WaveSpeed APIでGLM-4.7-Flashにアクセス

私はDoraです。きっかけは小さなイライラでした。またしても別のプロジェクト、また別のAPIキー、トークンやリトライについて独自の考えを持つ別のSDK。私はGLM-4.7-Flashを試してみたかったのです。みんなが日常的なドラフティングと迅速なリサーチのためのスピードについて述べていたからです。でも、スタックを作り直してテストを実行するだけのことはしたくありませんでした。
そこで、より静かなアプローチを試しました。WaveSpeed APIを経由してGLM-4.7-Flashにアクセスする。同じクライアントパターン、1つのキー、モデルを切り替える。2026年1月にこれをいくつかのスクリプト全体でテストして、ノートを保管しました。これらは何も劇的ではありません。しかし、確実に日常をもう少し軽くしてくれました。正直なところ、それが今のスタンダードです。派手さより軽さが勝つ。
WaveSpeedを使う理由
WaveSpeedが魔法だと言うつもりはありません。むしろ、信頼できるアダプター引き出しのようなものです。退屈ですが、仕事を進めたいときに手を伸ばすものです。
私にとって重要だったのはモデル数ではなく、摩擦がないことでした。同じコードを異なるモデルに向けることができ、1行切り替えて進める。それだけ、ドラマはありません。
1つのAPIキーで600以上のモデル
本当の勝利は精神的なものでした。プロバイダーダッシュボードを回ってキーをローテーションしたり支出をキャップしたりしていません。シークレットマネージャーに1つのキーを入れれば、GLM-4.7-Flashにルーティングして高速ドラフトを作成し、プロンプトがより深い処理を必要とするときにより重いモデルにホップできます。プロジェクトごとの制限は依然として設定しますが、オーバーヘッドが減ります。
実際には、既存の環境変数(この場合、WAVESPEED_API_KEY)を保管しておき、モデル名だけを変更しました。その小さな決定(名前を揃えておく、賢いことではない)により、CIを壊すことを避けることができました。
SDKの切り替えなし
私は、既に使用しているOpenAI互換クライアントに留まりました。新しいメソッド名も、ストリーミングフラグの再学習もありません。チャット補完、ストリーミング、ツール呼び出しの周りに小さなユーティリティを構築した場合、ほとんどが転用できます。WaveSpeedがトークンを返す前に独自の世界観を採用するよう求めないことが気に入っています。意味が分かれば。
注目した2つの注意点:
- モデル名はプロバイダー間で異なります。コードをコミットする前に、公式WaveSpeedドキュメントで正確な識別子を確認します。
- プロバイダー固有の機能(特別な応答形式や関数呼び出しの癖など)は依然として異なる場合があります。ペイロードを正規化するための小さなアダプターファイルを保管しておきましょう。私のものは60行で、毎週家賃を払っています。
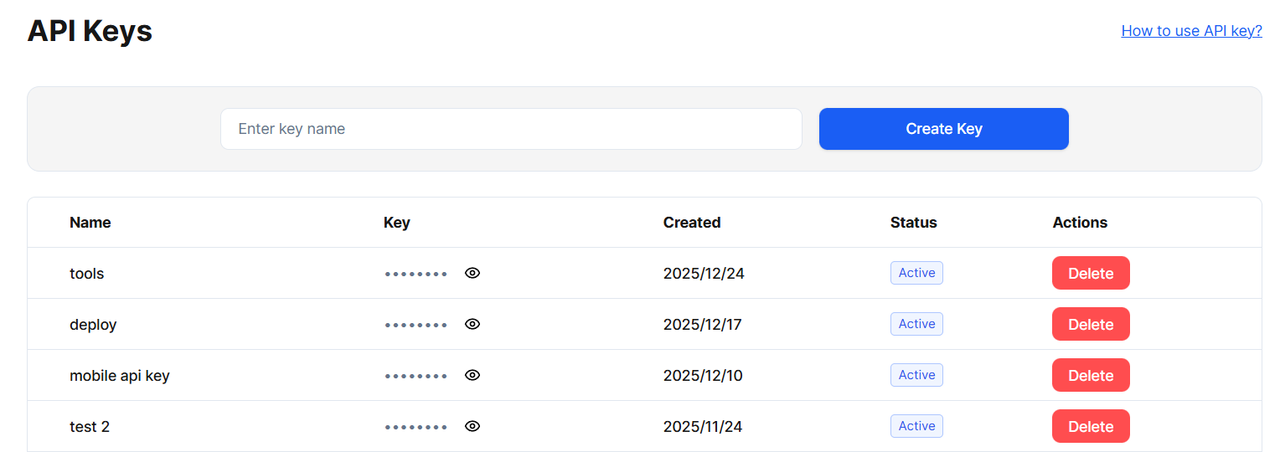
クイックスタートコード
WaveSpeedが公開するOpenAIスタイルのエンドポイントを使用しました。コードが既にチャット補完APIにアクセスしている場合、これは馴染み深いはずです。唯一の実際の変更は、ベースURLとモデル名です。
2026年1月12~15日に小規模なバッチプロンプトでこれをテストしました。短いプロンプトは、私の接続で1秒未満でストリーミングを開始しました。当然のことながら、ネットワーク、プロンプトサイズ、サーバー負荷により、体験は異なります。
ドロップイン置換例
使用した形状です。最新のモデル識別子については公式WaveSpeedドキュメントをご覧ください(glm-4.7-flashとしてリストされているのを見たことがあります)。
Node.js (fetch):
const resp = await fetch("https://api.wavespeed.ai/v1/chat/completions", {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${process.env.WAVESPEED_API_KEY}`
},
body: JSON.stringify({
model: "glm-4.7-flash",
messages: [
{ role: "system", content: "You are a concise assistant." },
{ role: "user", content: "Summarize this link in 3 bullets: https://example.com/post" }
],
temperature: 0.3,
stream: true
})
});Python (requests):
import os, requests
url = "https://api.wavespeed.ai/v1/chat/completions"
headers = {
"Authorization": f"Bearer {os.environ['WAVESPEED_API_KEY']}",
"Content-Type": "application/json",
}
payload = {
"model": "glm-4.7-flash",
"messages": [
{"role": "system", "content": "You are a concise assistant."},
{"role": "user", "content": "Outline a 5-step plan to vet a research source."}
],
"temperature": 0.2
}
r = requests.post(url, headers=headers, json=payload, timeout=30)
r.raise_for_status()
print(r.json()["choices"][0]["message"]["content"])役立つと思った小さなメモ:
- アプリがトークンをストリーミングする場合、同じSSE解析を実行してください。WaveSpeedのストリームフラグは私のテストで期待通りに動作しました。
- モデル負荷が不確かな場合は、リクエストごとのタイムアウトを通常より少し高く設定します。
- レスポンスにモデル名をログします。将来のあなたは、出力がずれて実行内容を確認する必要がある場合に感謝するでしょう。
他のモデルと組み合わせ
ほとんどの仕事はモデルを混ぜています。GLM-4.7-Flashは最初のパス、ドラフティング、要約、基本的な質問応答のための高速です。より重い推論や特定の機能(強力なコード解釈器や特定のビジョン機能など)が必要な場合は、他の場所にルーティングします。WaveSpeedにより、そのルーティングを1か所に保管できます。
少し驚いたことは、実行中にモデルを切り替えるのが面倒に感じるだろうと予想したことです。そうではありませんでした。プロンプトは同じ形を保ったため、コードを曲げずに出力を比較できました。
テキスト+画像ワークフロー
小さなルーチンを試しました。ユーザーレポートからスクリーンショットを収集し、軽いOCRまたはビジョンキャプションを実行してから、GLM-4.7-Flashに平易な言語でアクション要約を作成するよう依頼します。
私のステップ:
- ビジョン対応モデルを使用して、画像からテキスト/ラベルを抽出します。出力をコンパクトに保つ、キーと値のペアまたは短いポイントについて考えてみましょう。
- そのテキストをGLM-4.7-Flashに安定したシステムプロンプト(2行)で提供し、決定を含む短い要約をリクエストします。
- 画像にテーブルがある場合は、簡単なルールを追加します。「数字と単位を正確に保存してください。」これにより、後でのクリーンアップが減りました。
フィールドノート:
- 混合されたUI+テキストを含む1.2MB PNGで、ビジョンパスは私にとって約2~4秒かかりました。GLM-4.7-Flashの要約は1秒以下で返ってきました。その分割により、フローは快適に感じられました。
- コストは予測可能でした。ビジョン出力を数百トークンに制限してから引き渡したからです。
- ビジョンのニュアンスが必要ない場合は、まず基本的なOCR(Tesseractまたは有料OCR API)を実行してから、テキストをGLM-4.7-Flashに渡します。より安い、多くの場合十分です。
テキスト+ビデオワークフロー
ビデオは当然、より重いです。私は完全なビデオをどのモデルにも送信しませんでした。最初にトランスクリプト(whisperまたは有料ASR)を引き出し、セクションをGLM-4.7-Flashにルーティングして高速要約を実行しました。
動作したループ:
- ビデオを一度トランスクライブします。可能であれば、タイムスタンプを保管しておきます。
- スピーカーターンまたは3~5分のセグメント(どちらかがクリーナー)でチャンクします。
- GLM-4.7-Flashにセグメント要約と決定をリクエストします。システムプロンプトを固定したままにしておきます。「フィールドA/B/Cを使用してのみ構造化JSONを返します。」
- 2番目のパスでセグメントからトップレベルのアウトラインを縫い合わせます。
実際には、GLM-4.7-Flashはセグメント要約に適切に感じられました。迅速で、摩擦が少なく、計画のための十分な精度です。最終的なアウトラインのために、時々トーンやニュアンスのためにモデルを切り替えました。すべてをWaveSpeed内に保管したため、コードは形を変えませんでした。
価格
価格は減速です。複雑だからではなく、驚きはダッシュボードではなくログに表示されるからです。
WaveSpeed上のGLM-4.7-Flash

2026年1月の時点で、GLM-4.7-FlashはWaveSpeedを通じて独自のトークン当たりレートで利用可能です。正確な数字は変動する可能性があるため、ここではピン留めしません。本番にプッシュする前に公式価格ページを確認し、環境設定でソフト制限を設定します。
推定方法:
- 典型的なプロンプト+応答をサンプリングします。毎日の実行回数を掛けます。これで日々のトークンに到達します。
- 悪い日や新しいプロンプトのために20~30%の余裕を追加します。
- 同じタスク向けに遅いが安価なモデルと比較します。遅いモデルが人間の編集時間を増加させない場合、全体的に勝つかもしれません。
実用的なトリック:機能フラグでトークンをログします。ユーザーのスライスのGLM-4.7-Flashをオンにして、編集時間と苦情を比較します。それは価格表より多くを教えてくれます。
ボリュームディスカウント
WaveSpeedはボリュームベースの価格を提供しています。階層は、バッチジョブを実行するか、データバックフィルを実行する場合に重要です。スパイク週の前に閾値を確認するために一度連絡しました。答えは簡潔で、厄介なウィンドウで作業を絞ることから救ってくれました。
私のルール。10倍のバースト、キャンペーン、マイグレーション、または研究スプリントを期待する場合、最初にサポートにメールを送ります。特別な取引を取得することは重点ではありません。それは明確な上限であり、夜間に仕事を監視していないため、誰もそれを望んでいません。
私たちはWaveSpeedをこの種のワークフロー向けに正確に構築しました。より少ないキー、より少ないSDK切り替え、インフラストラクチャについての思考に費やす時間が少なくなります。モデルを必死に使っていて、単一の予測可能なAPIの背後で動作させたいだけの場合、それは私たちが解決しようとしている問題です。
➡️ここで探索できます。
今度はあなたの番です。最近対処した最も馬鹿馬鹿しいAPIキーサーカスは何ですか?コメントで述べてください。コーヒーを飲みながら読み、少し一人ではないと感じます。
関連記事

Seedance 2.0がWaveSpeedAIに登場予定:ネイティブ音声対応のバイトダンス次世代ビデオモデル

Seedance 2.0完全ガイド:マルチモーダルビデオクリエーション

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1:究極のAIビデオ生成モデル比較

Seedream 5.0-Preview完全ガイド:インテリジェント画像生成

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 完全比較
