5분 안에 AI 앵커 만들기: 디지털 휴먼 구축 초보자 가이드

WaveSpeedAI에서 디지털 휴먼을 구축하는 단계별 튜토리얼입니다.
서문
모든 사람이 타고난 연설가는 아니며, 모두가 대중 앞에서 말하는 것을 편하게 느끼지는 않습니다.
연설을 위해 일어서는 것은 신경 쓸 일이 될 수 있습니다. 하지만 “가상의 당신”이 프레젠테이션을 진행하고, 라이브 방송을 하거나, 당신의 프로모션 음성 녹음을 대신 녹음할 수 있다면 어떨까요? 그렇다면 여전히 두려워할까요?
WaveSpeedAI에서는 그것이 더 이상 단순한 아이디어가 아닙니다! 처음부터 자신만의 디지털 휴먼을 만들고, 현실적인 음성과 표정으로 당신의 말을 할 수 있게 만들 수 있습니다.
무대 공포증이 없고, 절대 지치지 않으며, 원할 때마다 완성도를 높이고 재사용할 수 있습니다. 일과 삶에서 당신의 믿을 수 있는 파트너입니다.
이 튜토리얼에서는 간단한 디지털 휴먼을 단계별로 구축하면서 처음부터 끝까지 안내하겠습니다. 여기서 사용하는 모델은 시작일 뿐이므로, 자유롭게 더 많은 기능과 스타일을 탐색하여 당신의 디지털 휴먼을 정말로 독특하게 만들어보세요.
WaveSpeedAI에서 우리의 모델은 선명하고 안정적인 시각적 효과를 생성하며, 자연스러운 가장자리를 가지고 있어 바로 전시할 준비가 되어 있습니다. 공식적인 토크 세그먼트, 캐주얼한 대화, 제품 설명자 등 모두에 효과적입니다.
이미지 생성
잘생기고 귀엽고 자연스러운 외모의 디지털 휴먼은 시청자에게 더 나은 경험을 제공합니다. 또한 채널에 더 많은 화제와 트래픽을 끌어올 것입니다.
개인 사진에서 직접 만들 수도 있습니다. 이미 적절한 사진이 준비되어 있다면, 이 부분을 자유롭게 건너뛰셔도 됩니다.
나는 bytedance/seedream-v4 를 예시로 사용하여 당신만의 독특한 가상 아바타를 만드는 방법을 도와드리겠습니다.
WaveSpeedAI에서 bytedance/seedream-v4 를 검색하세요. 이것은 텍스트-이미지 모델입니다. 이제 당신만의 디지털 휴먼을 만들기 위해 프롬프트를 입력해봅시다:
Half-length portrait of a young female digital human (22–28),
natural makeup, white shirt and light gray blazer,
looking at camera, soft studio light,
plain light-gray background, ultra realistic, 4k, 85mm, f/2.8
성별, 의상, 배경 과 같은 요소를 사용자 정의하여 필요에 맞게 다양한 스타일과 분위기를 만들 수 있으므로, 당신의 디지털 휴먼이 더욱 매력적이고 브랜드에 맞춰질 수 있습니다.
음성 생성
이제 당신의 디지털 휴먼이 준비되었으니, 다음 단계는 그들이 자연스럽게 “말할” 수 있도록 명확한 음성 해설 스크립트를 작성하는 것입니다.
WaveSpeedAI에서 카테고리 > 텍스트-오디오 로 이동하여 다양한 모델을 살펴보세요. 우리는 자연스러운 음성 해설, 음성 복제, 심지어 노래 작곡 모델을 제공합니다.
이 섹션에서는 minimax/speech-02-hd 를 예시로 사용하겠습니다. 다양한 음성 스타일과 효과를 탐색하기 위해 다른 모델을 시도해보세요.
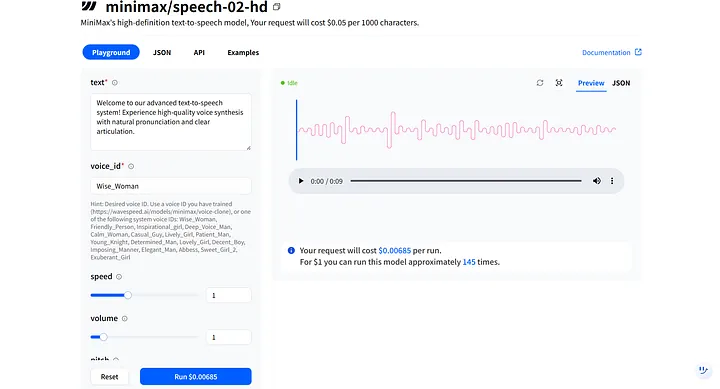
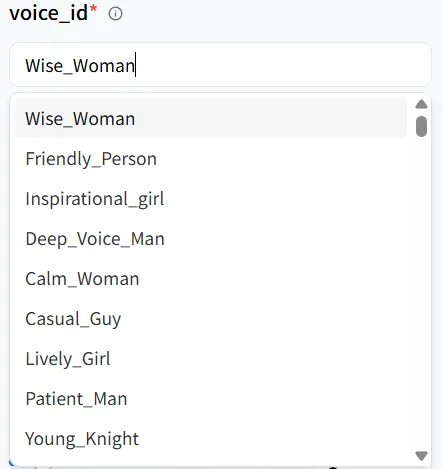
모델의 Playground 에서는 text 와 voice_id 같은 주요 매개변수를 볼 수 있습니다. 이들은 함께 작동하여 당신의 디지털 휴먼의 음색과 톤을 형성하며, 다양한 시나리오에 맞게 조정할 수 있습니다. 예를 들어, 내가 만든 디지털 휴먼은 여성이므로, 첫 번째 음성 옵션인 Wise_Woman 을 선택할 수 있습니다.
주요 매개변수
속도
speed 는 당신의 디지털 휴먼이 말하는 속도를 조절합니다. 장면에 맞는 페이스를 선택하세요. 예를 들어, 제품 소개는 약간 느리게, 캐주얼한 대화는 빠르게 할 수 있습니다. 1 의 값은 정상 속도를 나타냅니다.

볼륨
volume 은 음량을 설정합니다. 당신의 디지털 휴먼이 자장가를 내레이션하는 경우, speed 를 낮춰서 속도를 늦추고 volume 을 줄여 더 부드러운 전달을 할 수 있습니다. 1 의 값은 기본 음량입니다.
음높이
pitch 는 음성의 톤을 조정합니다. 이를 조정하여 음성을 더 밝고 선명하게 하거나, 더 깊고 풍부하게 만들 수 있습니다. 0 의 값은 기본 음높이입니다.

감정
emotion 은 당신의 디지털 휴먼의 말하기 스타일을 조절합니다. 장면과 맞는 톤을 선택하세요. 여기서는 happy 를 선택하겠습니다.
영어 정규화
english_normalization 옵션을 활성화하면, 영어로 된 숫자와 기호가 음성에서 자연스럽게 들립니다. 이것이 없으면, 시스템이 “123”을 “1 2 3”(일이 이삼)이라고 읽을 수 있는데, “123”을 “일백이십삼”이라고 읽게 됩니다.

샘플링 레이트
sample_rate 는 오디오 품질(해상도)을 결정합니다. ASMR 스타일의 콘텐츠를 제작하는 경우, 더 풍부한 세부 사항을 위해 더 높은 샘플링 레이트를 목표로 하세요. 이 튜토리얼 예시의 경우 중요하지 않으므로, 기본값을 유지하면 완벽합니다.
비트레이트
bitrate 는 오디오 파일의 품질과 크기를 모두 결정합니다. 이는 초당 처리되는 비트 수를 나타냅니다. 낮은 비트레이트는 작은 파일을 만들지만 세부 사항을 잃을 수 있고, 높은 비트레이트는 더 큰 파일을 만들지만 더 선명한 음질을 제공합니다.
채널
channel 매개변수는 생성된 오디오 채널의 수를 결정합니다.
- channel = 1 (모노): 모든 사운드가 단일 채널로 혼합됩니다. 휴대폰 음성, 통화 녹음 또는 공간적 너비가 필요하지 않은 대화 중심의 콘텐츠에 이상적입니다.
- channel = 2 (스테레오): 사운드가 좌우 채널로 분리되어 더 몰입적인 레이어드 경험을 위해 너비와 공간감을 만듭니다. 음악, 영화, 게임, 더 높은 청취 품질을 필요로 하는 비디오 음성 해설에 완벽합니다.
형식
format 을 통해 출력 오디오 파일 유형을 선택할 수 있습니다(구체적인 사항은 여기서 건너뜁니다).
언어 부스트
language_boost 는 선택한 언어에 대한 모델의 이해를 향상시킵니다. 이 튜토리얼에서는 English 를 선택하세요.
오디오 생성
이제 스크립트를 붙여넣고 Run 을 클릭하여 오디오를 생성하세요!
Welcome to WaveSpeedAI’s Digital Human Tutorial. We’ll spark fresh ideas in AIGC and show you practical steps. Let’s unleash your creativity together!
오디오 파일을 다운로드하세요. 이것이 당신의 디지털 휴먼이 나중에 말할 수 있게 해주는 중요한 부분입니다!
디지털 휴먼이 말하게 하기
마지막으로, 흥미로운 순간이 왔습니다: 당신의 디지털 휴먼을 실제로 말하게 만들어 봅시다!
WaveSpeedAI에서 wavespeed-ai/infinitetalk 를 검색하세요. 이것은 디지털 휴먼 음성 해설을 위해 특별히 설계된 고품질 모델입니다.
모델의 Playground 에서는 audio 와 image 두 가지 필수 입력을 볼 수 있습니다.
- audio: 방금 다운로드한 음성 해설 파일을 업로드하세요.
- image: 앞서 생성한 디지털 휴먼 이미지를 업로드하세요.
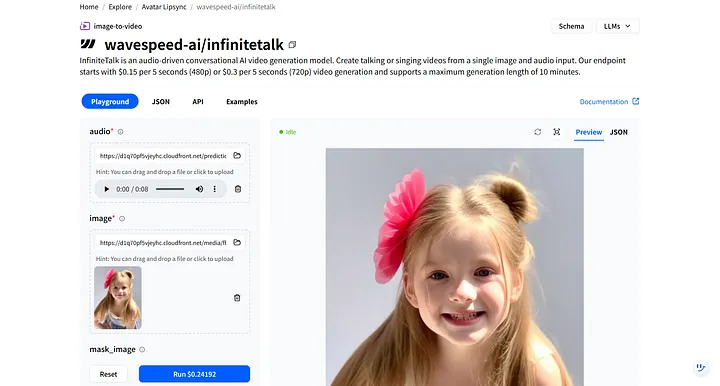
Run 을 클릭한 후, 디지털 휴먼이 오디오에 반응하고 입술 움직임과 표정을 자동으로 동기화합니다.
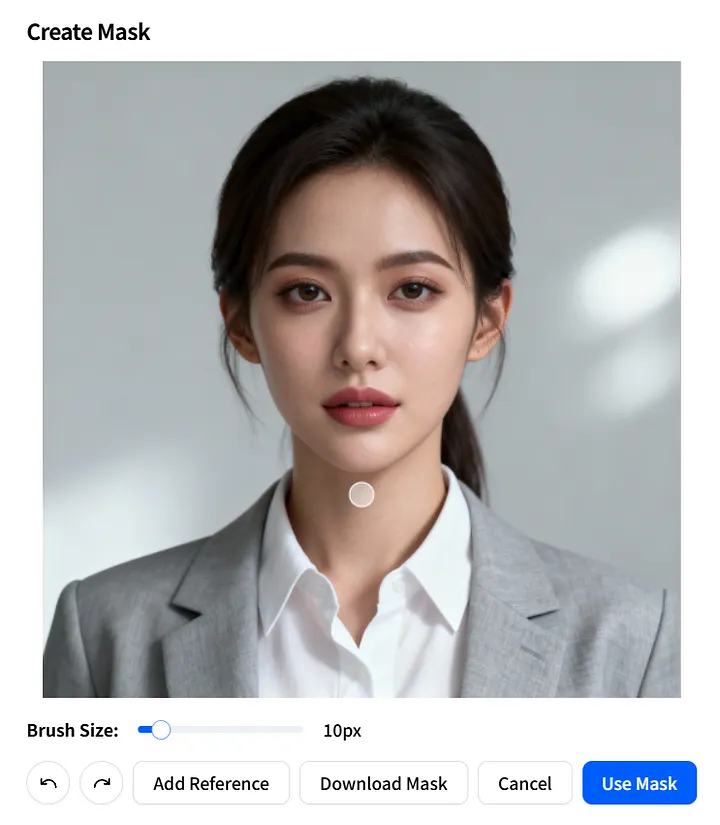
마스크 이미지 매개변수
이제 mask_image 매개변수를 살펴봅시다. 이를 통해 이미지의 어떤 부분을 애니메이션화할지 정확히 지정할 수 있습니다.
Create Mask 페이지에서 움직일 수 있는 영역을 정확히 정의하세요: Brush Size 를 조정하고, 애니메이션화하려는 영역에 그림을 그린 후, Use Mask 를 클릭하여 적용하세요.
또한 Download Mask 를 클릭하여 mask_image 를 템플릿으로 저장한 후 향후 프로젝트에서 빠르게 재사용할 수 있습니다.
추가 사용자 정의
포즈, 손 제스처 또는 시선 방향 지정과 같은 추가 요구 사항이 있는 경우, prompt 에 더 구체적인 지시를 추가하세요.
쉬운 복제를 위해 고정된 seed 값을 설정하세요. 이렇게 하면 난수 생성이 일관되어 나중에 동일한 결과를 재현할 수 있습니다.
마지막으로 Run 을 클릭하고, 최종 결과를 기대해봅시다!
축하합니다! 이제 당신만의 디지털 휴먼을 갖게 되었습니다!
다중 인물 장면 으로 나아갈 준비가 되셨나요? WaveSpeedAI는 그를 위해 전용 모델도 제공합니다. 함께 탐색해봅시다!
다중 스피커 생성
WaveSpeedAI에서 wavespeed-ai/infinitetalk/multi 를 검색하세요. 그 단계는 기본적으로 단일 인물 모델과 동일합니다.
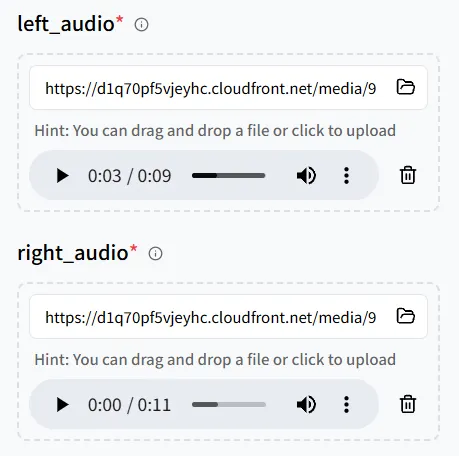
이번에는 두 개의 오디오 파일 을 추가한 후, 두 명의 디지털 휴먼이 있는 이미지 를 업로드하여 두 캐릭터 모두 자신의 대사를 전달할 수 있도록 하세요.
오디오와 이미지 내 위치 간의 페어링에 주의깊게 살펴보세요:
- left_audio → 이미지에서 ** 왼쪽**에 있는 사람
- right_audio → 이미지에서 ** 오른쪽**에 있는 사람
매핑을 신중히 검토하세요. 그렇지 않으면 음성이 잘못된 캐릭터에 연결될 수 있습니다.
말하기 모드
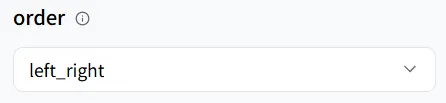
wavespeed-ai/infinitetalk/multi 모델에서는 세 가지 말하기 모드를 지원합니다:
- left_right (왼쪽에서 오른쪽으로)
- right_left (오른쪽에서 왼쪽으로)
- meanwhile (동시 음성)
마찬가지로, 이 모델을 사용하면 prompt 를 통해 원하는 세부 사항을 추가할 수 있으며, 쉬운 재현성을 위해 seed 를 설정할 수 있습니다.
이렇게 해서, 당신은 두 사람의 음성 해설 쇼를 갖게 되었습니다!
다른 모델들
WaveSpeedAI에서 우리는 당신을 위해 많은 추가 모델도 제공합니다:
- wavespeed-ai/multitalk: “노래 스타일 디지털 휴먼”에 완벽하며, 다중 파트 보컬과 더 표현력 있는 성능을 가능하게 합니다.
- wavespeed-ai/infinitetalk/video-to-video: 기존 비디오에 음성 해설이나 내레이션을 추가하여 시각적 요소와 오디오가 자연스럽게 동기화되도록 합니다.
- wavespeed-ai/song-generation: 처음부터 음악을 만들어 콘텐츠를 위한 커스텀 사운드트랙과 분위기를 디자인하세요.
이 모델들은 또한 다른 플랫폼에서 복제하기 어려운 독특한 경험을 제공합니다. 대담해지세요. 이들을 시도해보고 당신의 작업을 공유하세요! Inspiration 섹션에 게시하여 다른 크리에이터들과 연결하고 상호 작용할 수 있습니다!

최종 생각
우리의 세계는 빠르게 변화하고 있으며, AI는 우리의 일상생활에 점점 더 영향을 미치고 있습니다. 구식 방법에 고착하는 것은 비용을 증가시키고, 진행을 늦추며, 새로운 기회를 놓칠 위험이 있습니다.
지금이 새로운 기술을 도입하고 그것이 제공하는 편의성과 효율성을 누릴 수 있는 완벽한 시간입니다. WaveSpeedAI는 신뢰할 수 있는 기술과 계속 성장하는 생태계로 콘텐츠 제작을 위한 장기 지원을 제공합니다.
당신의 창의성이 어디로 이끌든, WaveSpeedAI는 당신의 믿을 수 있는 기초와 신뢰할 수 있는 파트너가 되어 곁에 있을 것입니다.
관련 기사

Seedance 2.0, WaveSpeedAI에 출시 예정: 네이티브 오디오가 포함된 ByteDance의 차세대 비디오 모델

Seedance 2.0 완벽 가이드: 멀티모달 비디오 생성

Seedream 5.0-Preview 완벽 가이드: 지능형 이미지 생성

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 완벽한 비교

Vidu Q3 리뷰: Sora 2, Wan 2.6, Seedance 1.5, Veo 3.1, Grok Imagine Video와의 비교
