5分でAIアンカーを作成:デジタルヒューマン構築初心者ガイド

WaveSpeedAI でデジタルヒューマンを構築するステップバイステップチュートリアル。
はじめに
誰もが生まれながらの話し手とは限らず、群衆の前で話すことに不安を感じる人も多くいます。
人前で話すことは緊張するものです。しかし、もし「バーチャル版のあなた」がプレゼンテーション、ライブ配信、またはあなたの宣伝読みを代わりに行うことができたら?それでも怖いと感じるでしょうか?
WaveSpeedAI では、それはもはや単なる考えではありません!ゼロから独自のデジタルヒューマンを構築し、リアルな音声と表情であなたの言葉を話させることができます。
ステージフリートはありませんし、疲れることもありません。何度でも改良し、再利用できます。仕事でも生活でも、あなたの信頼できるパートナーです。
このチュートリアルでは、シンプルなデジタルヒューマンをステップバイステップで構築する過程をゼロからガイドします。ここで使用するモデルはほんの始まりに過ぎません。もっと多くの機能とスタイルを探索して、デジタルヒューマンを本当に唯一無二のものにしてください。
WaveSpeedAI では、当社のモデルは透き通った安定した映像を生成し、自然なエッジを備えており、すぐに表示できます。フォーマルなトーキングヘッドセグメント、カジュアルな会話、製品説明など、様々な用途に適しています。
画像生成
ハンサムで、かわいく、自然な見た目のデジタルヒューマンは、視聴者により良い体験を提供します。また、あなたのチャンネルへのバズと流入を増やすでしょう。
個人写真から直接作成することもできます。すでに適切な写真を用意している場合は、この部分をスキップしてください。
例として bytedance/seedream-v4 を使用して、唯一無二のバーチャルアバターを作成するお手伝いをします。
WaveSpeedAI で bytedance/seedream-v4 を検索してください。これはテキストから画像を生成するモデルです。では、あなたのデジタルヒューマンを作成するためにプロンプトを入力してみましょう:
Half-length portrait of a young female digital human (22–28),
natural makeup, white shirt and light gray blazer,
looking at camera, soft studio light,
plain light-gray background, ultra realistic, 4k, 85mm, f/2.8
性別、衣装、背景 などの要素をカスタマイズして、ニーズに合わせて、より魅力的でブランドに合った様々なスタイルと雰囲気のデジタルヒューマンを作成できます。
音声生成
デジタルヒューマンの準備ができたので、次のステップは、自然に「話す」ことができるように、クリアなナレーションスクリプトを作成することです。
WaveSpeedAI で、カテゴリー > テキストから音声 に進んで、様々なモデルを探索してください。自然なナレーション、音声クローン、さらには作曲のモデルを提供しています。
このセクションでは、例として minimax/speech-02-hd を使用します。異なるボーカルスタイルと効果を探索するために、他のモデルを試してみてください。
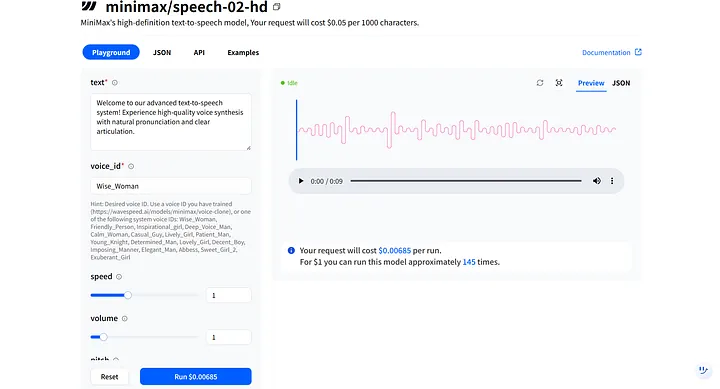
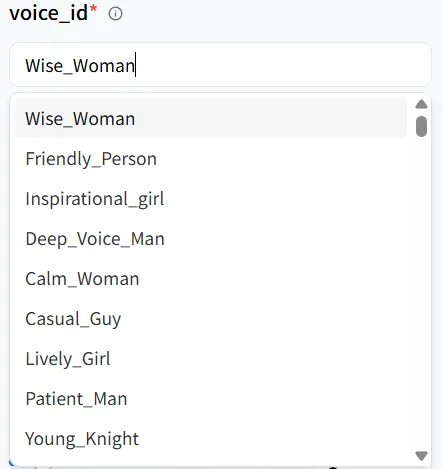
モデルの Playground では、text と voice_id などの主要なパラメーターが表示されます。これらは協力して、デジタルヒューマンのトーンとティンバーを形成し、異なるシナリオに合わせて調整できます。たとえば、私が作成したデジタルヒューマンは女性なので、最初の音声オプション、Wise_Woman を選択できます。
主要パラメーター
速度
speed は、デジタルヒューマンがどのくらいの速度で話すかを制御します。シーンに合ったペースを選択してください。たとえば、製品紹介ではやや遅くし、カジュアルな会話ではスピードアップしてください。値 1 は通常の速度を示します。

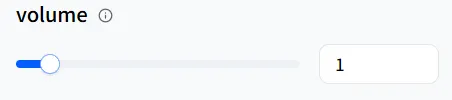
ボリューム
volume はラウドネスを設定します。デジタルヒューマンが子守唄をナレーションしている場合、speed を低下させてペースを遅くし、volume を減らしてより柔らかいデリバリーを実現できます。値 1 はデフォルトのボリュームです。
ピッチ
pitch は音声のトーンを調整します。これを調整して、音声をより明るく鋭く、またはより深く豊かに聞こえさせることができます。値 0 はデフォルトのピッチです。

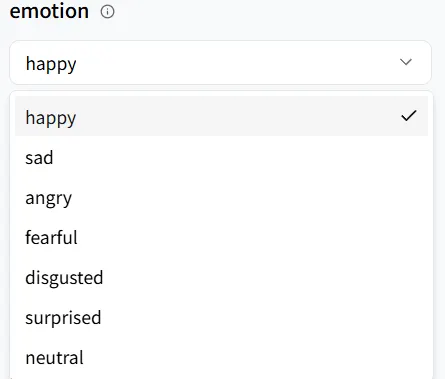
エモーション
emotion はデジタルヒューマンの話し方を制御します。シーンに合ったトーンを選択してください。ここでは、happy を選択します。
英語正規化
english_normalization オプションを有効にすると、英語の数字と記号が音声で自然に聞こえるようになります。有効にしていない場合、システムは数字を1つずつ読む可能性があります(たとえば、「123」を「one two three」と読む代わりに「one hundred and twenty-three」)。

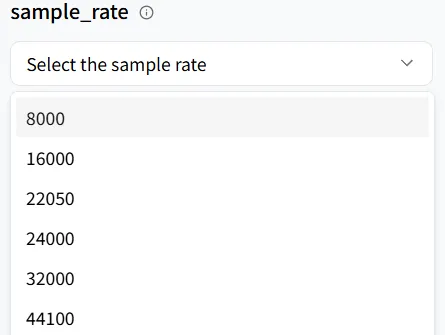
サンプルレート
sample_rate はオーディオ品質(解像度)を決定します。ASMRスタイルのコンテンツを制作する場合は、より豊かな詳細のために、より高いサンプルレートを目指してください。このチュートリアル例では重要ではありません。デフォルトを保つのが完全に問題ありません。
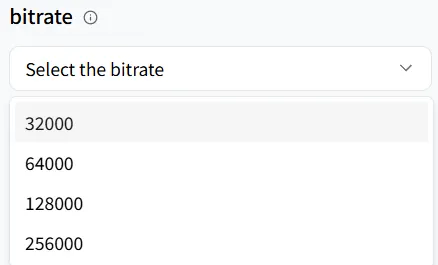
ビットレート
bitrate は、オーディオファイルの品質とサイズの両方を決定します。これは1秒あたりに処理されるビット数を表します。低いビットレートはより小さいファイルを作成しますが、詳細が失われる可能性があります。高いビットレートはより大きいファイルになり、より鮮明な音が得られます。
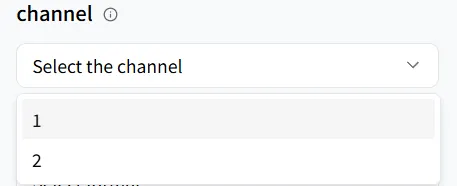
チャンネル
channel パラメーターは、生成されるオーディオチャネル数を決定します。
- channel = 1(モノラル): すべての音が単一のチャネルにミックスされます。電話音声、コール録音、または空間的な幅が不要な対話中心のコンテンツに最適です。
- channel = 2(ステレオ): 音は左右のチャネルに分割され、より没入感のある層状の体験を生み出すために空間と幅の感覚を生成します。音楽、映画、ゲーム、より高い聴覚品質を必要とするビデオナレーションに最適です。
フォーマット
format により、出力オーディオファイルタイプを選択できます(詳細はここでスキップします)。
言語ブースト
language_boost は、選択した言語に対するモデルの理解を向上させます。このチュートリアルでは、English を選択してください。
オーディオを生成する
次に、スクリプトを貼り付けて、Run をクリックしてオーディオを生成してください!
Welcome to WaveSpeedAI’s Digital Human Tutorial. We’ll spark fresh ideas in AIGC and show you practical steps. Let’s unleash your creativity together!
オーディオファイルをダウンロードしてください。これは、後でデジタルヒューマンに話させるための重要な部分です!
デジタルヒューマンに話させる
ついに、エキサイティングな瞬間が来ました。デジタルヒューマンに実際に 話させます!
WaveSpeedAI で wavespeed-ai/infinitetalk を検索してください。デジタルヒューマンのナレーション用に特別に設計された高品質モデルです。
モデルの Playground では、2つの必須入力が表示されます:audio と image。
- audio: ダウンロードしたばかりのナレーションファイルをアップロードしてください。
- image: 前に生成したデジタルヒューマン画像をアップロードしてください。
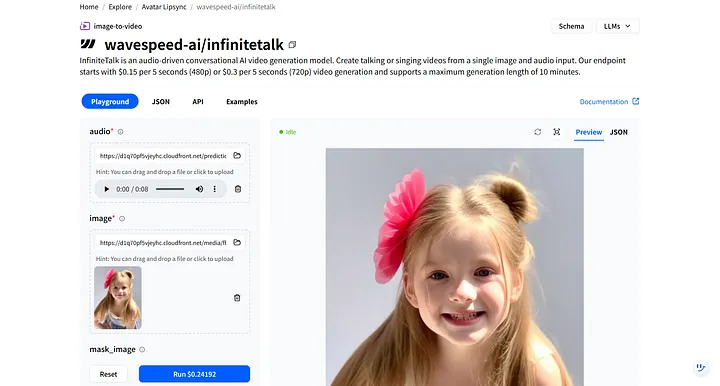
Run をクリックすると、デジタルヒューマンはオーディオに応答し、自動的に唇の動きと表情を同期させます。
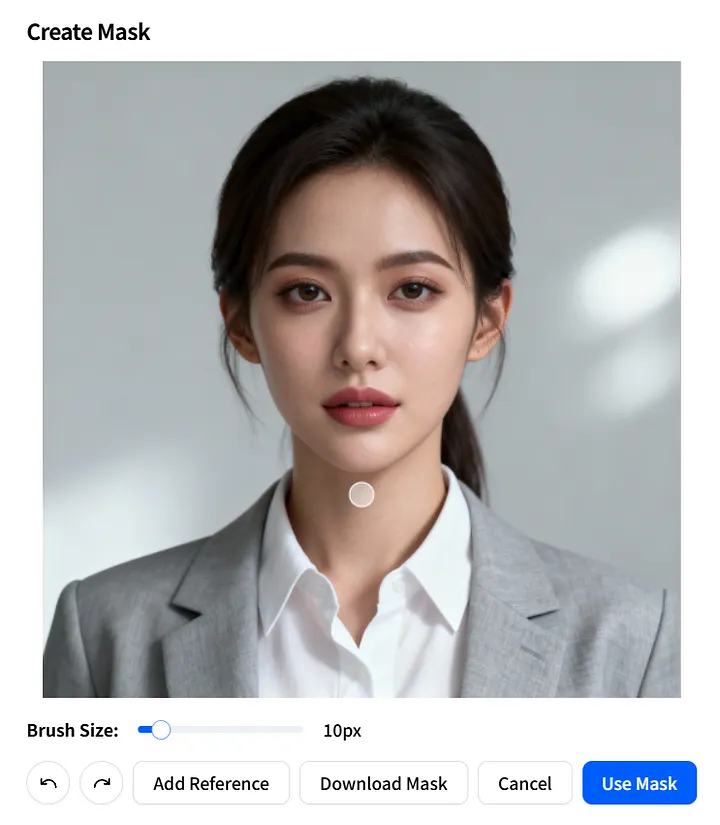
マスク画像パラメーター
次に、mask_image パラメーターを見てみましょう。これにより、画像のどの部分をアニメーション化するかを正確に指定できます。
Create Mask ページで、可動領域を正確に定義します:Brush Size を調整し、アニメーション化したい領域をペイントし、Use Mask をクリックして適用します。
Download Mask をクリックして、mask_image をテンプレートとして保存し、今後のプロジェクトで迅速に再利用することもできます。
追加のカスタマイズ
ポーズ、手のジェスチャー、視線の方向を指定するなど、追加のニーズがある場合は、prompt にさらに具体的な指示を追加してください。
簡単に複製するために、固定した seed 値を設定してください。これにより、ランダム性が一貫するので、後で同じ結果を再現できます。
最後に、Run をクリックして、最終結果に期待しましょう!
おめでとうございます!あなた自身のデジタルヒューマンを手に入れました!
複数人のシーン に進める準備はできていますか?WaveSpeedAI はそのための専用モデルも提供しています。一緒に探索しましょう!
マルチスピーカー生成
WaveSpeedAI で wavespeed-ai/infinitetalk/multi を検索してください。その手順は基本的にシングルパーソンモデルと同じです。
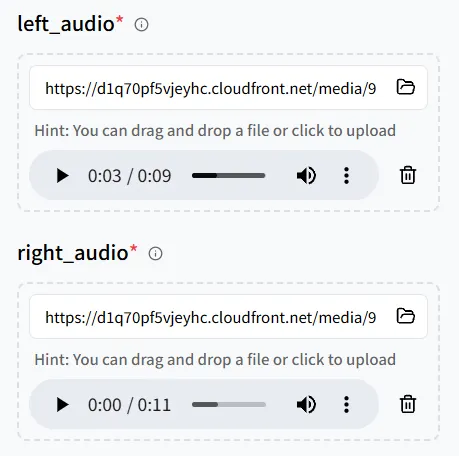
今回は、2つのオーディオファイル を追加し、両方のキャラクターがセリフを話せるように、2つのデジタルヒューマンを特徴とする画像 をアップロードします。
オーディオとオン画像位置の間のペアリングに細心の注意を払ってください:
- left_audio → 画像の ** 左** にいる人
- right_audio → 画像の ** 右** にいる人
マッピングを慎重に確認してください。そうしないと、声が間違ったキャラクターにリンクされる可能性があります。
スピーキングモード
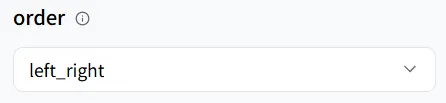
wavespeed-ai/infinitetalk/multi モデルでは、3つのスピーキングモードをサポートしています:
- left_right(左から右)
- right_left(右から左)
- meanwhile(同時発話)
同様に、このモデルでは、prompt を通じてあなたが望む詳細を追加し、簡単に再現可能にするために seed を設定できます。
そして、あなたは2人のナレーションショーを手に入れました!
その他のモデル
WaveSpeedAI では、あなたのために多くの追加モデルも提供しています:
- wavespeed-ai/multitalk: 「歌詞スタイルのデジタルヒューマン」に最適で、マルチパートボーカルとより表現力豊かなパフォーマンスを可能にします。
- wavespeed-ai/infinitetalk/video-to-video: 既存のビデオにナレーションまたはナレーションを追加し、ビジュアルとオーディオが自然に同期したままになるようにします。
- wavespeed-ai/song-generation: ゼロからミュージックを作成して、コンテンツ用にカスタムサウンドトラックと雰囲気を設計します。
これらのモデルはまた、他のプラットフォームで複製するのが難しい独特の体験を提供します。大胆に、それらを試して、あなたの作品を共有してください!Inspiration セクションに投稿して、他のクリエイターとつながり、交流することができます!

最後に
私たちの世界は急速に変化しており、AI はますます私たちの日常生活に影響を与えています。古い方法に固執することで、コストが増加し、進歩が遅れ、新しい機会を逃すリスクが高まります。
今こそ、新しい技術を採用し、それがもたらす利便性と効率を享受する完璧な時です。WaveSpeedAI は、信頼できるテクノロジーと常に成長するエコシステムで、コンテンツ作成の長期的なサポートを提供します。
あなたの創意工夫がどこへ導こうとも、WaveSpeedAI はあなたの信頼できる基盤と信頼できるパートナーとしてそこにいます。
関連記事

Seedance 2.0がWaveSpeedAIに登場予定:ネイティブ音声対応のバイトダンス次世代ビデオモデル

Seedance 2.0完全ガイド:マルチモーダルビデオクリエーション

Seedream 5.0-Preview完全ガイド:インテリジェント画像生成

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 完全比較

Vidu Q3レビュー:Sora 2、Wan 2.6、Seedance 1.5、Veo 3.1、Grok Imagine Videoとの比較
