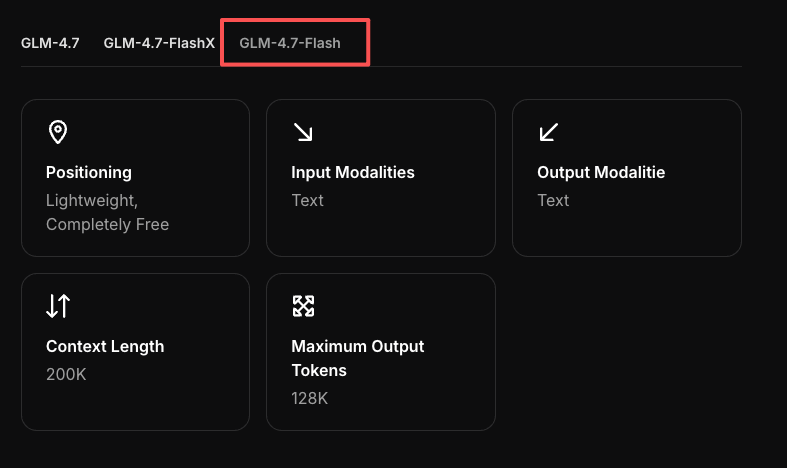
GLM-4.7-Flash API: チャット補完とストリーミングのクイックスタート

どうも、ドーラです。先週ちょっとした壁にぶつかりました。下書きの要約タスクが思いの外重く感じられたんです。いつも使うツールは、どれも遅すぎるか、賢すぎて邪魔になってしまうかのどちらかでした。派手さはなくていいから、速くて予測可能なものが欲しかった。
そこでGLM-4.7-Flash APIをちゃんと試してみました(2026年1月)。「わぁ」という感動は求めていませんでした。クリーンなリクエスト、素早いレスポンス、そして設定がどおりに動くことが欲しかったんです。ここにセットアップしたもの、役に立ったこと、上手くいかなかったこと、そして速さがドラマを呼ばないときに改めて使いたい理由をお話しします。
APIキーを取得する
シンプルに始めました。キーを取得して、リクエストを送って、基本がまともに機能するか確認する。レバーを隠さないAPIは好きです。背景として、GLM-4.7-FlashはZhipu AIが提供する幅広いGLMモデルファミリーの一部で、速さと予測可能性をめぐる多くの設計判断を形作っています。

WaveSpeedダッシュボード徹底解説
WaveSpeedダッシュボードを使いました。GLM-4.7-Flash APIへのアクセスをラップしています。フローは単純でした。
- プロジェクトを作成する(「flash-notes」と名付けました)。
- サーバーキーと軽量なクライアントトークンを生成する。ローカルスクリプトではサーバーキーのみを使いました。
- 使用パネルをざっと見て、デフォルトのレート制限を把握する。私のパネルには適度なバースト上限と1分あたりのクォータが表示されました。テストには十分でしたが、本番スパイクには足りません。
ちょっと好きだったこと。ダッシュボードは最近の4xx/5xxエラーをタイムスタンプ付きで表示します。後で制限に引っかかったときも、推測する必要がありませんでした。チームで作業する場合、ロールベースのキー表示が役立ちました。書き込み可能なキーを.envファイルに保存して、週中に一度ローテーションしてリボケーション(取り消し)がちゃんと機能するか確認しました(すぐに機能しました)。
基本的なリクエスト
最初のチェックポイントは、新しいモデルでいつも使うものと同じでした。短いプロンプト、短い答え、JSONに驚きはなし。
APIスキーマは、GLM-4.7-Flash APIの公式ガイドで説明されている同じチャット完了パターンに従っています。つまり、リクエストセマンティクスを改めて学ぶ必要がありませんでした。
curlの例
最も単純で、私にとって一貫して動作したコールです。エンドポイント名はプロバイダーによって異なる場合があります。テスト中に使ったパターンはこれです。
curl https://api.wavespeed.ai/v1/chat/completions \
-H "Authorization: Bearer $WAVESPEED_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "GLM-4.7-Flash",
"messages": [
{"role": "system", "content": "You are concise and helpful."},
{"role": "user", "content": "Summarize this in one sentence: GLM-4.7-Flash API quick test."}
],
"temperature": 0.2,
"max_tokens": 120
}'テスト実行からの注記
- レイテンシー: 朝の中頃(米国時間)に小さなプロンプトで最初のトークンまで約200~400ms。短い返答の場合、エンドツーエンドで1秒以下で完了しました。
- 安定性: ストリーミングがオフのとき、レスポンスは毎回きちんとしたJSONでした。
- コスト: あなたのプランについては言えませんが、トークンは使用ログに明確に報告されました。素早い反復を押し進めるとき、それは重要です。
Pythonの例
ちょっとしたスクリプトには、環境から読み込んだキーを使った単一の関数が好みです。
import os
import requests
API_KEY = os.getenv("WAVESPEED_API_KEY")
BASE_URL = "https://api.wavespeed.ai/v1/chat/completions"
payload = {
"model": "GLM-4.7-Flash",
"messages": [
{"role": "system", "content": "You are concise and helpful."},
{
"role": "user",
"content": "Give me 3 bullet points on maintaining a calm writing workflow."
}
],
"temperature": 0.3,
"max_tokens": 180
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
resp = requests.post(BASE_URL, json=payload, headers=headers, timeout=30)
resp.raise_for_status()
data = resp.json()
print(data["choices"][0]["message"]["content"]) # typical OpenAI-style schemaちょっとした2つの反応がありました。
- 安心感: スキーマはいつものチャット完了フォーマットと一致しており、アダプター層が不要でした。最小限の変更で既存のツールに組み込みました。
- 制限: より高い温度での長い出力は時々うろうろすることがありました。それは「Flash」タイプモデルでは普通のことです。
max_tokensで切り詰めて、より厳しいシステムプロンプトで調子を整えました。
ストリーミングを有効にする
テキストをライブで形作るとき、または低レイテンシーが完全性よりも重要なときのみ、ストリーミングをオンにします。GLM-4.7-Flashはこのためにできたと感じました。速い最初のトークン、パラメータが正しく設定されたら安定したチャンキング。
ストリームパラメータセットアップ
サーバー送信イベント(SSE)を有効にするには、stream: trueを設定します。それだけです。残りはハウスキーピング。クライアントがイベント行を読み取り、[DONE]で停止することを確認してください。
使ったcurlバージョン:
curl https://api.wavespeed.ai/v1/chat/completions \
-H "Authorization: Bearer $WAVESPEED_API_KEY" \
-H "Content-Type: application/json" \
-N \
-d '{
"model": "GLM-4.7-Flash",
"messages": [
{"role": "user", "content": "Draft a two-sentence intro about quiet tools."}
],
"stream": true,
"temperature": 0.2,
"max_tokens": 120
}'2つのフィールドノート:
- curlで
-N(no-buffer)を忘れると、ストリームが詰まったように見える可能性があります。 - イベントの代わりにプレーンなJSONブロブが取得できる場合、
streamがブール値のtrueであって文字列ではないか二重チェックしてください。
コードでチャンクを処理する
Pythonでは、行ごとに読み取り、data:フレームを解析し、センチネルで停止しました。このパターンはスムーズに機能しました。
import os, json, requests
API_KEY = os.getenv("WAVESPEED_API_KEY")
BASE_URL = "https://api.wavespeed.ai/v1/chat/completions"
payload = {
"model": "GLM-4.7-Flash",
"messages": [{"role": "user", "content": "Write a calm closing paragraph."}],
"stream": True,
"temperature": 0.2,
}
with requests.post(
BASE_URL,
json=payload,
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
stream=True,
timeout=60
) as r:
r.raise_for_status()
for line in r.iter_lines(decode_unicode=True):
if not line or not line.startswith("data:"):
continue
data = line[len("data:"):].strip()
if data == "[DONE]":
break
try:
delta = json.loads(data)["choices"][0]["delta"].get("content", "")
print(delta, end="", flush=True)
except (KeyError, json.JSONDecodeError):
# Skip malformed or heartbeat frames gracefully
continue
print() # newlineちょっと驚いたこと。チャンクのタイミングは安定していました。いくつか長いプロンプトを試してもまだ予測可能なペーシングが得られました。ストリーミングは非常に短い返答での実時間を節約しませんでしたが、待っている感覚を減らしてくれました。ターミナルで直接編集しているときはカウントされます。
パラメータリファレンス
日常的に調整するのはほんの数個のノブです。GLM-4.7-Flash APIでは、これらは予想通りに動作しました。
temperature / top_p / max_tokens
- temperature: 本番関連のタスクでは0.1~0.4の間に保ちました。低い数字はより厳密で想像力の少ない言い回しを与えました。要約とサポートテキストには問題ありません。0.7を超えると、接線を期待してください。
- top_p: top_pは0.9周辺に保ちました。0.6に低い温度で締めると、出力は切り詰められたように感じ、箇条書きには便利でしたが、微妙な文章作成にはそうではありませんでした。
- max_tokens: これは私のガードレールでした。短い形式のタスクでは、150~250でコストを整理し、うろうろすることを防ぎました。アウトラインでは600~800で十分でした。モデルが早期に停止する場合、通常はこれです。バグではありません。
明確で事実的な答えが必要なとき、私にとってうまく機能した小さなセットアップ:
{
"model": "GLM-4.7-Flash",
"temperature": 0.2,
"top_p": 0.9,
"max_tokens": 200
}実際にそれが重要な理由。速度を求めるとき、書き直しは求めていません。保守的な温度と寛容だが無制限ではない max_tokens は、単に言い回しをカットするために同じコールを2回実行する必要から私を救ってくれました。
一般的なエラー
 テストをしながら小さなノートブックを手元に置いておきました。十分に何度も出てきた2つのエラーは、はっきり言及する価値があります。
テストをしながら小さなノートブックを手元に置いておきました。十分に何度も出てきた2つのエラーは、はっきり言及する価値があります。
429レート制限
見たもの:
- 並列リクエストのバースト(一度に5~10個)は時々429をトリップしました。新しいキーの最初の分以内に起こることが多くありました。
役立ったもの:
- バックオフ: ジッターされた指数バックオフ(例えば200ms、400ms、800ms、最大約3秒)はベビーシッティングなしにスパイクをクリアしました。
- キュー: ほぼ同じプロンプトを短いバッチウィンドウ(100~200ms)に結合すると、ピークレートを約30%削減しました。UXに変更はなく。
- ダッシュボードチェック: 使用パネルは私が問題だったときを確認しました。謎はなく、それは感謝しました。
これをトリップさせるもの: GLM-4.7-FlashをUIプレビューとサーバーフックに同時にワイアリングしているチーム。重要なら、プロバイダーに高い1分あたりの上限を求めるか、軽量なメモリ内キューを使用してください。
無効なJSONレスポンス
見たもの:
- ストリーミングがオンのとき、一部のクライアントはすべての
data:フレームを完全なJSONとして解析しようとします。そはSSEがどのように機能するかではありません。フレームは部分的です。 - 一度、ノイズの多い接続で、厳密なパーサーを破った切り詰められたイベント行を取得しました。
役立ったもの:
- パーサーを保護する:
data:の後のJSONのみを解析して、完全なメッセージではなく小さなデルタを含むことを期待してください。[DONE]で停止してください。 - タイムアウト: 合理的な読み取りタイムアウトを保つが、単一の不正形式のフレームのストリームをキルするのを避けてください。
- 非ストリームJSONが必要な場合。ストリームをオフにして、通常は清潔で単一のJSONオブジェクトが取得できます。私の実行では、非ストリームモードは不正形式のJSONを生成しませんでした。
もう1つのマイナーな問題。プロキシまたはサーバーがログをstdoutに挿入する場合、ストリームを汚染できます。ログをレスポンスパイプから分離してください。
このすべてのテストの後、WaveSpeedに固執した理由はかなり単純です。配管について考えたくなかったんです。
 WaveSpeedはあなたのコードとGLM-4.7-Flashのような高速モデルの間の退屈で信頼性の高い層になるために構築されました。クリーンなエンドポイント、予測可能な動作、そして何か問題が発生したときに実際に何が起こったかを教えてくれるダッシュボード。レート制限、エラー、使用法、推測なしで。
WaveSpeedはあなたのコードとGLM-4.7-Flashのような高速モデルの間の退屈で信頼性の高い層になるために構築されました。クリーンなエンドポイント、予測可能な動作、そして何か問題が発生したときに実際に何が起こったかを教えてくれるダッシュボード。レート制限、エラー、使用法、推測なしで。
高速化して要約、下書き、UIプレビュー、またはバックグラウンドジョブにFlashをワイアリングし、邪魔をしないようにしたいだけなら、それはまさに私たちが埋めようとしているギャップです。→ここをクリック!
関連記事

Seedance 2.0がWaveSpeedAIに登場予定:ネイティブ音声対応のバイトダンス次世代ビデオモデル

Seedance 2.0完全ガイド:マルチモーダルビデオクリエーション

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1:究極のAIビデオ生成モデル比較

Seedream 5.0-Preview完全ガイド:インテリジェント画像生成

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 完全比較
