WaveSpeedでのバッチ生成:1,000件以上の画像リクエストを毎日自信を持って実行

こんにちは、皆さん!私はDoraです。これは小さな不便から始まりました:テスト用に数百のバリアント画像が必要でしたが、いつもの単一リクエストループは、車輪が引っかかったショッピングカートを押すような感じでした。WaveSpeedのバッチ生成が大量のリクエストに対応できるという話をよく聞きました。派手な機能は必要ありませんでした。ただ、作業がもっと楽に感じてほしかったのです。
そこで12月後半と今週の数回のセッションにかけて、WaveSpeedで単純なバッチパイプラインをセットアップし、1,000以上の画像リクエストを実行させてみました。特別なことはせず、安定したスループット、明確な状態、きれいなリトライで対応しました。以下は、私にとって機能した設定、障害となった部分、そして私の注意がよそに向いている間もコストとエラーが増加しないようにした小さな選択肢についてです。
バッチアーキテクチャの概要
プロデューサー / キュー / ワーカー / ストレージ
わざと各要素をシンプルに保ちました。小さなプロデューサースクリプトがプロンプトとメタデータを集め、キューがジョブを保持し、ステートレスなワーカーがWaveSpeed画像APIを呼び出し、ストレージが結果を保存します。どの部分が失敗しても、システム全体が機能停止することはありません。
- プロデューサー: プロンプトと画像ごとの設定(モデル、サイズ、シード)をCSVから読み込みます。各行に対してアイデンポテンシーキーとソフトデッドラインを付けたジョブをキューに書き込みます。
- キュー: Redis Streamsを1回、RabbitMQを1回使用しました。どちらも機能しました。既に実行していない場合、Redisの方が始めやすいです。
- ワーカー: ジョブを取得し、WaveSpeedを呼び出し、結果をオブジェクトストレージ(S3を使用)に書き込み、ステータスを更新するコンテナ化されたプロセスです。ステートレスなため、スケーリングはノブを回すだけで、再構築は不要です。
- ストレージ: 画像用に1つのバケット、JSONメタデータ用に1つのバケットです。日付とバッチIDでシンプルなフォルダ構成が整理を保ちます。
100から1,200画像にスケーリングしたときに、必要なコード変更がほとんどなかったことに驚きました。ほとんどの問題は、スループットではなく、ペーシングと重複排除についてでした。
シンプルなアーキテクチャ図
ここが私の頭の中にあった図です:
プロデューサー → キュー → ワーカー → WaveSpeed API → ストレージ
↓ ↑
ステート DB ←────────→ メトリクス/アラート- ステート DBは同じRedisまたは軽量なPostgresテーブルにできます。
- メトリクスは、エラー率またはコストが異常になったときにアラートをフィードします。
これは巧妙ではありません。それが重要なのです。APIが間欠的に429/5xxを返すとき、キューがそれを吸収します。ワーカーが実行途中で停止したとき、別のワーカーが可視性タイムアウト後にそれを引き継ぎます。
並行処理戦略
安全な並行レベル
私の実行では、5つのワーカーから始めました。各ワーカーは2つの実行中のリクエストを処理します。これにより、制限に達することなく、1分あたり8~10の画像を安定して生成できました。20の並行リクエストまで増やしたところ、一時的には機能しましたが、リトライがスパイクし始めました。最高の設定は最速のピークではなく、最もフラットな平均でした。
これを試す場合:キューが増加していない最小ワーカー数を見つけてください。次に、徐々に増やします。何かを変更する前に、10~15分間はp95レイテンシーとエラー率を監視してください。
レート制限の認識
WaveSpeedはドキュメントでレート制限のガイダンスを公開していますが、制限はモデルとアカウントによって異なります。2つのガードレールを追加しました:
- クライアント側トークンバケット: 各ワーカーはAPIを呼び出す前にトークンを取得します。トークンはプランの有効RPSで補充されます。モデルを変更したとき、補充レートを調整しました。
- バックオフのルール: 429と5xxはジッターを含む指数バックオフをトリガーし、30秒の上限があります。これにより、短い停止後のスタンピードを防ぎました。
また、各ジョブをモデル+サイズでタグ付けして、必要に応じてモデルごとに個別の並行処理上限を設定できるようにしました。派手ではありませんが、単純なswitch文であり、ローカルなホットスポットを回避するのに役立ちました。
リトライとアイデンポテンシー
重複画像を回避する
最初のバッチには静かなバグがありました:ワーカーはAPI呼び出しが返された後に停止しましたが、ストレージに書き込む前でした。キューはジョブを再試行し、結果的に同じ生成に対して2回支払いました。つらい経験でした。
これを止めるため、ストレージパスをアイデンポテンシーキーと入力ハッシュから決定論的にしました。リトライで画像が既に書き込まれていることが判明した場合、短絡して、ジョブを成功としてマークするだけです。安価な修正、大きな安心。
アイデンポテンシーキーの実装
正規化されたプロンプト+モデル+シード+サイズ+ガイダンスのSHA-256を使用しました。そのハッシュは以下になります:
- APIアイデンポテンシーキー(ヘッダーまたはペイロードフィールドに送信、SDKによって異なります)
- ストレージのファイル名プリフィックス
- ジョブのデータベースプライマリキー
WaveSpeedのAPIがアイデンポテンシーキーを尊重している場合(エンドポイントのドキュメントを確認してください)、同じキーで繰り返した呼び出しは、追加料金なしで同じ結果を返します。そうでない場合、ストレージファースト確認は、2回支払うことになる重複をまだ防ぎます。
失敗したジョブの回復
すべての失敗が別の試行に値するわけではありません。私の経験則:
- リトライ: 429、5xx、ネットワークタイムアウト、「モデルがビジー」、または一時的なストレージエラー
- リトライしない: 検証エラー、欠落パラメータ、または明らかに不正な入力を伴う4xx
リトライは指数バックオフで最大5回に制限しました。その後、ジョブはエラーペイロード付きの配信不可能キューに移動します。1日1回、配信不可能キュージョブをトリアージします。一部は修正された入力で再度キューに入り、その他は注釈付きでアーカイブされます。これにより、1,200画像実行の全体的な失敗率を1.5%以下に保ちました。
ジョブの状態管理
ステータス:pending/running/success/failed
いくつかの状態形状を試しました。最もシンプルなものが固着しました:
- pending: キューに入った、ワーカーにまだリースされていない
- running: ワーカーでリースされた、リース有効期限付き
- success: 画像とメタデータが書き込まれた、チェック完了
- failed: ターミナル、エラーコードと最後の試行タイムスタンプ付き
2つのオプションフィールドを追加しました:attempt_countとlast_response_codeです。これらはダッシュボードをより読みやすくし、デバッグをより詳細にしました。
ジョブのタイムアウト処理
2つのタイムアウトが重要です:
- リースタイムアウト: ワーカーが実行途中で停止した場合、ジョブはN秒後にpendingに戻る必要があります。120秒を使用しました。
- APIタイムアウト: WaveSpeedが N秒で応答しない場合は、中止してバックオフで再試行します。呼び出しあたり60秒を使用しました。
APIが遅い場合、これら2つが対立することがあります。重複を回避するために、リースが期限切れになり、ワーカーのハートビートが停止した後にのみ、running → pendingをマークします。ハートビートは10秒ごとのRedisハッシュ更新でした。ハートビートが新鮮な場合、リースを拡張しました。
監視とアラート
エラー率の追跡
実行中に3つの数値を監視しました:
error_rate_5m:失敗した試行の5分間のローリング比率p95_latency:モデルおよびサイズごとretry_depth:試行≥2のジョブの数
10分間、error_rate_5m > 5%の場合、並行処理を自動的に半分に減らし、自分自身にメモを送信します。ほとんどのスパイクは、手動操作なしで5分以内に落ち着きました。
コストスパイクアラート
コストは忍び寄ることができます。私は以下を記録しました:
- cost_per_image: WaveSpeedから報告(利用可能な場合)、そうでなければプランから推定
- duplicate_prevented: ストレージ短絡回数
- total_estimated_cost: 累積
cost_per_imageが直近1時間の平均から30%以上増加した場合、新しいジョブの受け入れを一時停止し、キューがドレーンするのを待ちました。2回、これが意図しないパラメータ変更(より大きなサイズ、別のモデル)をキャッチして、請求書が発散する前に防ぎました。これのような静かなガードレール、わずかなコード行分の価値があります。
参考実装
Pythonの疑似コード
以下は、私が使用した設定です。完全なコードではなく、骨組みです:
# producer.py
for row in csv_rows:
key = hash_inputs(row)
job = { "id": key, "inputs": row, "deadline": now+6*3600 }
queue.push(job)
# worker.py
while True:
job = queue.lease(timeout=120)
if not job:
sleep(1)
continue
try:
record_heartbeat(job.id)
resp = wavespeed.generate_image(inputs=job.inputs, idempotency_key=job.id, timeout=60)
path = storage_path(job.id, job.inputs)
if not storage.exists(path):
storage.write(path, resp.image)
storage.write(path+'.json', resp.metadata)
mark_success(job.id)
except Retryable as e:
mark_retry(job.id, e)
backoff_sleep(job.attempt)
except Fatal as e:
mark_failed(job.id, e)
finally:
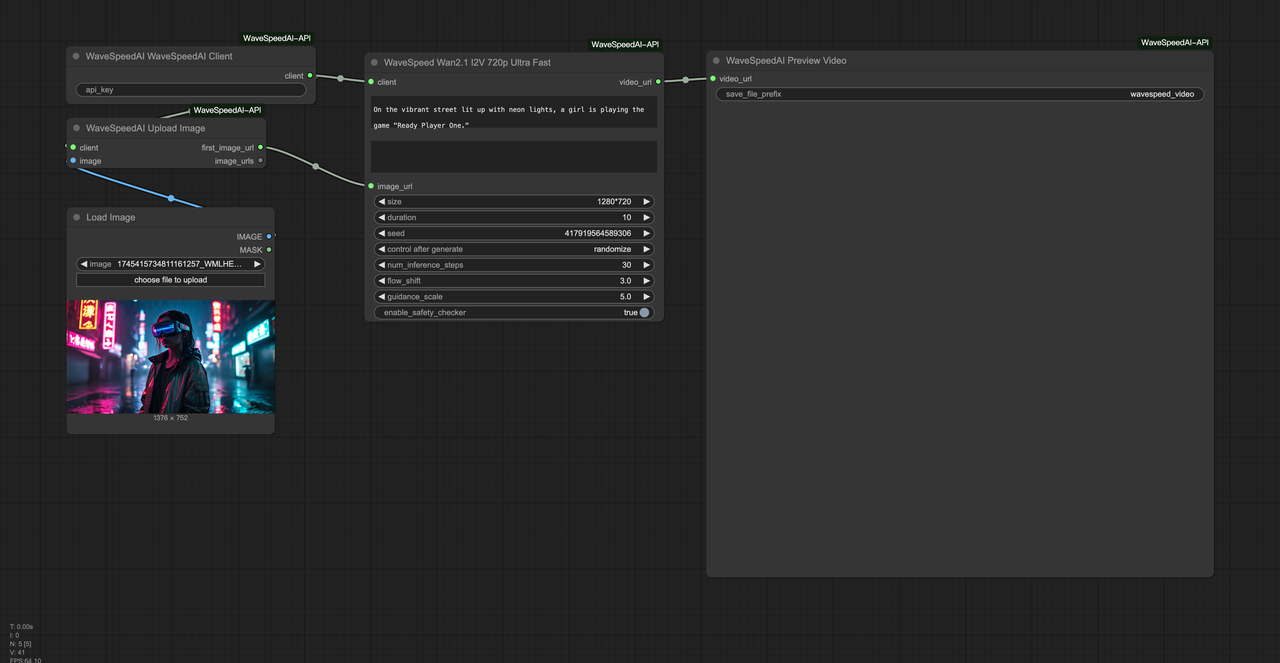
queue.release(job)Node.jsの疑似コード
// producer.mjs
for (const row of rows) {
const key = hashInputs(row);
queue.push({ id: key, inputs: row, deadline: Date.now() + 6 * 3600e3 }); // 6時間
}
// worker.mjs
while (true) {
const job = await queue.lease(120); // リースタイムアウト(秒)
if (!job) {
await delay(1000);
continue;
}
try {
await heartbeat(job.id);
const resp = await wavespeed.generateImage(
{ ...job.inputs, idempotencyKey: job.id },
{ timeout: 60000 } // 60秒
);
const path = makePath(job.id, job.inputs);
if (!(await storage.exists(path))) {
await storage.write(path, resp.image);
await storage.write(path + '.json', resp.metadata);
}
await markSuccess(job.id);
} catch (e) {
if (isRetryable(e)) {
await markRetry(job.id, e);
} else {
await markFailed(job.id, e);
}
} finally {
await queue.release(job);
}
}設定の推奨事項
- 小さく始める: 5~10の並行リクエストから始めて、徐々に増やします。スループットだけでなく、
p95とerror_rate_5mを監視してください。 - モデルごとに個別設定: 並行処理、タイムアウト、コスト期待値はモデルとサイズによって変わります。
- あらゆるところにアイデンポテンシー: リクエスト内のキー、決定論的なストレージパス、および同じ値でキーに設定されたジョブテーブル。
- ハートビートとリース: うるさく聞こえるかもしれませんが、ファントム重複から救ってくれます。
- シンプルなダッシュボード: 6~8パネルで十分です。キュー長、成功/分、エラー/分、p95、リトライ深度、コスト。
既に他の場所でバッチジョブを実行している場合、これは馴染みがあるはずです。WaveSpeedは再検討を必要とせず、いくつかの注意深いガードレールが必要なだけです。それが私の望んでいたものでした。

実行からの最後の注意:最もスムーズなバッチは、ほとんど監視しなかったものでした。「セットして忘れる」わけではなく、システムが注意を必要としたときにそれを知らせ、必要がないときは静かにしていたからです。それは正しい種類の速さのように感じます。
あなたはどうですか?最近WaveSpeedで画像をバッチ処理していますか?並行処理の最適なレベルは何ですか(私は現在一貫して8~10の周辺です)?隠れたバグ(重複料金など)に遭遇しましたか?コメントで設定、落とし穴、またはヒントを自由に共有してください。
関連記事

Seedance 2.0がWaveSpeedAIに登場予定:ネイティブ音声対応のバイトダンス次世代ビデオモデル

Seedance 2.0完全ガイド:マルチモーダルビデオクリエーション

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1:究極のAIビデオ生成モデル比較

Seedream 5.0-Preview完全ガイド:インテリジェント画像生成

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 完全比較
