WaveSpeedAI × DataCrunch: B200でのFLUXリアルタイム画像推論

WaveSpeedAI × DataCrunch: B200でのFLUX リアルタイム画像推論
WaveSpeedAIはヨーロッパのGPUクラウドプロバイダーDataCrunchと提携し、生成型画像・動画モデルのデプロイメントで画期的な成果を達成しました。DataCrunchの最先端NVIDIA B200 GPUで、オープンウェイト**FLUX-dev** モデルを最適化することで、当社のコラボレーションは業界標準のベースラインと比較して最大6倍高速 の画像推論を提供します。
このブログでは、FLUX-devモデルとB200 GPUの技術概要を提供し、標準的な推論スタックでFLUX-devをスケーリングする際の課題について説明し、WaveSpeedAIの独自フレームワークがレイテンシとコスト効率を大幅に改善することを示すベンチマーク結果を共有します。エンタープライズMLチームは、このWaveSpeedAI + DataCrunch ソリューションがどのようにしてより高速なAPI応答とユーザーあたりの大幅なコスト削減につながるか、そして実世界のAIアプリケーションをどのように強化するかを学ぶことができます。(WaveSpeedAIはZeyi Chengによって設立され、彼は生成型AI推論の加速化に向けた当社のミッションを主導しています。)
このブログはDataCrunch blogにもクロスポストされています。
FLUX-Dev: 最先端の画像生成モデル
FLUX-devは、テキストから画像、画像から画像の生成が可能な最先端(SOTA)のオープンソース画像生成モデルです。その機能には、優れた世界理解とプロンプト適応性(T5テキストエンコーダのおかげ)、スタイルの多様性、複雑なシーンのセマンティクスと構成理解が含まれます。モデルの出力品質は、Midjourney v6.0、DALL·E 3 (HD)、SD3-Ultraなどの人気のあるクローズドソースモデルと同等またはそれを上回る可能性があります。FLUX-devはオープンソースコミュニティで最も人気のある画像生成モデルとなり、品質、汎用性、プロンプト適応における新しいベンチマークを確立しました。
FLUX-devはフロー・マッチングを使用し、そのモデルアーキテクチャはマルチモーダルおよび並列拡散トランスフォーマーブロックのハイブリッドアーキテクチャに基づいています。このアーキテクチャには120億個のパラメータ があり、fp16/bf16ではおよそ33 GBです。したがって、FLUX-devはこの大きなパラメータ数と反復的な拡散プロセスにより計算量が多いです。ユーザー体験が重要な大規模推論シナリオでは、効率的な推論が必須です。
NVIDIAのBlackwell GPUアーキテクチャ: B200
Blackwellアーキテクチャには、第5世代テンソルコア(fp8、fp4)、テンソルメモリ(TMEM)、CTAペア(2 CTA)などの新機能が含まれています。
-
TMEM: テンソルメモリは、レジスタ、共有メモリ(L1/SMEM)、グローバルメモリの従来の階層を補強する新しいオンチップメモリレベルです。Hopper(例:H100)では、オンチップデータはレジスタ(スレッドごと)と共有メモリ(スレッドブロック単位またはCTA単位)を通じて管理され、テンソルメモリアクセラレータ(TMA)経由で共有メモリへの高速転送が行われていました。Blackwellはそれらを保持していますが、SM当たり256 KBのSRAM専用のTMEMを追加 します。TMEMはCUDAカーネルの記述方法を根本的に変更しません(論理的なアルゴリズムは同じ)が、データフロー最適化 のための新しいツールを追加します(ThunderKittens Now Optimized for NVIDIA Blackwell GPUsを参照)。
-
2CTA(CTAペア)とクラスタ協調: BlackwellはCTAペア も導入し、同じSM上の2つのCTAを密に結合する方法を提供します。CTAペアは本質的にサイズ2のクラスタです(1つのSM上で同時にスケジュールされた2つのスレッドブロック、特別な同期機能付き)。Hopperは最大8または16個のCTAがクラスタ内でDSM経由でデータを共有できますが、BlackwellのCTAペアにより、共通データに対してテンソルコアを集合的に使用 できます。実際、BlackwellのPTXモデルは2つのCTAがお互いのTMEMにアクセスするテンソルコア命令を実行することを許可しています。
-
第5世代テンソルコア(fp8、fp4): B200のテンソルコアは著しく大きく、H100のテンソルコアより約2~2.5倍高速 です。高いテンソルコア利用率は、新世代ハードウェアの大幅な高速化を実現するために重要です(Benchmarking and Dissecting the Nvidia Hopper GPU Architectureを参照)。
スパーシティなしのパフォーマンス数値
| 技術仕様 | ||
|---|---|---|
| H100 SXM | HGX B200 | |
| FP16/BF16 | 0.989 PFLOPS | 2.25 PFLOPS |
| INT8 | 1.979 PFLOPS | 4.5 PFLOPS |
| FP8 | 1.979 PFLOPS | 4.5 PFLOPS |
| FP4 | NaN | 9 PFLOPS |
| GPU メモリ | 80 GB HBM3 | 180GB HBM3E |
| GPU メモリバンド幅 | 3.35 TB/s | 7.7TB/s |
| GPU当たりのNVLinkバンド幅 | 900GB/s | 1,800GB/s |
GEMMおよびアテンションのオペレータレベルのマイクロベンチマークは以下の結果を示しています:
- BF16およびFP8 cuBLAS、CUTLASS GEMM カーネル: H100上のcuBLAS GEMMsより最大2倍高速;
- アテンション: cuDNNの速度はH100上のFA3より2倍高速。
ベンチマーク結果は、B200が大規模AIワークロード、特に高いメモリスループットと密集計算を必要とする生成型モデルに非常に適していることを示唆しています。
標準推論スタックでの課題
一般的な推論パイプライン(例:PyTorch + Hugging Face Diffusers)でFLUX-devを実行する場合、H100などの高性能GPUでも、いくつかの課題があります:
- CPU-GPUオーバーヘッドとカーネル融合の欠如による高いレイテンシ;
- GPU利用率の最適化不足 とアイドル状態のテンソルコア;
- 反復的な拡散ステップ中のメモリとバンド幅のボトルネック。
大規模で低コストな推論をサービスする最適化目標は、より高いスループットとより低いレイテンシ であり、画像生成コストを削減します。
WaveSpeedAIの独自推論フレームワーク
WaveSpeedAIは、生成型推論用に特別に設計された独自フレームワークでこれらのボトルネックに対処しています。創業者Zeyi Chengによって開発されたこのフレームワークは、FLUX-dev および**Wan 2.1** などの最先端拡散トランスフォーマーモデル向けに特別に最適化された当社の社内高性能推論エンジンです。推論エンジンの主な革新には以下が含まれます:
- CPUボトルネックを排除するエンドツーエンドGPU実行;
- カスタムCUDAカーネル およびカーネル融合 による最適化実行;
- 高度な量子化と混合精度(BF16/FP8)、Blackwell Transformer Engineを使用しながら最高精度を維持;
- 最適化されたメモリ計画と事前割り当て;
- レイテンシ優先スケジューリング機構、バッチング深度より速度を優先。
当社の推論エンジンはHW-SWコデザインに従い、B200のコンピュートとメモリ容量を完全に活用します。これはAIモデルサービスの大きな飛躍を表しており、本番規模で超低レイテンシと高効率推論を提供することができます。 これらの最適化が出力品質に与える影響を評価し、ロスレス対緩い最適化を優先します。つまり、モデル機能を大幅に低下させたり、テキストレンダリングやシーンセマンティクスなどのように見える出力品質を完全に崩壊させる可能性のある最適化を適用しません。
ベンチマーク: B200上のWaveSpeedAI対H100ベースライン
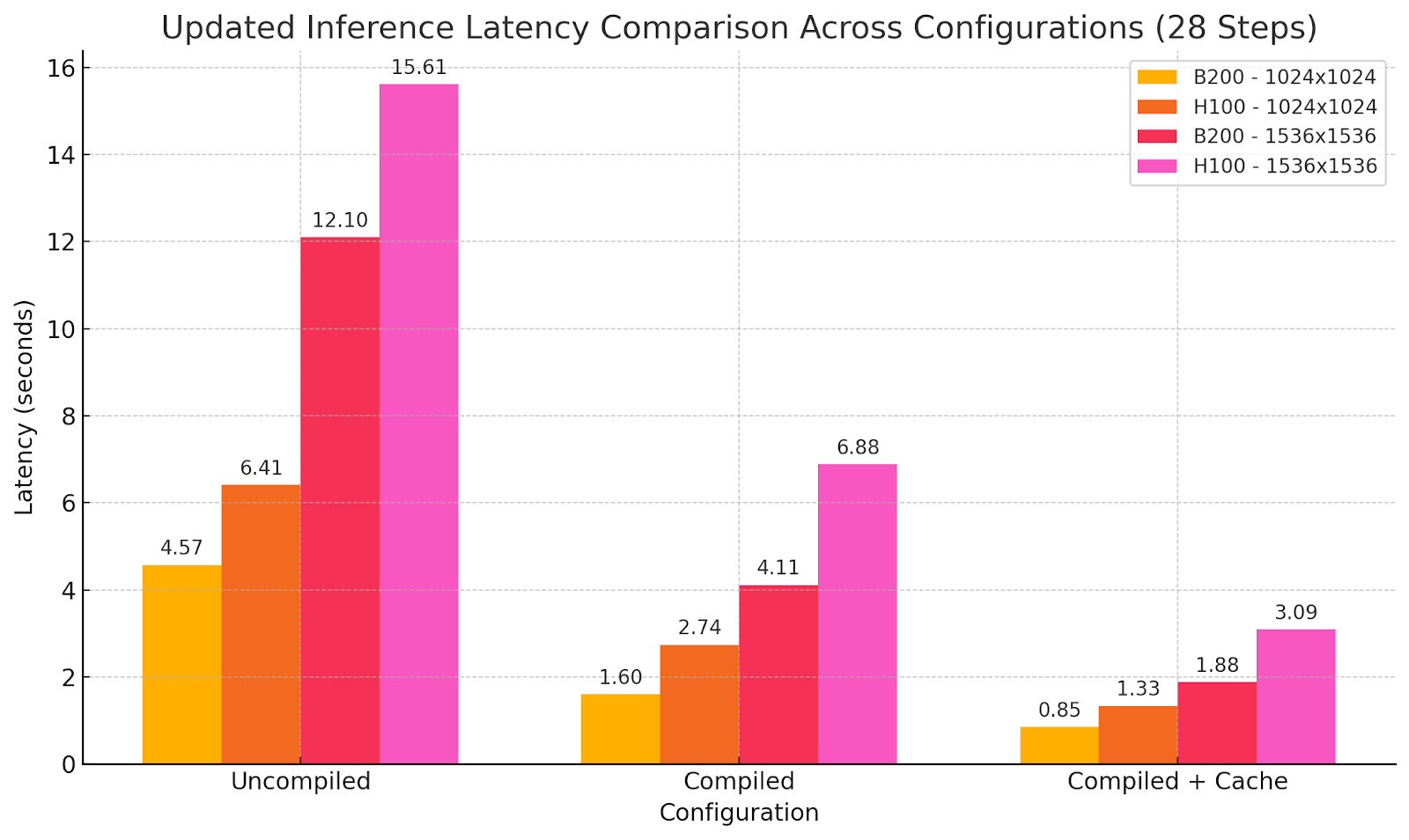
異なる最適化設定を使用したモデル出力:

プロンプト: photograph of an alternative female with an orange bandana, light brown long hair, clear frame glasses, septum piecing [sic], beige overalls hanging off one shoulder, a white tube top underneath, she is sitting in her apartment on a bohemian rug, in the style of a vogue magazine shoot
意味合い
パフォーマンス改善は以下につながります:
- AIアルゴリズム設計(例:DiT活性化キャッシング)および** システム最適化**、GPU アーキテクチャに調整されたカーネルを使用して、HW利用率の向上;
- 推論レイテンシの削減、新しい可能性につながる(例:拡散モデルのテスト時計算);
- 画像当たりのコスト削減、改善された効率とハードウェア利用削減により。
B200がH100コスト性能比と同等ですが、生成レイテンシは半分 を達成しました。したがって、生成あたりのコストは増加しなくなり、モデル機能を犠牲にすることなく新しいリアルタイム可能性を実現できます。時には「より多い」が「より良い」とは限らず、ここでは新しいパフォーマンスのステージを達成し、SOTAモデルを使用した画像生成でユーザー体験の新しいレベルを提供しています。
これにより、大規模の生成型AIで応答性のあるクリエイティブツール、スケーラブルなコンテンツプラットフォーム、および持続可能なコスト構造が実現します。
結論と次のステップ
B200デプロイメントを使用したFLUX-devは、世界クラスのハードウェアが最高級のソフトウェアと出会う時に何が可能かを示しています。WaveSpeedAIでは推論速度と効率の最前線を推し進めており、Zeyi Cheng(stable-fast、ParaAttention、当社社内推論エンジンの創造者)によって設立されました。次のリリースでは、効率的な動画生成推論とほぼリアルタイムの推論をどのように実現するかに焦点を当てます。DataCrunchとのパートナーシップは、B200およびアップコミングのNVIDIA GB200 NVL72(DataCrunchからのプリオーダーNVL72 GB200クラスター)などの最先端GPUにアクセスし、重要な推論インフラストラックスタックを共同開発する機会を表しています。“
今すぐ開始:
世界最速の生成型推論インフラストラクチャを構築する当社と一緒に参加してください。



