GLM-4.7-FlashとGLM-4.7:どちらがあなたのプロジェクトに適していますか?

こんにちは、友人たちへ。私はDoraです。これが聞き覚えのあるものなら、あなただけではありません。私はそこにいました。小さくて繰り返しの多いプロンプトのキューを見つめて、素早く確実な返答が必要だったのに、複雑な、複数ステップの推論タスクが隅の方に座って、静かにずっと高い処理能力を要求していました。
だから私はついに声を出して質問を投げかけました。軽量で閃光のような高速なGLM-4.7-Flashが実際に輝くのはどこか、そしてどこでより重く、より慎重なGLM-4.7を持ってくる必要があるのか。これは私が到達した率直で、何の誇大広告もない答えです。実際の実行、重要なベンチマーク、そして日々のスタックを目に見えて軽くする静かな目標に基づいています。「ここで本当にどのモデルを使うべき?」と立ち止まったことがあるなら、これはあなたのためです。
30秒での答え
スピードと低コストがあなたの主要なレバーなら、GLM-4.7-Flashは適切に感じるでしょう。あなたの仕事が推論の深さ、ツール、またはより高い忠実度の出力に依存しているなら、GLM-4.7がより安定した選択肢です。残りはレイテンシ予算、コンテキストサイズ、およびあなたのプロンプトが圧力の下でどのように動作するかに関する細微な違いです。
Flashを選びます…
Flashは「弱い」のではなく、それが得意なことについて非常に正直なだけです。
- 多くの小さなジョブを送出する:要約、タグ、ドラフト、迅速な変換。
- レイテンシが品質の最後の10%を絞り出すことよりも重要です。
- 実験、プロトタイピング、または即座に感じるべきUIインタラクションを構築しています。
- 長い推論ステップでの時折のぐらつきがあなたを脱線させません。
- より安い デフォルトモデルが欲しく、必要な場合にのみGLM-4.7にエスカレートできます。
GLM-4.7を選びます…
これは「これを台無しにしないでください」モデルです。
- コードの信頼性、複数ステップの推論、またはツール使用の精度を気にします。
- プロンプトが長く、指示が厳格で、出力が一貫している必要があります。
- 評価器、テスト、またはワークフローを実行しており、1つの間違いは高くつきます。
- コード作成とロングコンテキストタスクでより強力な結果が必要です。
- より良い結果のためにより高いコストと少し多くのレイテンシを許容できます。
アーキテクチャの違い
 私はスポーツのためにパラメータカウントを追いませんが、アーキテクチャは動作の多くを説明しています。なぜ1つのモデルはテキパキしていて、もう1つは思慮深く感じるのか。
私はスポーツのためにパラメータカウントを追いませんが、アーキテクチャは動作の多くを説明しています。なぜ1つのモデルはテキパキしていて、もう1つは思慮深く感じるのか。
パラメータカウントとアクティブエキスパート
GLM-4.7は、より大きなバックボーンで実行され、(公開ノートから)推論を優先するエキスパートルーティングを使用しているようです。Flashはスループット用に調整されており、ルーティングが軽く、トークンあたりのアクティブなエキスパートが少なく、激進的な効率設定があります。実際には、それは次のように傾向があります:
- Flash:トークンあたりの低い計算、高速な最初のトークン時間、ですがストレス下で推論チェーンをドロップできます。
- GLM-4.7:トークンあたりのより多くの計算、より安定した推論パス、より優れたツール呼び出し選択。
プロバイダ図をざっと見ると、混合エキスパート(MoE)とアクティベーション疎性のヒントが表示されます。正確な数値はバージョン全体で漂うので、それらを絶対的ではなく方向性的として扱います。大きなアイデア:Flashはトークンあたり少ない「思考」を費やすので、より早く移動します。GLM-4.7はより長く考え、エッジケースでより少なく転びます。
コンテキストウィンドウと出力制限
見出しのコンテキスト数よりも、より実際的な2つの質問が重要です:
- 長いプロンプトにどのくらい深く入っても品質は保たれるのか?
- 出力が長くなったとき、モデルはスレッドを失いますか?
Flashは通常、健全なコンテキストウィンドウを宣伝していますが、非常に長いプロンプトまたは密度の高い指示では品質が早くテーパーします。GLM-4.7は、長いコンテキストに深く一貫性を保ち、長い出力の構造にもっと従順なままです。知識ベースを詰め込む場合は、GLM-4.7がより安全なデフォルトです。入力をチャンク化するか、取得を使用してプロンプトをスリムに保つ場合、Flashはしばしば十分です。そしてはるかに高速です。
ベンチマーク比較
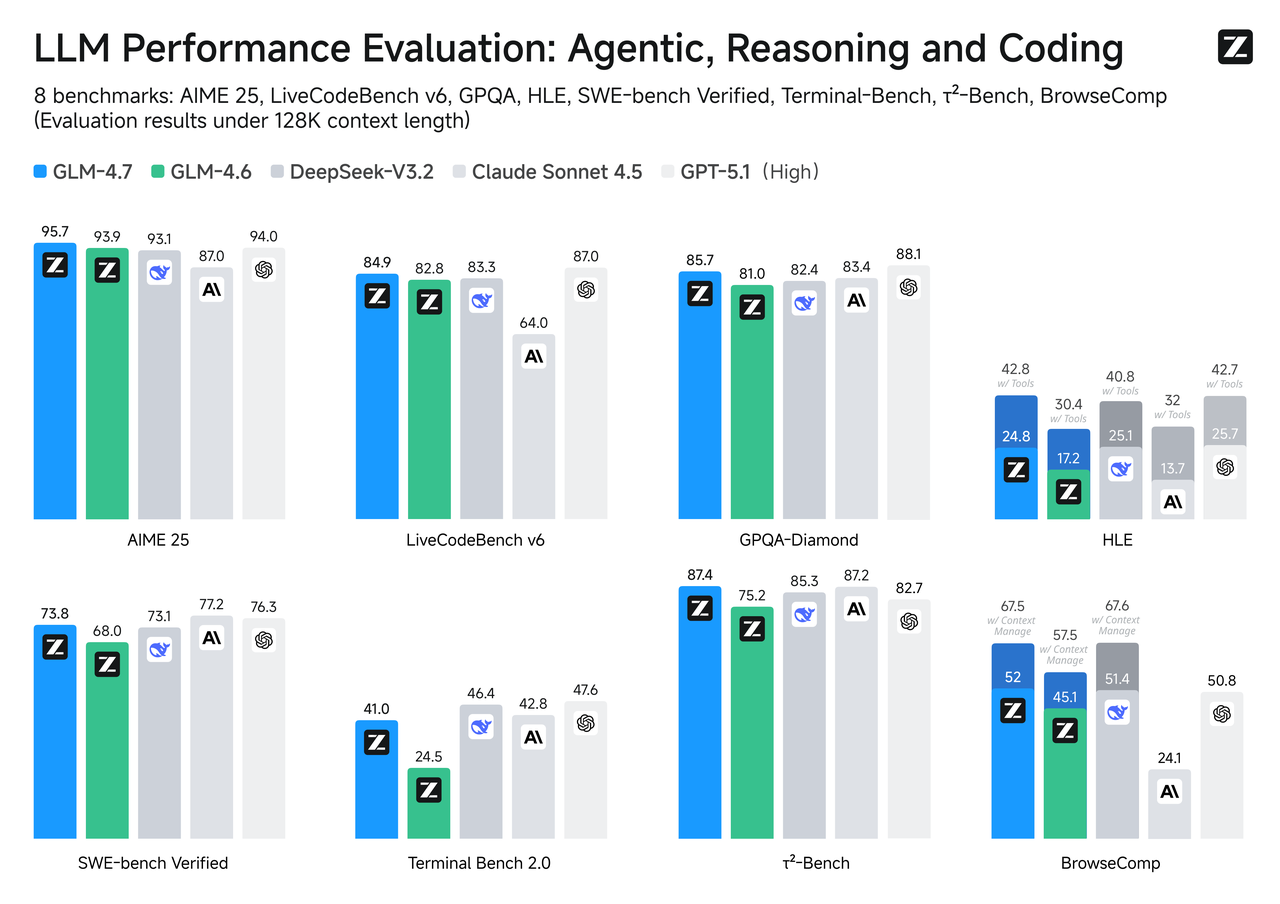 ベンチマークはすべてのストーリーではありませんが、特にあなたのユースケースが課題と一致する場合、それは有用なコンパスです。
ベンチマークはすべてのストーリーではありませんが、特にあなたのユースケースが課題と一致する場合、それは有用なコンパスです。
SWE-bench検証済み
実際にコンパイルしてテストに合格する必要があるコード変更の場合、GLM-4.7はFlashの兄弟姉妹を上回る傾向があります。これは、推論の深さとツール使用のために調整されたモデルから何を期待するかと一致します。Flashはフィックスをドラフト化し、コードをうまく説明できますが、パッチがファイル全体で複数の調整を必要とする場合、GLM-4.7はステップをドロップせずにチェーンに従う可能性が高いです。
パイプラインに自動PRまたは修復ループが含まれる場合、小さなサンプルで最初に健全性チェックする価値があります。違いは複数ホップの問題では単一ファイルの微調整よりも目立ちます。
LiveCodeBench / τ²-Bench
ライブまたは時間回転コーディングベンチマークでは、GLM-4.7はその重い推論予算を考慮するとトップティアに近い傾向があります。スピード用に最適化されたFlashは、階層が低いですが、すばやく応答します。あなたの製品がインタラクション速度よりもコード合成品質に依存している場合は、GLM-4.7は保守的な選択肢です。コードがアドバイザリーである場合(とにかく確認します)応答性が重要な場合、Flashは正しいトレードです。
スピードとレイテンシ
これはスプリットが最も明確に感じるところです。Flashはしばしば最初のトークンを目に見えて高速に返し、最後のトークンまでの総時間は短い出力と中程度の出力に低いままです。高いトラフィックの小さな呼び出しやUIへのストリーミングを実行している場合、これは追加されます。
GLM-4.7は遅く開始し、より重く実行されますが、長い生成と複雑なツール呼び出しシーケンスでより安定しています。より少ない停止、より少ない奇妙な迂回、関数スキーマへのより良い遵守が表示されます。
システムを構築している場合:
- 高トラフィックのUXモーメント用にFlashを使用:オートコンプリート、迅速な要約、インラインヘルプ。
- スローレーン用にGLM-4.7を使用:評価器、コードアクション、ポリシーチェック、最終パス。
シンプルなルーティングルール、多くの場合、それ自体を支払います。Flashで開始、信頼度が下がるか閾値が超えられたときにGLM-4.7にエスカレート。ルールを決定させるため、あなたはそうする必要がありません。
価格内訳
価格設定は地域とプロバイダによって異なるため、数値を移動目標として扱い、構造を安定させたままにしておきます。
Flash無料層対GLM-4.7従量制課金
-
Flash:多くのプラットフォームはFlashのようなモデルに無料またはロー費用ティアを公開し、フラグシップモデルと比較して寛大なレート制限があります。プロトタイピング、バックグラウンドタスク、UIポーリッシュに優れています。
-
GLM-4.7:通常、より高いレートでトークンごとに請求。重要なタスクでより良い費用対効果ですが、デフォルトのままにしておくと簡単に過支出できます。
 実用的なヒント:
実用的なヒント: -
デフォルトで出力トークンをキャップします。それが必要なルートでのみキャップを上げます。
-
取得を使用してプロンプトを短く保つ:コーパス全体をウィンドウに注ぎません。
-
決定論的サブ結果(正規表現マップ、スキーマスニペット、数ショットブロック)をキャッシュして、再度支払わないようにします。
-
ルートごとにトークンコストをログします。あなたが実際に読むレポートは、最も多くのチャートを持つレポートではなく、週間ワークフローに座っているレポートです。
疑わしい場合は、安く開始し、測定し、プロモートします。エスカレーション は楽観主義を打ちます。
ユースケース別に選択
目標が頭痛が少ないときに、私はそれらをどのようにスロットするかです:
- 高チャーン コンテンツオペレーション(スニペット、件名行、メタデータ):Flash。利益はスループットと低コストでの一貫性です。
- サポートマクロとクイックトリアージ:最初にFlashを実行し、検出が複雑性またはポリシーリスクをフラグした場合、GLM-4.7にエスカレート。
- 研究ノート、合成、構造化要約:スキムのFlash。ソース忠実度と適切にスキャフォルドされたなければならないパスのGLM-4.7。
- コード支援:説明と「これは何をしていますか?」のFlash。複数ファイル編集、マイグレーション、テスト認識変更のGLM-4.7。
- データクリーンアップと変換:Flashは単純なマッピングにとって問題ありません。厳格なスキーマ、検証、複数ステップ結合のGLM-4.7。
- エージェントとツール使用:GLM-4.7。より信頼できる関数引数と少ないリトライを取得します。
- ロングコンテキスト読み取りまたはドキュメント接地QA:ウィンドウを押している場合はGLM-4.7。チャンクをリーンに保つ場合はFlash。
私が閉じておく数フィールドノート:
- 短いプロンプトは違いを隠します。指示が密度の高いまたは出力が構造に従う必要があるときに、ギャップが表示されます。
- ルーティングは役に立ちます。単純なルール「Flashプロンプト > Nトークン、その後GLM-4.7」でも、ドラマなしにお金を節約します。
- ガードレールは繰り返しタスクのモデル選択よりも重要です。検証、リトライ、小さなチェッカーは下流の混乱を防ぎます。
- スピードを崇拝しないでください。1秒未満は「インスタント」のように感じます。その後、安定した動作は100msを削ること を上回ります。
なぜこれが重要か:ツールは精神的負荷を減らすときに年をとります。Flashは小さなもの を軽くします。GLM-4.7は重い箱を運びながらドロップしません。ほとんどのスタックは両方が必要です。
確信が持てない場合は、Flashをデフォルトとして開始し、GLM-4.7用にクリアなレーンを作成します。気分ではなく、ルートを決定させます。マイレージは異なる場合があり、それは問題ありません。
静かな日に、このスプリットが決定疲労をどのように軽減するか、依然として気づいています。目がくらむようなものではありません。単に頭痛が少なくなります。
実践でこのスプリットを実際にどのように実行するか
 高速なジョブをFlashにルーティングし、ヘビーなジョブをGLM-4.7にエスカレートする必要があるときに、スクリプトを監督せずに、WaveSpeed(私たち自身のプラットフォーム)を使用します。
高速なジョブをFlashにルーティングし、ヘビーなジョブをGLM-4.7にエスカレートする必要があるときに、スクリプトを監督せずに、WaveSpeed(私たち自身のプラットフォーム)を使用します。
モデル切り替え、同時実行、バッチ呼び出しをきれいに処理するために構築されたため、「Flash first、必要なときにエスカレート」パターンは脆いのではなくシンプルなままです。
多くの小さな呼び出しを実行していて、ルーティングロジックを維持することが別の問題にならないようにしたい場合は、Wavespeedを試してください!
FAQ:GLM-4.7-FlashとGLM-4.7
1. GLM-4.7-FlashとGLM-4.7の主な違いは何ですか?
GLM-4.7-FlashはGLM-4.7の軽量で最適化されたバリアントです。アクティブなエキスパートの数を減らし、ルーティングを簡略化し、効率のツイークを適用することで、より高速な推論とより低いコストを実現します。GLM-4.7は、より大きなバックボーンとより強力な推論機能を保持し、複雑な複数ステップの推論、ロングコンテキストの一貫性、正確なツール呼び出しで優れています。
簡潔に言うと: Flashはいくつかのインテリジェンスをスピードのためにトレードします。GLM-4.7は深さと信頼性を優先します。
2. どのモデルが高速で、速度の違いが最も顕著なシナリオはどれですか?
GLM-4.7-Flashは、大幅に低い最初のトークンまでの時間(TTFT)とトークンあたりのレイテンシを持っています。リアルタイムUIインタラクション、コンテンツ要約、メタデータ生成、迅速なプロトタイピングなどの高スループット、低レイテンシのユースケースで輝いています。
GLM-4.7はより高い起動オーバーヘッドと重い計算を備えていますが、長い出力または複雑なツール呼び出しシーケンスではより安定しています。実際には、Flashは短い~中程度の出力(500トークン未満)で著しく高速です。
3. 知性と推論が強いのはどのモデルですか?
GLM-4.7は、複数ステップの推論、コード信頼性、ツール使用、ロングコンテキストタスクでFlashを上回ります。例:
- SWE-bench検証済み: GLM-4.7は複数ファイルのコード編集と調整されたパッチで主導しています。
- LiveCodeBench / τ²-Bench: GLM-4.7は、特に深い推論シナリオで、高品質のコードを提供します。
Flashは人間レビューを許容する単一ファイル編集またはアシスティブタスクに適していますが、長い推論チェーンまたは密度の高いプロンプトでは、より早く低下します。
4. コンテキストの長さと出力制限はどのように比較されますか?
両方のモデルは同様のコンテキストウィンドウを共有していますが、GLM-4.7は非常に長いコンテキスト(> 32kトークン)または密度の高いプロンプトでより良い一貫性と指示追従を維持しています。Flashは極端なプロンプト長または密度の下でより迅速に低下します。最良の結果を得るために、チャンキングまたはRAGと組み合わせてください。
5. 価格設定とコスト制御に基づいて選択するにはどうすればよいですか?
GLM-4.7-Flashは通常、Flashのようなモデルに対してより高い無料クォータとより低い(またはゼロ)トークンごとの価格設定を提供し、プロトタイピング、バックグラウンドタスク、および高ボリュームの低リスク呼び出しに理想的です。GLM-4.7はより高いトークンあたりのコストがありますが、重要なタスクに対してより良い価値があります。
推奨: Flashをデフォルトにして、複雑な作業のためにGLM-4.7にエスカレートし、常にトークンキャップとキャッシングを設定して、過支出を防ぎます。
関連記事

Seedance 2.0がWaveSpeedAIに登場予定:ネイティブ音声対応のバイトダンス次世代ビデオモデル

Seedance 2.0完全ガイド:マルチモーダルビデオクリエーション

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1:究極のAIビデオ生成モデル比較

Seedream 5.0-Preview完全ガイド:インテリジェント画像生成

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 完全比較
