DeepSeek V4 1M トークンコンテキスト: コードベース全体へのプロンプト方法

I’ll provide the Japanese translation directly:
やあみんな。僕はドーラだ。初めてDeepSeek V4の100万トークンのウィンドウに完全なプロジェクトを入れたとき、パワフルに感じたわけじゃない。慎重に感じた。100万トークンは無限のコーヒーのように聞こえるかもしれないが、カフェイン点滴で何時間も考えようとしたことのある人なら、その境界がどれだけぼやけるか知っている。この新しいコンテキストサイズが本当に僕の作業方法を変えるのか、それとも単にもっと貼り付けることを促すだけなのかを見たかった。
数日間(2026年1月27~30日)、DeepSeek V4 100万トークンを頻繁に実行する3つのタスクで使用した:
- ローカルセットアップなしで中規模のモノレポを読む
- 相互に通信が多いサービス間でバグを追跡する
- テストを壊さないリファクタリング提案を求める
学んだこと:たくさん適合させることはできるが、モデルはまだあなたが地図を指すことを必要としている。利益はより多くのファイルを詰め込むことからではなく、プロンプトをどのように段階立てたか、そしてモデルにそれをどのように進めさせるかから生じた。
100万トークンが実際に意味するもの
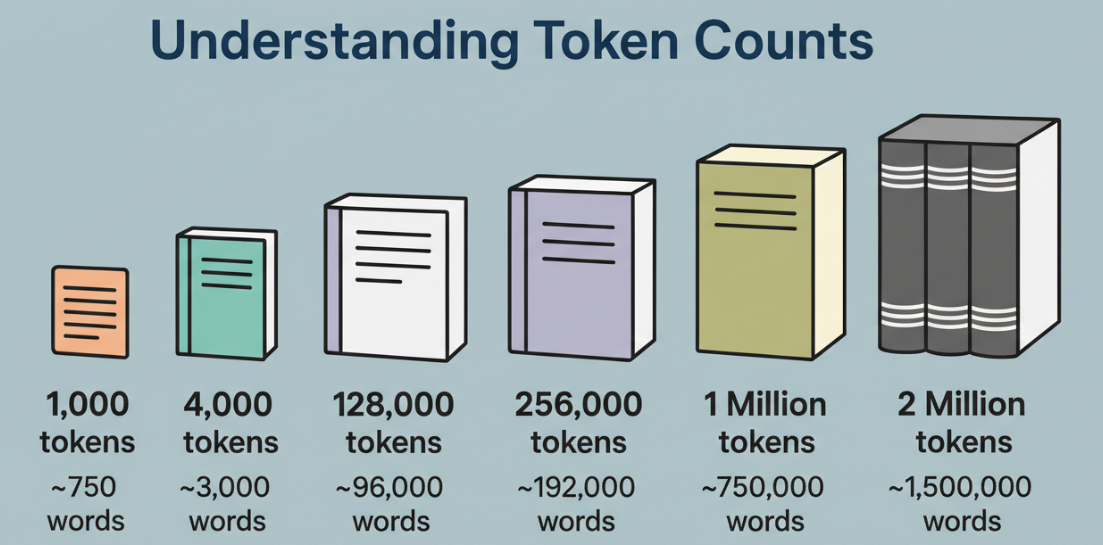 数字そのものには興味がない。それが明確な頭で何を保持しているかに興味がある。
数字そのものには興味がない。それが明確な頭で何を保持しているかに興味がある。
トークンは単語ではない。それはチャンク、時には完全な単語、時には単語の一部、時には句読点だ。英語テキストでは、通常1トークンを計画のための約0.75語として扱う。コードの場合、トークンが速く来る:括弧、ドット、メソッド名、すべて分割される。100万トークンは大きな領土だが、無限の注意ではない。
今週僕にとって変わったこと:積極的な削除をやめた。128Kコンテキストでは、積極的に要約して、ホットパスだけを保つだろう。100万なら、ホットパスに加えて、後で驚かせる傾向がある「コールド」ファイル(設定、マイグレーション、ビルドスクリプト、ワークフローグルー)を保つことができた。そうは言っても、一度にすべてを投げ込んだら、答えは曖昧になった。段階的にモデルに供給し、明確な目印を付けると、出力は根拠があるように感じられた。
コード行の同等物
作業中に使用した大雑把な計算:
- 多くのレポはコードとドキュメントを混ぜる。コード重いフォルダでは、密言語で約2~3トークン/文字が見えたが、実用的なショートカット:シンプルな行で約4トークン/行、インデント、名前、コメント付きの実世界の行で約8~12を考えて。
- そのペースで、100万トークンは約80K~150Kのコード行を保持し、スタイルと言語に応じた。コメントと構文の形式の良い命名のあるTypeScriptサービスはより高い側に座る。縮小されたバンドルはカウントを爆発させ、含める価値がない。
実際には、僕の「安全な適合」は約60Kの意味のあるソース+ターゲット化されたドキュメントとテストだった。もっと高く行くことができたが、遅延が増加し、答えが柔らかくなった。あなたのマイレージはトークナイザーのルールと言語の混合によって異なります。
vs 現在のモデル(128K)
128Kから1Mへのジャンプは、より大きなバックパックのようというより、ローリングカートを持ってくるようにすら感じる。もっと運ぶことができるが、スプリントしないだろう。
気づいたこと:
- レイテンシ:全コンテキストプロンプトは顕著に長くなった。セッションをチャンク化したとき(段階的に)、レイテンシは管理可能に感じられた。
- リコール:128Kでは、モデルはキーの部分を繰り返さない限り、早期のファイルを忘れることが多かった。100万では、忘れなかったが、特定を引用する代わりに一般化することがある。可能な限りファイルパスと行の範囲を引用するよう求めたとき、僕はより良い運があった。
- 精度:コンテキストが大きいほど、プロンプトにより多くのインデックス化行動が必要になる。そうでなければ、あなたが実際に気にしているメッシーなエッジケースを避ける有能な要約が得られる。
100万トークンが「プロンプトエンジニアリングはもう必要ない」ことを意味すると望んでいるなら、僕はそれを当てにしないだろう。それはあなたがする操舵の種類をシフトする。
大規模コードベースのプロンプト構造
 僕はプロンプトをメッセージとして考えるのをやめ、それを読書計画として扱い始めた。モデルは今たくさん読むことができるが、それでも目次とトレイルの恩恵を受ける。
僕はプロンプトをメッセージとして考えるのをやめ、それを読書計画として扱い始めた。モデルは今たくさん読むことができるが、それでも目次とトレイルの恩恵を受ける。
僕にとって最も良く機能したものは次のようなものに見えた:短いシステムフレーミング、簡潔なプロジェクトインデックス、宣言された探索の順序、その後具体的なタスク。そして、ワンメガプロンプトではなく、ラウンド単位でやり取りを続けた。
ファイル順序
モデルに何を最初に、2番目に、3番目に開くかを指示したとき、より信頼性の高い回答が得られた。上部の単一のリストはメンタルスタックを構築するのに役立った:
- エントリポイント(CLI、HTTPハンドラー、ジョブ)で開始する。それはフローをアンカーする。
- 次に、依存関係が接続される合成レイヤー(DIコンテナ、main.ts、app.py)。
- 次に、コアドメインモジュールとそのインターフェース。
- その後のみ:ヘルパー、ユーティリティ、横断的な部分(ログ、テレメトリ、設定)。
- テストは最後に、特定の失敗をデバッグしている場合を除き、その場合は期待値を設定するために失敗したスペックで開始する。
また、重要に見えるが重要ではないフォルダーのための「読まない」メモも含めた:生成されたコード、コンパイルされたアセット、スナップショット。それはトークンを保存し、モデルの注意を生きたコードに保つ。
小さなトリック:モデルに「アクティブファイル」のローリングリスト(パスと短い要約)を維持し、進むにつれてそれを更新するよう求めた。それが漂ったとき、僕はそのリストを指して、「今のところこのセット内に留まりなさい」と言うことができた。それは答えを具体的に保つ。
依存性マッピング
最も有用なパスの1つは、図としてではなく、単純なエッジのテーブルとして、早期に依存関係マップを求めることだった:モジュールAがBをインポートする、BはCを使用する、Cはenv変数にヒットするなど。テキストと簡潔に保つ。
これが実際に行ったこと:
- 迷走した依存性を公開した(フォルダ間の懸念が流出する種類)。
- リファクタリング前に確認する「圧力ポイント」のショートリストを与えた。
- 変更を求めたとき、正しい場所を参照するのに役立つ。
また、モデルに前提条件を述べさせた、それは命名、コメント、またはテストから推測したこと。前提が外れたとき、僕はそれを一度修正し、後のステップはより清潔なままだった。
警告の1つ:大きなレポで1つのショットで完全な依存関係マップを求めると、タイムアウトと曖昧なグラフにつながった。レイヤー(例えば、データアクセスのみ、HTTPハンドラーのみ)によってスコープを設定し、その後、ノート自体をマージすることで、より良い結果が得られた。追加の10分かかったが、精度で報いた。
必要に応じてチャンク戦略
 100万トークンのウィンドウを使用しても、僕はまだチャンク化した。それが適合できなかったからではなく、僕の思考が段階的に良かったため、モデルは僕が視界を絞ったとき、より正確に答えた。
100万トークンのウィンドウを使用しても、僕はまだチャンク化した。それが適合できなかったからではなく、僕の思考が段階的に良かったため、モデルは僕が視界を絞ったとき、より正確に答えた。
今週機能した少数のパターン:
- ブリーフを段階立てる:小さいコンテキスト、プロジェクトインデックス、タスク、既知の制約で開始し、その後、読書と検証の計画を求めた。その後のみコードを合意した順序で投入した。
- アクティブセットを制限する:リファクタリングの場合、プレイ中の5~12ファイルのみを保持し、明示的なパスで変更を求めた。編集が共有ユーティリティに触れた場合、次のターンでそのファイルを追加した。モデルはタイターのまま。
- エッジで要約する:新しいフォルダに移動する前に、学んだことと不確実性の短い要約を求めた。これらの要約は、すべてのファイルを再貼り付けることなくターン間でブレッドクラムとして機能した。
- 検索を意図的に使用する:快適に適合しなかったレポの場合、埋め込みを使用してクエリでファイルを呼び出した(「支払いID正規化」、「再試行バックオフ」)。取得したセットは実行ごとに小さく保持され、通常40Kトークン未満だったため、返信はぼやけなかった。
- 後方ではなく前方を検証する:「貼り付けたすべてのものを使用したか?」と尋ねるのではなく、「あなたの提案が依存する具体的な関数と行を指摘して」と求めた。それは具体的な参照を強制し、エラーを明らかにした。
ぶつかった摩擦:
- レイテンシはターンごとに全文脈メッセージを送るときに忍び込む。ステージングは同じタスクで僕の平均応答時間を70~90秒から20~40秒に削減した。
- コストは重要だ。大きなプロンプトが加算される。明白な再述をしているコメントをトリミング、コンパイルされたアーティファクトを削除、ベンダーバンドルをスキップすることでトークンを保存した。
- 位置効果は実在する。巨大なプロンプトの非常に最初または最後のコンテンツはより「利用可能」である傾向がある。ターンの最後の近くで小さな、重要な制約を繰り返すことでこれに対抗した。
100万ウィンドウから誰が恩恵を受けるか?

- モノレポに住んでいる場合、監査を処理する、または横断的なリファクタリングを行う場合、それはあなたに少ないセットアップステップとより少ないローカルインデックスオーバーヘッドを購入する。それはより静かな開始点だ。
- あなたの仕事が主に小さなサービスで焦点を絞ったバグ修正である場合、追加のキャパシティはあまり役立たない。より小さいコンテキストと厳しい検索パイプラインはより速く感じるだろう。
信頼に関する注記:危険な変更(マイグレーション、認証)に正確なコード行を引用するようモデルに求めた。ためらったり、パラフレーズしたりしたとき、僕はそれをスコープを絞るか、特定のファイルをもう一度貼り付けるためのフラグとして扱った。その小さな習慣はいくつかの近い失敗を防いだ。
モデルの制限やトークナイザーの動作の正式な説明が必要な場合は、プロバイダーのドキュメントを確認してください。僕が詳細が必要なとき、僕は公式のモデルカードとコンテキストウィンドウノートに戻った。それは僕に誠実に僕がモデルに何を求めているかについて保つ。
これは魔法ではない。それはただ大きなテーブルだ。有用だ、椅子を配置する場合。
火曜日から1つの小さなことを考え続ける:僕は修正を求め、モデルは一見するのに正しく見えた関数を変更することを提案した。それはそうではなかった。バグは2層下のヘルパーに住んでいた。100万トークンがそれを変えなかった。僕のメモがした。
関連記事

Seedance 2.0がWaveSpeedAIに登場予定:ネイティブ音声対応のバイトダンス次世代ビデオモデル

Seedance 2.0完全ガイド:マルチモーダルビデオクリエーション

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1:究極のAIビデオ生成モデル比較

Seedream 5.0-Preview完全ガイド:インテリジェント画像生成

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 完全比較
