GLM-4.7-Flash: リリース日、無料枠、主要機能(2026年)

こんにちは、私はDoraです。
最近、GLM-4.7-Flashが信頼できる人たちのスレッドに何度も現れるようになりました。通常、ちょっと肩をすくめながら「十分な速さで邪魔にならない」と言及されています。この一言が心に残りました。今、私は派手なモデルを追い求めているわけではありません。日々の仕事をもっと楽にするツールを求めています。わかりますか?
そこでGLM-4.7-Flashを数日間(2026年1月20~21日)私のスタックで試してみました。短いプロンプト、小さなAPIスクリプト、いくつかのバッチジョブ。何も劇的なことではありません。ずっと頭にあった質問は単純でした。これは実用的な追加機能なのか、それともタイムラインを通り過ぎていくもう1つのモデル名なのか?
GLM-4.7-Flashとは?
GLM-4.7-Flashは、Zhipu AIのGLM-4.7ファミリーの速度重視のバリアントです。重い推論オーバーヘッドなしに、応答性の高い低遅延の生成が必要な場合に選ぶモデルだと考えてください。長形式ベンチマークで勝つことや、哲学について議論することは目指していません。適切な回答を素早く、安く返すことが目標です。
開発元(Zhipu AI / Z.ai)
 Zhipu AI(Z.aiとも表記される)はGLMシリーズの開発チームです。以前のGLMモデルを使ったことがあれば、命名規則に見覚えがあるでしょう。数字は世代を示し、サフィックス(Flash、Standardなど)はトレードオフを示唆しています。彼らのドキュメントは分かりやすく、定期的に更新されています。統合する場合は、Zhipuの開発者ポータルの公式APIドキュメントをブックマークしてください。
Zhipu AI(Z.aiとも表記される)はGLMシリーズの開発チームです。以前のGLMモデルを使ったことがあれば、命名規則に見覚えがあるでしょう。数字は世代を示し、サフィックス(Flash、Standardなど)はトレードオフを示唆しています。彼らのドキュメントは分かりやすく、定期的に更新されています。統合する場合は、Zhipuの開発者ポータルの公式APIドキュメントをブックマークしてください。
この1年間、多言語対応と安定した予測可能な出力が必要な場合、Zhipuモデルを断続的に使用してきました。GLM-4.7-Flashはそのパターンを続けており、速度とスループットにより注意を払っています。
FlashとStandard、ポジショニング
実際に使ってみた時の違いはこんな感じです。
- Flash:速度に最適化、リクエストあたりのコンピュート低減、高容量エンドポイント、UIアシスタント、バッチ分類またはタグ付けに最適。簡潔なプロンプトと明確な構造で最も機能することに気づきました。
- Standard(非Flash):推論が多いタスクではより遅いが、より安定。Flash に多段階分析を投げ込むと、遅延を低く保つためにステップを圧縮しようとしているのがわかりました。
どちらかを選択する場合、優しいルール:遅延とコストが毎日を左右する場合、Flashから始めてください。複数ステップの推論での正確さが主な制約である場合、Standard(またはより大きな推論チューニングされた兄弟モデル)がより良い結果をもたらすでしょう。あなたの戦士を選ぶだけです。
公式ローンチ:2026年1月19日
Zhipu AIはGLM-4.7-Flashを2026年1月19日に発表しました。翌日からテストを開始しました。これらのモデルではバージョンコンテキストが重要です。初期段階では高速な反復が行われることがよくあります。これをより後で読んでいる場合は、公式ドキュメントのリリースノートで制限または動作への変更があるかどうかを確認してください。
アーキテクチャの概要
モデルの内部を知る必要はありませんが、特定の詳細はコスト推定とどこで優れるかを予測するのに役立ちます。
30B MoE、3Bのアクティブパラメータ
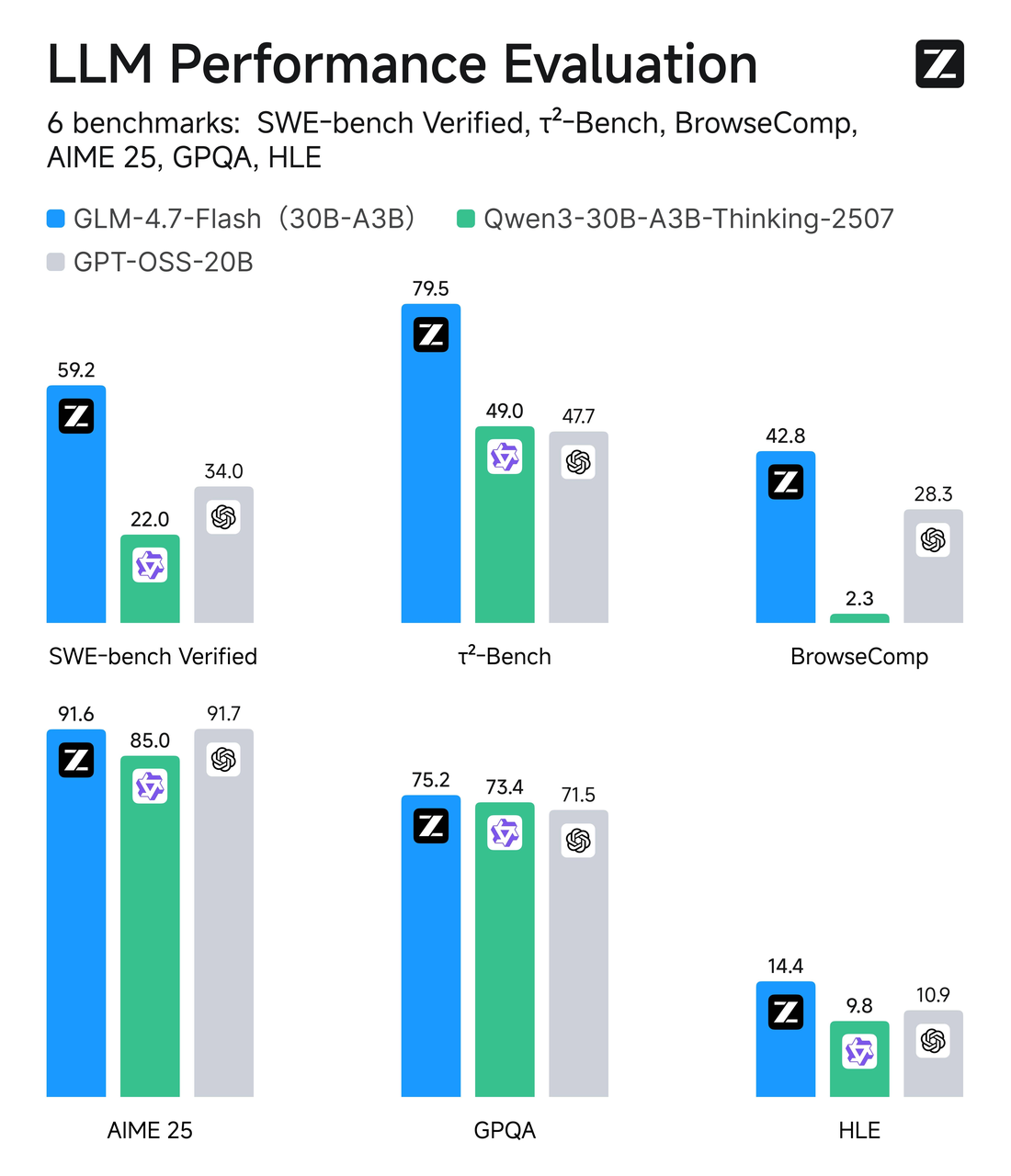 GLM-4.7-Flashは、Mixture-of-Experts(MoE)設計を使用し、総パラメータ数は約30Bですが、トークンあたり約3B個のエキスパートのみがアクティブです。平たく言えば:それは選択的なルーティングを持つ幅の広いモデルです。ほとんどの場合、ネットワークの小さなスライスのみがあなたのトークンで機能するため、推論は軽量なままです。
GLM-4.7-Flashは、Mixture-of-Experts(MoE)設計を使用し、総パラメータ数は約30Bですが、トークンあたり約3B個のエキスパートのみがアクティブです。平たく言えば:それは選択的なルーティングを持つ幅の広いモデルです。ほとんどの場合、ネットワークの小さなスライスのみがあなたのトークンで機能するため、推論は軽量なままです。
実際には、MoEはしばしば常に全コンピュート価格を支払うことなく「必要に応じてより大きな脳」を感じさせます。私のテスト中に、それは負荷下でも応答性の高い出力に変わり、同様の報告されているスケールの密なモデルよりも遅延の一貫性が高くなりました。魔法ではなく、容量と速度のバランスを取るためのスマートな方法です。
MLA(マルチヘッドレイテント注意)
ドキュメントではMLA(Multi-Headed Latent Attention)について言及しています。ユーザーとしての私の理解:それは古典的な完全自己注意、特に長いコンテキストでより効率的であることを目指した注意戦略です。ここで長コンテキスト制限を押しませんでした。私の実行はほとんど数千トークン未満でした。それでも、メモリフットプリントは合理的なままで、プロンプトが「短い」から「中程度」に成長するにつれて、通常の遅延の遅い滑りはありませんでした。
検索量の多いワークフローやエージェントループを計画している場合、MLA + MoEは有用なシグナルです:このモデルは最大単一ショット推論深度を追求するのではなく、スループットを維持するために設計されています。
無料API — 何が含まれているか
無料アクセスが目立ちました。ここで注意深く対応しているのは、無料層は時々週単位で変わるからです。私が共有しているのは、2026年1月20~21日に私が観察したもの、そしてZhipuのドキュメントローンチで示唆したものです。本番環境にこれを配線する前に、常に制限を二重チェックしてください。
 簡潔に言うと:無料APIでサニティデフォルトを使った実際のリクエストを作成させてくれました。テスト途中でペイウォールに当たることなく、小さなジョブを実行しました。これにより、プレイグラウンドからではなく、ライブスクリプトで試すための摩擦が減りました。
簡潔に言うと:無料APIでサニティデフォルトを使った実際のリクエストを作成させてくれました。テスト途中でペイウォールに当たることなく、小さなジョブを実行しました。これにより、プレイグラウンドからではなく、ライブスクリプトで試すための摩擦が減りました。
レート制限と同時実行性
私が見たもの:
- 同時実行性:小さなワーカーから複数の並列リクエストを快適に実行でき、エラーに引っかかることはありませんでした。私のテストでは、5~10の同時呼び出しは安定していました。より高くスパイクすると、スロットリングが始まりました。これは無料層で予想されます。
- スループット:短いプロンプト(分類、小さなトランスフォーメーション)は、サブセコンド~低秒範囲で返されました。平均すると、非常に短い応答で300~900ms、適度な出力で1.5~3秒が見られました。ネットワークの分散が適用されます。
- 安全性:制限を超えたときのAPI明確なエラーコードで応答しました。それだけでも時間を節約しました。何が間違ったのかを推測する必要がありませんでした。
正確なTPSの上限を追求しませんでした。私の目標は、小さなパイプラインが監視なしで実行できるかどうかを確認することでした。実行できました。正直なところ、自由を感じます。スパイク作業を計画している場合、現実的な同時実行でテストし、シンプルな再試行/バックオフを構築してください。無料層は、そうでなくなるまで寛大です。
FlashX有料層
Zhipuはより高いスループットとより予測可能なパフォーマンスを目指した「FlashX」有料オプションについて言及しています。このランでテストをFlashXに移行しませんでしたが、このようなプロバイダーでティアをアップグレードする場合に通常変わることは次のとおりです。
- より高い保証レート制限でスロットル数が少ないです。
- キーあたりより多くの同時リクエスト。バッチジョブとユーザー向けアシスタントに便利です。
- 優先度ルーティング(遅延尾短縮)。これは最悪の5%のリクエストを気にかけているが、中央値だけではない場合に重要です。
顧客向けの機能を出荷している場合、FlashXはより安全なルートです。いじっている場合、無料層は安定性と統合作業の感覚を得るのに十分です。あなたのマイレージはあなたの遅延予算とどのくらい頻繁にバッチするかによって異なります。
ベストユースケース
私は数つかの実際のタスクを試しました。派手なものではなく、単に私の週に現れるものです。
- ラグが雰囲気を殺す場所のインターフェースアシスタント。考えてください:インライン書き直し、小さな明確化、短いフォローアップ。GLM-4.7-FlashはUIの即座を感じさせました。
- バッチテキスト変換。小さなCSV(数千行)を実行して、トーン調整とカテゴリタグを実行しました。モデルは一貫性を保ち、途中で流れていませんでした。
- ドラフトスキャフォルディング。アウトライン、ポイント単位の拡張、シンプルなブリーフ。明確な指示を与えたときに構造をよく処理しました。賄賂をする必要がない小型ヘルパーを持つようなものです。
- 短いコンテキストウィンドウを使った検索要約。2~4のスニペットをパイプしたとき、奇妙なブリッジを幻覚化することなくクリーンに応答しました。長い、混乱したコンテキストでは、有用であろうとしましたが、時々過度に圧縮されました。
- 「最初のパス」コードコメントまたはドキュメント文字列。深いリファクタリングではありません。単に意図と命名を明確にし、速くそして有用です。
使用しない場所:
- 精度が速度より重要な場合の、エッジケースでの多段階分析。より重い推論モデルに手を伸ばします。
- 数千トークルにわたって安定したトーンと深い事実の継ぎ合わせが必要な長形式生成。Flashはそれを行うことができますが、キャラクターから外れているように感じます。
これが重要な理由:あなたの予算をブルドーザーしない高速モデルは、他の方法で削除する機能を開きます。あなたの製品がセッションあたり数十の小さなモデル呼び出しを必要とする場合、削られた遅延とコール当たりの低いコンピュートが追加されます。小さな勝利、大きな見返り。
💡 GLM-4.7-Flashのような実行モデルをより簡単で信頼できるものにするために、実際のワークフローでは、私は私たち自身のプラットフォームであるWaveSpeedを使用します。APIリクエスト、同時実行性、バッチジョブをスムーズに処理するため、スクリプトを監視する代わりに結果に焦点を当てることができます。
WaveSpeedを試す →
 現場からの小さな注意:私の最初の1時間はより速くありませんでした。プロンプト構造、温度、最大トークンを使って遊びました。数回の実行後、私はパターンを見つけました。短いシステムプロンプト、明示的な出力形式、明確な制約。これにより、時間と精神的努力の両方が削減されました。それは魔法ではありませんでした。それはセットアップでした。
現場からの小さな注意:私の最初の1時間はより速くありませんでした。プロンプト構造、温度、最大トークンを使って遊びました。数回の実行後、私はパターンを見つけました。短いシステムプロンプト、明示的な出力形式、明確な制約。これにより、時間と精神的努力の両方が削減されました。それは魔法ではありませんでした。それはセットアップでした。
GLM-4.7-Flash(またはFlashモデル)の「素早い10分のテスト」を開始し、時計が真夜中だと言っているのを見つけるために目をしばたきました。あなたの個人最高記録を落としてください。そして最終的にそれを振る舞わせた1つのプロンプト調整をコメントで落としてください。
関連記事

Seedance 2.0がWaveSpeedAIに登場予定:ネイティブ音声対応のバイトダンス次世代ビデオモデル

Seedance 2.0完全ガイド:マルチモーダルビデオクリエーション

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1:究極のAIビデオ生成モデル比較

Seedream 5.0-Preview完全ガイド:インテリジェント画像生成

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 完全比較
