Windows版ComfyUIでLTX-2をインストール:CUDA セットアップと初回実行ガイド

私はドーラです。その日、スケッチのための簡単なテキスト・ツー・ビデオパスが欲しかったのですが、ComfyUIのスレッドでLTX‑2が頻繁に言及されているのを見かけました。昼前には、空白のグラフと「ltx」というフォルダを前にして、またドライバーの運ゲーに登録したのかと思っていました。
Windows 11でセットアップした際のメモを取っておきました。「ltx‑2 comfyui windows」で検索している途中でここに来たのなら、私も同じです。役に立ったことをご紹介します。
インストール前のチェックリスト(GPU / CUDA / ドライババージョン)
始める前に軽くチェックしておくと、後で追う1時間分のDLLエラーを節約できます:
- GPU: 最低でも12 GB のVRAMを持つNVIDIAカードがあれば、LTX‑2を控えめな設定(幅512–768、短いクリップ)で使用できました。8 GBでも非常に保守的な設定では動作しますが、タイトで、多くの場合イライラします。
- ドライバ: 最新のGame ReadyまたはStudioドライバに更新してください(552.xxを使用)。
- CUDA: ComfyUIポータブル用に完全なCUDAツールキットをインストールする必要はありません。PyTorchに付属する実行時DLLが必要なだけです。これがPyTorch+CUDAビルドのマッチング(cu121またはcu122など)が重要な理由です。
- Python: ComfyUIポータブルビルドは独自のPythonが付属しています。カスタムvenvを実行する場合は、選択するPyTorchホイールと整合させてください。
- VC++再頒布可能パッケージ: 最新のMicrosoft Visual C++再頒布可能パッケージをインストール/修復してください。「プロシージャエントリポイント」スタイルのDLLエラーのための静かな修正です。
重い モデルの前に私がやる2つの正気チェック:
nvidia-smiがターミナルで実行され、ドライバが明確に表示される。python -c "import torch: print(torch.version, torch.cuda.is_available())"はComfyUIが使用する環境でCUDAに対してTrueを返す。
これらのいずれも確実な航海を保証しませんが、失敗モードを絞ります。
ComfyUIをLTX-2対応バージョンにアップデート
私がしたこと:
- ComfyUIをまず更新してください。GitHubのポータブルビルドを使用している場合は、最新リリースを取得するか、gitプルして更新スクリプトを実行します。
- ComfyUI Manager(使用している場合)を開き、コア依存関係を更新します。プロンプトが出たらManagerにvenvを再構築させました。
- LTX‑2ノードパックをその公式リポジトリからインストールします。名前は異なります(「ComfyUI-LTXVideo」/「LTX‑Video」スタイルのリポジトリを見かけました):モデルの公式ページからリンクされているものを使用しました。リポジトリの説明がLTX‑Video v2/LTX‑2をサポートしていると言っている場合、それが欲しいです。
これが実践で重要な理由:
- LTX‑2はPyTorch 2.3以上の機能とCUDA 12.xビルドに依存しています。古いトーチ(cu118)を新しいノード(cu121/cu122など)と混ぜることは、不可思議なインポートエラーに当たるのは速いです。
- 一部のパックはFP8/BF16トグルを異なる方法で公開しています。ノードパックとComfyUIバージョンをマッチングすることで、不一致の入力と行き止まりグラフを回避します。
最初は新規インストールに抵抗しました、それは不要に感じました。その後、比較した:新しいビルドは最初の試行で開始されました;古いものは常に不足している操作を求めていました。推測を逃しませんでした。
モデルファイルの配置(ステップバイステップ)
これは通常、時間を失うところです。異なるノードは異なるフォルダを期待しています。これは、インストールしたLTX‑2ノードパックで私に働いたもので、一般的なパターンはフォルダ名が異なっても成り立ちます。
-
ノードの予期されるパスを見つけます。
ComfyUIで、LTXローダーノードを開き、ファイル入力にカーソルを合わせます。ほとんどのパックは、スキャンしている相対パス(例:models/ltx、models/checkpoints、またはmodels/ltx_videoなどのカスタムサブフォルダ)を表示します。
疑わしい場合は、リポジトリのREADMEを確認してください。通常、正確なディレクトリをリストします。 -
公式ソースからLTX‑2の重みをダウンロードします(多くの場合HuggingFace、モデルのページからリンク)。
通常、メイン.safetensorsまたは.pthファイルとコンフィグが取得されます。一部のリポジトリはテキストエンコーダ/VAEを別々に分割します;その他はバンドルします。 -
ファイルをノードが見つける場所に正確に配置します。
私のパック用:ComfyUI/models/ltx_video/は、プライマリモデルファイルを保持していました。パックがmodels/checkpointsと言っている場合、代わりにそれを使用してください。再起動またはリスキャン後、名前がノードドロップダウンに表示されるはずです。 -
オプション:テキストエンコーダ / VAE。
ノードがエンコーダまたはVAEの個別の入力を公開している場合、そのガイダンスに従います。多くのLTX‑2ノードはこれを隠して、コンポーネントを内部的にバンドルします。公開されている場合は、READMEによって指示されたとおり、CLIP/Tokenizer ファイルをmodels/clipまたはmodels/text_encodersに入れます。 -
ComfyUIを再起動します。
わかります、明らかです。しかし、ホットリロードは常にこれらのフォルダを再スキャンするわけではなく、空のドロップダウンを何度も見つめていました。
小さな注意:Windowsがダウンロードされたファイルをブロック済みとしてフラグした場合(右クリック > プロパティ > ブロック解除)、それをクリアしてください。より厳格なセットアップでは、Pythonが「インターネットからダウンロード」されたファイルに触るのを拒否しています。
Windows上の一般的なエラー(DLL /アクセス許可)
「DLLをインポート中にロードに失敗しました…」または「nvrtc64_X.dll」が不足している
- 原因:PyTorchビルドがノードパックで予期されるCUDA実行時と一致しなかった、または環境がcu118とcu12xを混在させた。
- 修正:ComfyUI環境内にPyTorch 2.3以上cu121/cu122をインストール/確認します。ポータブルを実行する場合は、Managerに処理させます。NVIDIAドライバの更新は1回役に立ちました。
 フレーム/ビデオの書き込み時に「アクセスが拒否されました」
フレーム/ビデオの書き込み時に「アクセスが拒否されました」 - 原因:SaveVideoノードを、アクセス許可が厳しい同期フォルダ(OneDrive)に向けました。
- 修正:まず、ローカルの非同期パスに書き込みます(例:
ComfyUI/output/ltx_test)。後でファイルを移動します。
解凍時の長いパスの問題
- 原因:Windowsパスの長さ制限とComfyUIの深いサブフォルダ。
- 修正:Windowsで長いパスを有効にするか(ローカルグループポリシーまたはレジストリ)、または
C:\の近くに解凍します。
レンダリング中のアンチウイルススキャン一時フレーム
- 症状:エンコード中のComfyUIハング またはスタッター。
- 修正:ComfyUIフォルダまたは出力一時パスの除外を追加します。
「モデルが見つかりません」正しいフォルダなのに
- 修正:ComfyUIを再起動してください。それでも表示されない場合は、ノードの正確な予期されたフォルダを確認してください。一部のLTX‑2ノードはカスタムディレクトリ名を探します。正確に一致させます。
私はまた、「1回動作して、次の実行で失敗」という古典的な問題に遭遇しました。私の場合、それはエンコードノードがまだ書き込んでいる間に、ブラウザタブが部分的なMP4をプレビューしようとしていることに帰着しました。実行ごとに新しいファイル名に書き込むように切り替えました。不安定性は消えました。
最初の推論テストワークフロー
最初のグラフは小さく保ちました。何も巧妙ではなく、パイプラインを確認するのに十分です。
私が構築したもの:
- 単一の文(10–20トークン)を含むプロンプトノード。シンプルに保つ。
- ダウンロードされたモデルを指すLTX‑2ローダーノード。
- 低いステップのLTX‑2サンプラー/スケジューラノード(パックが何と呼ぶかは何でも)。
- フレームをSaveVideoノード(MP4、H.264はスモークテストで問題ありません)に書き込むビデオデコード/アセンブリパス。
私と戦わなかったパラメーター:
- 解像度:512×288 または 640×360
- フレーム:8–16フレーム(0.5–1秒)
- ステップ:6–12
- ガイダンス/CFG:中間地(5–7)
- シード:固定数字(トラブルシューティングの騒音を少なくします)
- 精度:FP16(デフォルト)、ノードがAdaでBF16を提案しない限り:両方が私に対して機能し、FP16はより少ないVRAMを使用しました
最初の実行で私が注意するもの:
nvidia-smiのVRAMスパイク。即座に99%VRAMでペグされている場合は、解像度またはフレームを下げます。- 最初のフレームまでの時間。4070でのsteps=8、512×288での16フレームのための最初のクリーンな実行は約25–40秒でした。何か非常に長いものは通常、CPUエンコードまたはI/Oボトルネックを指していました。
レンダーが完了していてもビデオが空または破損している場合は、試してください:
- PNGフレームを最初に書き込み、その後、別のノードまたは外部ツールにビデオを組み立てさせる。
- 別のエンコーダ(H.264対H.265)またはCRF値に切り替える。
有用な部分は速度ではなく、1つの一貫性のあるクリップを見ることでした。それが私が落ち着く瞬間です。その後、慎重にスケールアップします。
パフォーマンスチューニング(バッチ/精度)
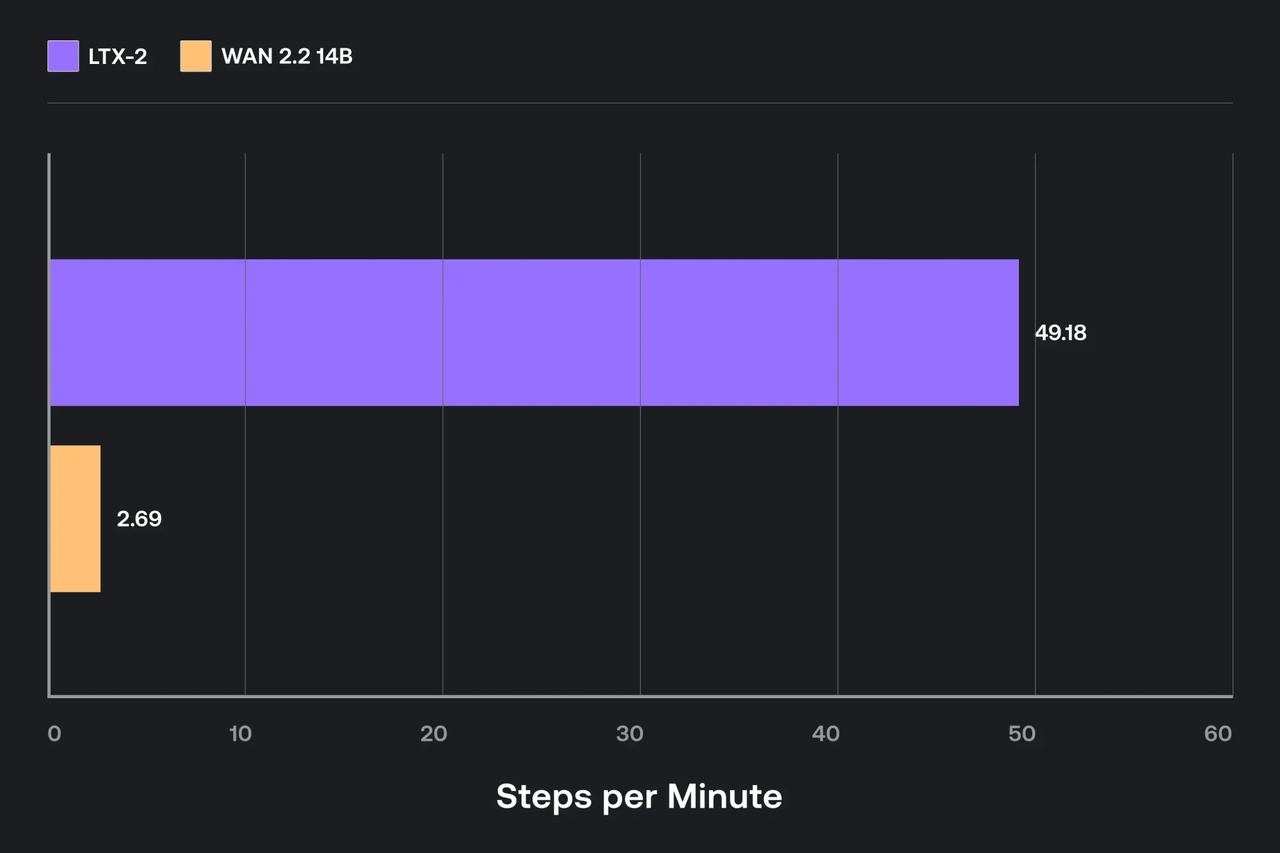 ベンチマークの栄光を追求しませんでした。メモリをベビーシッティングから止めた設定が欲しかったです。
ベンチマークの栄光を追求しませんでした。メモリをベビーシッティングから止めた設定が欲しかったです。
針を動かしたもの:
- 幅の前のフレーム。12–16フレームを保ち、幅を640にバンプする方が、VRAMに簡単でした。より長いクリップは速くメモリで上がります。
- 精度:4070ではFP16が最も機能しました。BF16も機能しましたが、少し多くのメモリを使用しました。これらのサイズでBF16から見える品質を得ませんでした。
- アテンションバックエンド:パックが
scaled_dot_product_attention(PyTorchネイティブ)対xFormersのトグルを公開する場合は、最近のPyTorchでネイティブを最初に試してください。Windowsでは私に対してより安定していました。 - バッチサイズ:ビデオ用に1に保ってください。ミニバッチは、ウォールクロック時間を節約することなく、主にVRAMを罰しました。
- Torch compile:テストする価値がありますが、実行時間が長い場合にのみ小さな利益しか見ませんでした。8–16フレームの短いテストの場合、コンパイル時間は節約を食べることができました。
- Mixed IO:ファストローカルSSDへの書き込みは、予想以上に重要でした。遅いネットワークフォルダはエンコードフェーズがモデル問題のように見える場合がありますが、そうではありませんでした。
VRAMを爆発させなかったシンプルなラダー:
- 512×288、12フレーム、steps=8
- 640×360、16フレーム、steps=10
- 768×432、16–24フレーム、steps=12–14
メモリ不足になった場合:
- 幅を下げる前に4フレームを下げます。
- ドラフトが必要な場合はまず手順を減らします。
- 他のGPUアプリ(ビデオプレイヤー、ハードウェアアクセラレーション付きのブラウザ)を閉じます。退屈ですが、機能します。
私は、一部のパックが提供する小さなタイル/パッチモードも試しました。より高い幅で役立ちましたが、時々縫い目をもたらしました。実験に適してい:デフォルトではありません。
WaveSpeedパス(ローカルCUDAは不要)
 GPUシャッフルを避けるために、ホストされたパスを通じて1つの実行をテストしました。アイデア:ComfyUIがLTX‑2を実行するリモートワーカーと話をさせるので、ローカルWindowsボックスはグラフUIを処理するだけです。
GPUシャッフルを避けるために、ホストされたパスを通じて1つの実行をテストしました。アイデア:ComfyUIがLTX‑2を実行するリモートワーカーと話をさせるので、ローカルWindowsボックスはグラフUIを処理するだけです。
これが実践でどのように見えたか:
- ComfyUIにコネクタ/拡張機能をインストールします(私が使用したものは、Managerリストで「WaveSpeed」と名付けました)。インストール後、リモート実行用の新しいノードセットが表示されました。
- 認証するか、ワーカーエンドポイントをポイントします。鉱山はダッシュボードキーを使用していました。セットアップは数分かかりました。
- ローカルLTX‑2ローダー/サンプラーをWaveSpeed相当物と交換します。同じプロンプト、同じグラフ形状、異なるノードだけです。
セットアップの頭痛をスキップ:WaveSpeedでLTX‑2を即座にテストしてください — ローカルGPUなし、ドライバのジャグリングなし、プロンプトを入力するだけでレンダリングを開始します。
興味がある場合は、現在のセットアップステップについてはコネクタの公式ドキュメントを確認してください。これを中心にワークフロー全体を再構築しませんが、CUDA以外のパスとして、それは爽やかに退屈でした、良い意味で。
関連記事

Seedance 2.0がWaveSpeedAIに登場予定:ネイティブ音声対応のバイトダンス次世代ビデオモデル

Seedance 2.0完全ガイド:マルチモーダルビデオクリエーション

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1:究極のAIビデオ生成モデル比較

Seedream 5.0-Preview完全ガイド:インテリジェント画像生成

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 完全比較
