GLM-4.7-Flash: 출시 일정, 무료 티어 및 주요 기능 (2026)

안녕하세요. 저는 도라입니다.
최근에 GLM-4.7-Flash가 신뢰할 수 있는 사람들의 스레드에 계속 나타났습니다. 보통 작은 어깨 으쓱과 함께 언급되곤 했습니다: “충분히 빨라서 방해가 되지 않는다”는 말이죠. 그 표현이 계속 맴돌았습니다. 저는 지금 반짝반짝한 모델을 찾고 있지 않습니다: 일상적인 작업을 더 가볍게 만들어주는 도구를 찾고 있습니다. 무슨 뜻인지 알겠죠?
그래서 GLM-4.7-Flash를 제 스택에 며칠간 넣어봤습니다(2026년 1월 20-21일). 짧은 프롬프트, 작은 API 스크립트, 몇 가지 배치 작업들. 특별한 것은 없었습니다. 제가 계속 묻고 있던 질문은 단순했습니다: 이게 실질적인 추가 기능인가, 아니면 타임라인을 지나가는 또 다른 모델 이름인가?
GLM-4.7-Flash란 무엇인가?
GLM-4.7-Flash는 Zhipu AI의 GLM-4.7 계열의 속도 중심 변형입니다. 무거운 추론 오버헤드 없이 빠르고 낮은 지연 시간의 생성을 원할 때 사용하는 모델이라고 생각하면 됩니다. 장문 벤치마크에서 이기거나 철학을 논하려는 것은 아닙니다: 빠르고 저렴하게 적절한 답변을 제공하는 것을 목표로 합니다.
개발사 (Zhipu AI / Z.ai)
 Zhipu AI(Z.ai로도 알려짐)는 GLM 시리즈를 개발한 팀입니다. 이전 GLM 모델을 사용해본 적이 있다면 명명 규칙이 익숙할 것입니다: 숫자는 세대를 나타내고, 접미사(Flash, Standard 등)는 트레이드오프를 암시합니다. 그들의 문서는 간단명료하고 정기적으로 업데이트됩니다: 통합을 계획 중이라면 Zhipu 개발자 포털의 공식 API 문서를 북마크해두세요.
Zhipu AI(Z.ai로도 알려짐)는 GLM 시리즈를 개발한 팀입니다. 이전 GLM 모델을 사용해본 적이 있다면 명명 규칙이 익숙할 것입니다: 숫자는 세대를 나타내고, 접미사(Flash, Standard 등)는 트레이드오프를 암시합니다. 그들의 문서는 간단명료하고 정기적으로 업데이트됩니다: 통합을 계획 중이라면 Zhipu 개발자 포털의 공식 API 문서를 북마크해두세요.
저는 다국어 지원이 필요하고 안정적이고 예측 가능한 결과물이 필요할 때 지난 1년간 Zhipu 모델을 간헐적으로 사용해왔습니다. GLM-4.7-Flash는 그 패턴을 계속하되 속도와 처리량에 더 많은 주의를 기울입니다.
Flash vs Standard, 위치 결정
실제로 사용하면서 느낀 차이점은 이렇습니다:
- Flash: 속도 최적화, 요청당 낮은 컴퓨팅, 대량 엔드포인트, UI 어시스턴트, 배치 분류 또는 태깅에 훌륭합니다. 짧은 프롬프트와 명확한 구조에서 가장 잘 작동한다는 것을 알아챘습니다.
- Standard (비-Flash): 추론이 많은 작업에서 더 느리지만 안정적입니다. 다단계 분석을 Flash에 던지면 시도하지만, 지연 시간을 낮추기 위해 단계를 압축하는 것을 볼 수 있었습니다.
둘 중에서 선택할 때, 간단한 규칙: 지연 시간과 비용이 하루를 좌우한다면 Flash부터 시작하세요. 다단계 추론에서 정확성이 주요 제약 조건이라면 Standard(또는 더 큰 추론 조정 버전)가 더 나을 것입니다. 당신이 선택할 전투기를 고르는 것이죠.
공식 출시: 2026년 1월 19일
Zhipu AI는 2026년 1월 19일에 GLM-4.7-Flash를 발표했습니다. 저는 다음 날 테스트를 시작했습니다. 이 모델들의 버전 컨텍스트는 중요합니다: 초기 단계는 종종 빠른 반복을 수반합니다. 나중에 이것을 읽고 있다면 공식 문서의 릴리스 노트를 확인하여 제한 사항이나 동작의 변경 사항을 확인하세요.
아키텍처 한눈에 보기
모델의 내부 구조를 알 필요는 없지만, 특정 세부 사항이 비용을 추정하고 어디에서 잘 작동할지 파악하는 데 도움이 됩니다.
30B MoE, 3B 활성 파라미터
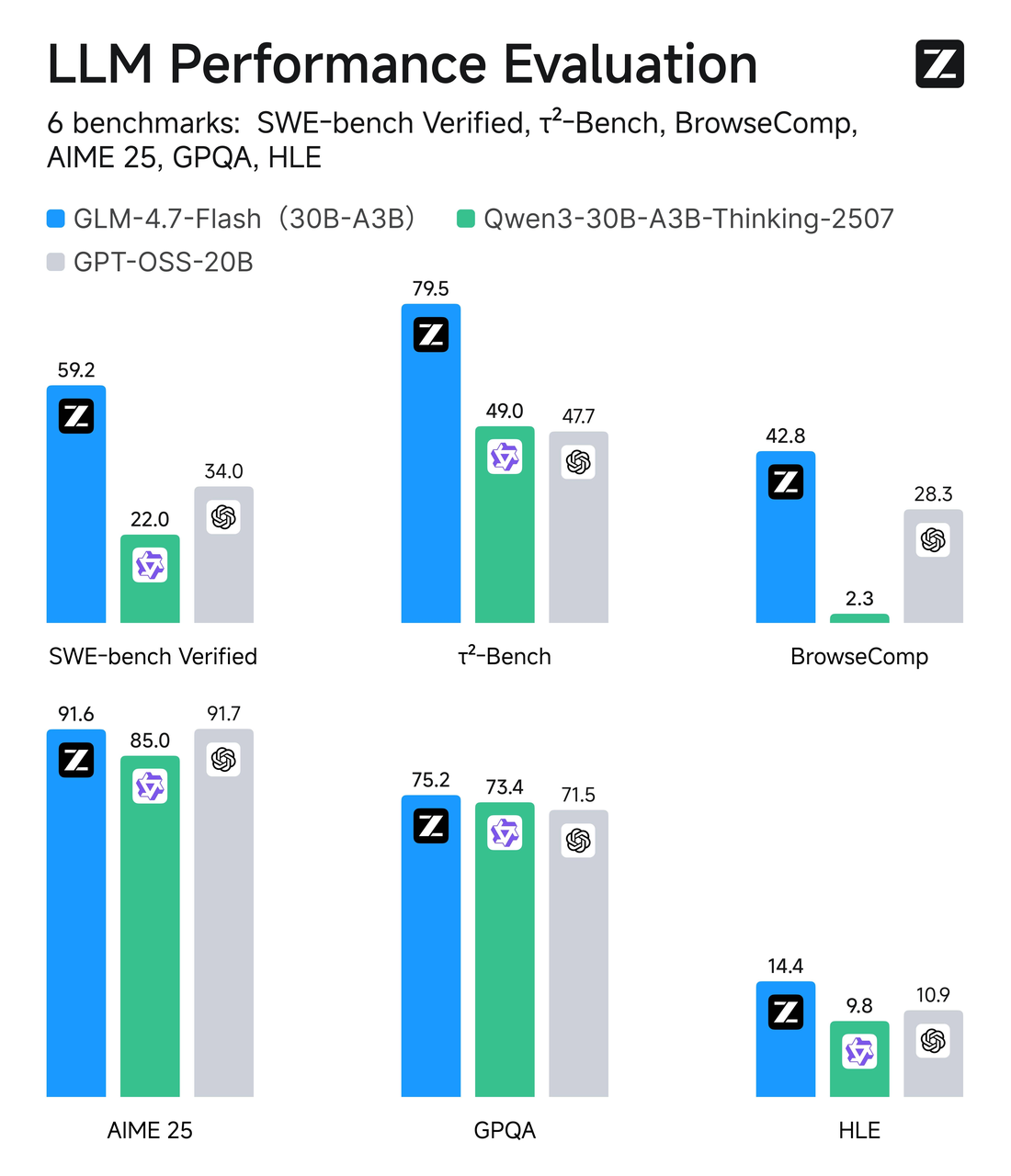 GLM-4.7-Flash는 총 파라미터 수가 약 30B이지만 토큰당 약 3B 전문가만 활성화되는 혼합 전문가(MoE) 설계를 사용합니다. 쉽게 말하면: 선택적 라우팅이 있는 광범위한 모델입니다. 대부분의 경우 네트워크의 작은 슬라이스만 토큰에 대해 작동하므로 추론이 효율적입니다.
GLM-4.7-Flash는 총 파라미터 수가 약 30B이지만 토큰당 약 3B 전문가만 활성화되는 혼합 전문가(MoE) 설계를 사용합니다. 쉽게 말하면: 선택적 라우팅이 있는 광범위한 모델입니다. 대부분의 경우 네트워크의 작은 슬라이스만 토큰에 대해 작동하므로 추론이 효율적입니다.
실제로 MoE는 종종 항상 전체 컴퓨팅 비용을 지불하지 않으면서도 “필요할 때 더 큰 두뇌”의 느낌을 줍니다. 제 테스트 중에 이것은 부하 상황에서도 반응적인 출력으로, 그리고 유사한 보고된 규모의 조밀한 모델보다 더 일관된 지연 시간으로 변환되었습니다. 마법은 아니고, 단지 용량과 속도의 균형을 맞추는 똑똑한 방법입니다.
MLA (Multi-Headed Latent Attention)
문서에는 MLA(Multi-Headed Latent Attention)가 언급되어 있습니다. 사용자로서의 제 해석: 특히 더 긴 컨텍스트에서 클래식 완전 자기 주의보다 더 효율적인 것을 목표로 하는 주의 전략입니다. 저는 여기서 긴 컨텍스트 제한을 추진하지 않았습니다: 대부분의 실행은 몇 천 개 토큰 이하였습니다. 그래도 메모리 풋프린트는 합리적으로 유지되었으며, 프롬프트가 “짧은”에서 “중간”으로 증가할 때 일반적인 지연 시간 저하를 보지 못했습니다.
검색 집약적인 워크플로우나 에이전트 루프를 계획하고 있다면 MLA와 MoE는 도움이 되는 신호입니다: 이 모델은 최대 단일 샷 추론 깊이를 추구하기보다는 처리량을 유지하도록 설계되었습니다.
무료 API — 포함 사항
무료 접근이 두드러졌습니다. 저는 여기서 조심합니다. 무료 계층이 때로는 매주 변경되기 때문입니다. 제가 공유하는 것은 2026년 1월 20-21일에 제가 관찰한 것과 Zhipu의 문서가 출시 시점에 제안한 것입니다. 프로덕션에 이것을 연결하기 전에 항상 제한 사항을 다시 확인하세요.
 요약하면: 무료 API를 통해 합리적인 기본값으로 실제 요청을 할 수 있었습니다. 테스트 중간에 페이월을 만나지 않고 작은 작업을 실행했습니다. 그것이 플레이그라운드보다는 라이브 스크립트에서 시도하는 마찰을 줄였습니다.
요약하면: 무료 API를 통해 합리적인 기본값으로 실제 요청을 할 수 있었습니다. 테스트 중간에 페이월을 만나지 않고 작은 작업을 실행했습니다. 그것이 플레이그라운드보다는 라이브 스크립트에서 시도하는 마찰을 줄였습니다.
속도 제한 및 동시성
제가 본 것:
- 동시성: 작은 워커에서 여러 병렬 요청을 편하게 실행할 수 있었고 오류를 발생시키지 않았습니다. 제 테스트에서 5-10개의 동시 호출은 안정적으로 유지되었습니다. 더 높게 스파이크할 때 제한을 보기 시작했는데, 이는 무료 계층에서 예상됩니다.
- 처리량: 짧은 프롬프트(분류, 작은 변환)는 1초 미만에서 낮은 초 범위에서 반환되었습니다. 평균적으로 매우 짧은 응답은 300-900ms, 적당한 출력은 1.5-3초를 보았습니다. 네트워크 편차가 적용됩니다.
- 안전성: API는 제한을 초과할 때 명확한 오류 코드로 응답했습니다. 그것만으로도 시간을 절약했습니다. 뭔가 잘못되었는지 추측할 필요가 없었습니다.
정확한 TPS 상한을 추구하지 않았습니다: 제 목표는 작은 파이프라인이 감시 없이 실행될 수 있는지 보는 것이었습니다. 그들은 했습니다. 자유로움처럼 느껴집니다, 솔직히. 급증하는 워크로드를 계획하고 있다면 현실적인 동시성으로 테스트하고 간단한 재시도/백오프를 구축하세요. 무료 계층은 너그럽다가 갑자기 아닙니다.
FlashX 유료 계층
Zhipu는 더 높은 처리량과 더 예측 가능한 성능을 목표로 하는 “FlashX” 유료 옵션을 언급합니다. 이 실행 중에 제 테스트를 FlashX로 이동하지 않았지만, 이 같은 제공업체가 계층을 업그레이드할 때 일반적으로 변경되는 것은 다음과 같습니다:
- 스로틀이 적은 높고 보장된 속도 제한.
- 키당 더 많은 동시 요청으로 배치 작업과 사용자 대면 어시스턴트에 유용합니다.
- 우선순위 라우팅(낮은 꼬리 지연). 이것은 중앙값뿐 아니라 요청의 최악의 5%를 신경 쓸 때 중요합니다.
고객 대면 기능을 출시하고 있다면 FlashX가 더 안전한 경로입니다. 장난을 치고 있다면 무료 계층이 안정성과 통합 작업에 대한 느낌을 얻기에 충분합니다. 당신의 경험은 지연 시간 예산과 배치 빈도에 따라 달라질 것입니다.
최적의 사용 사례
저는 몇 가지 실제 작업을 시도했습니다. 화려한 것은 없고, 단지 제 주에 나타나는 것들입니다.
- 지연이 분위기를 망치는 인터페이스 어시스턴트. 생각: 인라인 다시 쓰기, 작은 설명, 짧은 후속. GLM-4.7-Flash는 UI를 즉각적으로 느끼게 했습니다.
- 배치 텍스트 변환. 작은 CSV(수천 행)를 톤 조정과 카테고리 태그를 위해 실행했습니다. 모델은 일관성 있게 유지되었고 중간에 표류하지 않았습니다.
- 스캐폴딩 초안. 개요, 포인트별 확장, 간단한 요약. 명확한 지시를 주었을 때 구조를 잘 처리했습니다. 뇌물을 줄 필요가 없는 미니 도우미를 두는 것처럼요.
- 짧은 컨텍스트 윈도우를 가진 검색 요약. 2-4개의 스니펫을 연결했을 때 이상한 다리를 환각하지 않고 깔끔하게 응답했습니다. 길고 지저분한 컨텍스트가 있을 때 도움이 되려고 시도했지만 때로는 너무 공격적으로 압축했습니다.
- “첫 번째 통과” 코드 주석이나 문자열. 깊은 리팩토링이 아닙니다. 단지 의도와 명명을 명확히 하고, 빠르고 유용합니다.
사용하지 않을 곳:
- 정확성이 속도보다 중요한 엣지 케이스가 있는 다단계 분석. 더 무거운 추론 모델에 도움을 청할 것입니다.
- 수천 개 토큰에 걸쳐 안정적인 톤과 깊은 사실 연결이 필요한 장문 생성. Flash는 할 수 있지만 성격에 맞지 않는 것처럼 느껴집니다.
이것이 중요한 이유: 예산을 박살내지 않는 빠른 모델은 당신이 다른 방식으로 자를 기능을 엽니다. 제품이 세션당 수십 개의 작은 모델 호출이 필요하면 절약된 지연 시간과 호출당 낮은 컴퓨팅이 누적됩니다. 작은 이득, 큰 보상.
💡 GLM-4.7-Flash와 같은 모델을 실제 워크플로우에서 더 쉽고 안정적으로 실행하기 위해 저는 WaveSpeed를 사용합니다 — API 요청, 동시성, 배치 작업을 부드럽게 처리하는 우리 자체 플랫폼이므로 스크립트를 감시하는 대신 결과에 집중할 수 있습니다.
WaveSpeed 시도 →
 현장에서의 작은 메모: 제 첫 시간은 더 빠르지 않았습니다. 프롬프트 구조, 온도, 최대 토큰으로 이것저것 해봤습니다. 몇 번 실행 후 패턴을 발견했습니다: 짧은 시스템 프롬프트, 명시적 출력 형식, 명확한 제약. 그것이 시간과 정신적 노력을 줄였습니다. 마법이 아니었습니다: 설정이었습니다.
현장에서의 작은 메모: 제 첫 시간은 더 빠르지 않았습니다. 프롬프트 구조, 온도, 최대 토큰으로 이것저것 해봤습니다. 몇 번 실행 후 패턴을 발견했습니다: 짧은 시스템 프롬프트, 명시적 출력 형식, 명확한 제약. 그것이 시간과 정신적 노력을 줄였습니다. 마법이 아니었습니다: 설정이었습니다.
GLM-4.7-Flash(또는 모든 Flash 모델)의 “빠른 10분 테스트”를 시작했다가 시계를 보니 자정인 다른 사람이 있나요? 당신의 개인 기록을 드롭하세요 - 그리고 마침내 그것이 작동하게 만든 한 가지 프롬프트 조정을 댓글에 작성해주세요.
관련 기사

Seedance 2.0, WaveSpeedAI에 출시 예정: 네이티브 오디오가 포함된 ByteDance의 차세대 비디오 모델

Seedance 2.0 완벽 가이드: 멀티모달 비디오 생성

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: 최고의 비디오 생성 비교

Seedream 5.0-Preview 완벽 가이드: 지능형 이미지 생성

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 완벽한 비교
