면 메모리 사용량이 증가합니다.
권장 사양
항상 반응형 느낌을 원한다면:
- Apple Silicon: M3 이상 24
36GB 통합 메모리: 컨텍스트 48K 유지. - NVIDIA: 24GB VRAM (예: 3090/4090)은 더 높은 컨텍스트와 동시성을 위한 여유를 제공합니다.
- 스토리지: 빠른 SSD: 모델이 더 빨리 로드되고 스왑이 적게 발생합니다.
메모리 압박이 발생하면 모델이 “빠른” 느낌을 잃는 것을 알았습니다. 페이지 아웃이나 VRAM 유출은 미묘한 끊김을 추가하여 흐름을 방해합니다. 약간의 추가 여유는 큰 도움이 됩니다.
Ollama 설정
저는 Ollama를 사용했습니다. 로컬 실행을 간단하고 일관되게 유지하기 때문입니다.
Ollama 0.14.3+ 설치
- macOS: brew install ollama (또는 brew upgrade ollama로 업데이트).
- Windows: Ollama 사이트의 공식 설치 프로그램을 사용하세요.

- Linux: 문서의 curl 스크립트를 따르세요.
이 테스트 기준(2026년 1월) 0.14.3을 사용 중입니다. 최신 버전은 때때로 기본 백엔드나 양자화 동작을 변경하므로, 점프할 이유가 있을 때까지 저에게 안정적인 버전을 고수합니다.
GLM-4.7-Flash 다운로드 및 실행
두 가지 경로가 작동했습니다:
-
Ollama 라이브러리에 공식 GLM-4.7-Flash 빌드가 포함된 경우:
- ollama pull glm-4.7-flash
- ollama run glm-4.7-flash
-
표시되지 않는 경우 (한 대의 컴퓨터에서 발생):
- GLM-4.7-Flash의 알려진 GGUF 또는 호환 아티팩트를 가리키는 Modelfile을 만듭니다.
- 예시 Modelfile (단순화됨):
- FROM ./glm-4.7-flash-q4.gguf
- 필요한 경우에만 프롬프트 템플릿을 추가합니다: 저는 최소한으로 남겨두었습니다.
- 그런 다음: ollama create glm-4.7-flash-local -f Modelfile
- 실행: ollama run glm-4.7-flash-local
사용 중 주의사항:
- 첫 번째 로드는 캐시를 준비하면서 더 느립니다.
- 저는 num_ctx를 보수적으로 유지합니다 (책 초안을 요약하지 않는 한 4K 또는 8K). 더 큰 컨텍스트는 좋아 보이지만, 메모리 소비가 많고 일상적인 초안에 항상 품질 향상을 도와주지는 않습니다.
- 생성이 꺼려하는 것처럼 느껴지면, 온도를 0.6~0.7로 낮추고 top_p를 약간 올려보세요: 속도를 잃지 않으면서 출력을 단단하게 했습니다.
참고자료: Ollama 문서는 플랫폼별 플래그와 현재 백엔드에 대해 탄탄합니다.

Mac 성능
M4 / M3 / M2 벤치마크
이것은 실험실급이 아니라, 작성 및 간단한 코드 프롬프트에서의 안정적인 실행입니다. 온도 0.7, 4K 컨텍스트, 4비트 양자화:
- M4 (빌린 컴퓨터, 48GB): 준비 후 60
85 tok/s. 첫 토큰은 약 350500ms. - M3 Pro (36GB): 35
55 tok/s. 첫 토큰은 약 500800ms. - M2 (24GB): 20
30 tok/s. 첫 토큰은 약 9001200ms.
범위를 대략적인 확인으로 생각하세요. M3 Pro에서 몇 가지 8K 컨텍스트를 사용해봤습니다: 속도는 약 2030% 떨어졌지만 초안 작성에는 여전히 사용 가능했습니다. M2에서는 긴 컨텍스트가 “느끼게 끈기 있는” 선을 넘었습니다. 저는 그곳에서 24K로 유지했습니다.
메모리 최적화
macOS에서 가장 도움이 된 것:
- 모델을 실행하는 더 적은 터미널 탭을 유지하세요. 명백하지만, 저는 자주 잊습니다.
- 컨텍스트를 올바른 크기로 설정하세요. 4K는 저에게 최적의 지점입니다.
- 가능하면 4비트 양자화를 사용하세요. 5비트는 제 사용에 대해 품질이 유사했지만 더 느렸습니다.
- GPU 시간을 차지하는 앱을 닫으세요 (비디오 편집기, WebGL이 있는 일부 브라우저 탭).
또한 안정적인 시스템 프롬프트를 사용하면 재작업이 감소하는 것을 알았습니다. 종이 위에서는 더 빠르지 않지만, 재시도가 적으면 더 나은 “느낀 속도”를 의미합니다. “간결하게, 평문을 사용하고, 마케팅 톤 없음”과 같은 작은 프롬프트. 모델의 강점에 맞습니다.
Windows + NVIDIA
RTX 3090 / 4090 구성
4090 (24GB)에서 GLM-4.7-Flash는 일관되게 빨랐습니다:
- 4비트 양자화, 4
8K 컨텍스트: 준비 후 120220 tok/s. - 첫 토큰: 약 250~400ms.
- 병렬 프롬프트: 끊김이 보일 때까지 2~3 스트림.
친구는 3090 (24GB)에서 실행했고 비슷한 설정으로 약 1525% 낮은 처리량을 보았습니다. 8K 컨텍스트를 초과하거나 많은 응답을 계속 진행하면 VRAM 여유가 부족해집니다. 일반적으로 46K로 물러나고 배치를 작게 유지합니다.
CUDA 설정
실제로 중요했던 것:
- 최신 NVIDIA 드라이버 (깨끗한 설치는 끊김이 있던 한 대의 컴퓨터를 도왔습니다).
- CUDA 12.x 및 Ollama 외부(vLLM/SGLang)를 진행할 경우 일치하는 런타임. Ollama 자체의 경우 전체 도구 키트가 항상 필요한 것은 아니지만, 최신 드라이버는 협상의 여지가 없습니다.
- 전원 설정: GPU를 “최대 성능 선호”로 설정하세요. 게이머 조언처럼 들리지만, 긴 실행 중에 클록 절감을 중지했습니다.
로드 오류나 CPU로의 하드 폴백이 발생하면:
- 드라이버 버전이 CUDA 런타임과 일치하는지 확인하세요.
- 안티바이러스가 모델 디렉토리를 스캔하고 있는지 여부 (발생했습니다: 어리석었습니다: 느렸습니다).
참고자료: NVIDIA의 드라이버-CUDA 호환성 표를 디버깅에 시간을 소비하기 전에 빠르게 확인할 가치가 있습니다.
vLLM / SGLang
배칭 및 서버 스타일 엔드포인트에 대해 더 많은 제어를 원할 때 vLLM 및 SGLang을 사용하여 GLM-4.7-Flash를 시도했습니다.
vLLM
- 설치: 최신 Python, CUDA 호환 PyTorch, 그 다음 pip install vllm.
- 실행:
python -m vllm.entrypoints.openai.api_server --model <your_glm_flash_id> --dtype auto --max-model-len 4096 - 사용한 이유: 안정적인 OpenAI 호환 API, 다중 사용자 또는 다중 탭 워크플로우를 위한 탄탄한 처리량.
SGLang
- 설치: pip install sglang
- 실행:
python -m sglang.launch_server --model <your_glm_flash_id> --context-length 4096 - 사용한 이유: 낮은 지연 스트리밍이 빠르게 느껴졌고, 작은 라우팅 작업과 잘 작동했습니다.
둘 다 적절한 모델 경로나 HF 저장소 ID가 필요합니다. GLM-4.7-Flash가 기본 인덱스에 없으면 로컬 GGUF 또는 호환 가중치 형식을 가리켜야 합니다. 또한: CUDA와 드라이버 버전을 일치시키지 않으면 불투명한 커널 오류를 추적하게 됩니다. 저는 dtype을 자동으로 유지했고 VRAM이 남아있을 때만 강제로 fp16을 설정했습니다.
단일 사용자 작성 세션의 경우 Ollama가 더 간단했습니다. vLLM/SGLang은 OpenAI 스타일 엔드포인트가 필요한 도구를 테스트할 때 의미가 있었습니다.
문제 해결
모델 로드 실패
제가 본 것:
- 로드 중 “메모리 부족”. 해결: 더 작은 양자화(예: 4비트)로 전환, num_ctx 낮추기, 또는 GPU 집약적인 앱 닫기.
- Windows에서 “호환 백엔드 없음”. 해결: GPU 드라이버 업데이트: vLLM/SGLang을 사용하는 경우 CPU 전용 PyTorch를 설치하지 않았는지 확인: 드라이버 업그레이드 후 재부팅.
- Ollama에서 모델을 찾을 수 없음. 해결: Modelfile을 만들고 ollama create 실행: 또는 정확한 저장소 태그가 있으면 거기서 가져오기.
모델이 조용히 CPU로 폴백되면, 표시는 팬 소음(또는 부재)과 훨씬 느린 토큰/초입니다. 모델이 “더 나빠진” 것으로 가정하기 전에 장치 활용을 확인하는 법을 배웠습니다.
느린 추론 수정
예상보다 더 중요했던 작은 변경사항:
- 컨텍스트를 올바른 크기로 설정하세요. 컨텍스트를 절반으로 줄이면 샘플링을 조정하는 것보다 속도를 높이는 경우가 많습니다.
- 캐시를 데웁니다. 짧은 실행은 다음 실행을 개선합니다.
- 병렬 스트림을 줄입니다. 동시성은 KV 캐시가 당신을 방해할 때까지 효율적으로 보입니다.
- NVIDIA의 경우: 고성능 전원 모드 설정, 오버레이 앱 닫기, 백그라운드 인코더 중지.
- macOS의 경우: 충전기를 꽂아두세요: 일부 노트북은 배터리 상태에서 다운시프트합니다.
하나 더: 최대 토큰/초를 추적하기를 중단했습니다. 제 경우 더 나은 메트릭은 “첫 사용 가능한 생각”이었습니다. GLM-4.7-Flash는 프롬프트를 집중하고 컨텍스트를 합리적으로 유지했을 때 빨리 제게 그것을 제공했습니다.
 GLM-4.7-Flash의 속도를 좋아하지만 드라이버, CUDA 버전 또는 백엔드 문제를 돌보고 싶지 않다면, WaveSpeed를 시도해보세요 - 낮은 수준의 조정 없이 안정적인 빠른 추론에 중점을 두는 우리의 플랫폼. 모델 파일, 양자화 형식 또는 GPU 호환성에 대해 걱정할 필요 없이 예측 가능한 지연 시간을 얻습니다.
GLM-4.7-Flash의 속도를 좋아하지만 드라이버, CUDA 버전 또는 백엔드 문제를 돌보고 싶지 않다면, WaveSpeed를 시도해보세요 - 낮은 수준의 조정 없이 안정적인 빠른 추론에 중점을 두는 우리의 플랫폼. 모델 파일, 양자화 형식 또는 GPU 호환성에 대해 걱정할 필요 없이 예측 가능한 지연 시간을 얻습니다.
관련 기사

Seedance 2.0, WaveSpeedAI에 출시 예정: 네이티브 오디오가 포함된 ByteDance의 차세대 비디오 모델

Seedance 2.0 완벽 가이드: 멀티모달 비디오 생성

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: 최고의 비디오 생성 비교

Seedream 5.0-Preview 완벽 가이드: 지능형 이미지 생성

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 완벽한 비교
