WaveSpeedAI X DataCrunch: Inferensi Gambar FLUX Real-Time pada B200

WaveSpeedAI X DataCrunch: Inferensi Gambar FLUX Real-Time pada B200
WaveSpeedAI telah bermitra dengan penyedia cloud GPU Eropa DataCrunch untuk mencapai terobosan dalam penyebaran model generatif gambar dan video. Dengan mengoptimalkan model FLUX-dev berbobot terbuka pada GPU NVIDIA B200 tercanggih milik DataCrunch, kolaborasi kami memberikan inferensi gambar hingga 6× lebih cepat dibandingkan dengan baseline standar industri.
Dalam posting ini, kami memberikan gambaran teknis tentang model FLUX-dev dan GPU B200, membahas tantangan dalam menskalakan FLUX-dev dengan stack inferensi standar, dan berbagi hasil benchmark yang menunjukkan bagaimana framework proprietary WaveSpeedAI secara signifikan meningkatkan latensi dan efisiensi biaya. Tim ML perusahaan akan mempelajari bagaimana solusi WaveSpeedAI + DataCrunch ini diterjemahkan menjadi respons API yang lebih cepat dan pengurangan biaya per gambar yang signifikan – memberdayakan aplikasi AI dunia nyata. (WaveSpeedAI didirikan oleh Zeyi Cheng, yang memimpin misi kami untuk mempercepat inferensi AI generatif.)
Blog ini juga dipublikasikan di blog DataCrunch.
FLUX-Dev: Model generasi gambar SOTA
FLUX-dev adalah model generasi gambar open-source state-of-the-art (SOTA) yang mampu melakukan generasi teks-ke-gambar dan gambar-ke-gambar. Kemampuannya mencakup pemahaman dunia yang baik dan kepatuhan prompt (berkat encoder teks T5), keragaman gaya, semantik adegan kompleks dan pemahaman komposisi. Kualitas output model sebanding dengan atau dapat melampaui model closed-source populer seperti Midjourney v6.0, DALL·E 3 (HD), dan SD3-Ultra. FLUX-dev dengan cepat menjadi model generasi gambar paling populer dalam komunitas open-source, menetapkan benchmark baru untuk kualitas, keserbagunaan, dan penyelarasan prompt.
FLUX-dev menggunakan flow matching, dan arsitektur modelnya didasarkan pada arsitektur hibrida blok multimodal dan parallel diffusion transformer. Arsitektur ini memiliki 12B parameter, kira-kira 33 GB fp16/bf16. Oleh karena itu, FLUX-dev secara komputasi menuntut dengan jumlah parameter yang besar ini dan proses difusi iteratif. Inferensi yang efisien sangat penting untuk skenario inferensi berskala besar di mana pengalaman pengguna sangat penting.
Arsitektur GPU Blackwell NVIDIA: B200
Arsitektur Blackwell mencakup fitur-fitur baru seperti tensor core generasi ke-5 (fp8, fp4), Tensor Memory (TMEM) dan pasangan CTA (2 CTA).
-
TMEM: Tensor Memory adalah tingkat memori on-chip baru, memperluas hierarki tradisional register, shared memory (L1/SMEM), dan global memory. Di Hopper (misalnya H100), data on-chip dikelola melalui register (per thread) dan shared memory (per thread block atau CTA), dengan transfer berkecepatan tinggi melalui Tensor Memory Accelerator (TMA) ke shared memory. Blackwell mempertahankan yang tersebut tetapi menambahkan TMEM sebagai 256 KB SRAM tambahan per SM yang didedikasikan untuk operasi tensor-core. TMEM tidak secara fundamental mengubah cara Anda menulis kernel CUDA (algoritma logisnya sama) tetapi menambahkan alat baru untuk mengoptimalkan aliran data (lihat ThunderKittens Now Optimized for NVIDIA Blackwell GPUs).
-
2CTA (CTA Pairs) dan Cluster Cooperation: Blackwell juga memperkenalkan CTA pairs sebagai cara untuk erat menghubungkan dua CTA pada SM yang sama. Pasangan CTA pada dasarnya adalah cluster ukuran 2 (dua thread block yang dijadwalkan secara bersamaan pada satu SM dengan kemampuan sinkronisasi khusus). Sementara Hopper memungkinkan hingga 8 atau 16 CTA dalam cluster untuk berbagi data melalui DSM, pasangan CTA Blackwell memungkinkan mereka untuk menggunakan tensor core pada data umum secara kolektif. Faktanya, model PTX Blackwell memungkinkan dua CTA untuk menjalankan instruksi tensor core yang mengakses TMEM satu sama lain.
-
Tensor core generasi ke-5 (fp8, fp4): Tensor core di B200 sangat besar dan ~2–2.5x lebih cepat daripada tensor core di H100. Utilitas tensor core yang tinggi sangat penting untuk mencapai percepatan hardware generasi baru yang besar (lihat Benchmarking and Dissecting the Nvidia Hopper GPU Architecture).
Nomor kinerja tanpa sparsity
| Spesifikasi Teknis | ||
|---|---|---|
| H100 SXM | HGX B200 | |
| FP16/BF16 | 0.989 PFLOPS | 2.25 PFLOPS |
| INT8 | 1.979 PFLOPS | 4.5 PFLOPS |
| FP8 | 1.979 PFLOPS | 4.5 PFLOPS |
| FP4 | NaN | 9 PFLOPS |
| Memori GPU | 80 GB HBM3 | 180GB HBM3E |
| Bandwidth Memori GPU | 3.35 TB/s | 7.7TB/s |
| Bandwidth NVLink per GPU | 900GB/s | 1,800GB/s |
Micro-benchmarking level operator dari GEMM dan attention menunjukkan hal berikut:
- BF16 dan FP8 cuBLAS, CUTLASS GEMM kernel: hingga 2x lebih cepat dari cuBLAS GEMMs pada H100;
- Attention: kecepatan cuDNN adalah 2x lebih cepat daripada FA3 pada H100.
Hasil benchmarking menunjukkan bahwa B200 sangat cocok untuk beban kerja AI berskala besar, terutama model generatif yang memerlukan throughput memori tinggi dan komputasi padat.
Tantangan dengan Stack Inferensi Standar
Menjalankan FLUX-dev pada pipeline inferensi tipikal (misalnya, PyTorch + Hugging Face Diffusers), bahkan pada GPU high-end seperti H100, menghadirkan beberapa tantangan:
- Latensi tinggi per gambar karena overhead CPU-GPU dan kurangnya kernel fusion;
- Utilitas GPU suboptimal dan idle tensor core;
- Hambatan memori dan bandwidth selama langkah-langkah difusi iteratif.
Objektif optimasi melayani inferensi berskala besar dan murah adalah throughput lebih tinggi dan latensi lebih rendah, mengurangi biaya generasi gambar.
Framework Inferensi Proprietary WaveSpeedAI
WaveSpeedAI mengatasi bottleneck ini dengan framework proprietary yang dirancang khusus untuk inferensi generatif. Dikembangkan oleh pendiri Zeyi Cheng, framework ini adalah mesin inferensi performa tinggi in-house kami yang dioptimalkan khusus untuk model diffusion transformer state-of-the-art seperti FLUX-dev dan Wan 2.1. Inovasi kunci dalam mesin inferensi meliputi:
- Eksekusi GPU end-to-end menghilangkan bottleneck CPU;
- Kernel CUDA kustom dan kernel fusion untuk eksekusi yang dioptimalkan;
- Kuantisasi lanjutan dan mixed precision (BF16/FP8) menggunakan Blackwell Transformer Engine sambil mempertahankan presisi tertinggi;
- Perencanaan memori yang dioptimalkan dan pra-alokasi;
- Mekanisme penjadwalan prioritas-latensi yang memprioritaskan kecepatan dibanding kedalaman batching.
Mesin inferensi kami mengikuti co-design HW-SW, sepenuhnya memanfaatkan kapasitas komputasi dan memori B200. Ini merupakan lompatan maju yang signifikan dalam model serving AI, memungkinkan kami untuk memberikan inferensi latensi ultra-rendah dan efisiensi tinggi pada skala produksi. Kami mengevaluasi bagaimana optimasi ini mempengaruhi kualitas output, memprioritaskan optimasi lossless vs. loosely. Yaitu, kami tidak menerapkan optimasi yang dapat secara signifikan mengurangi kemampuan model atau sepenuhnya meruntuhkan kualitas output yang terlihat, seperti rendering teks dan semantik adegan.
Benchmark: WaveSpeedAI pada B200 vs. Baseline H100
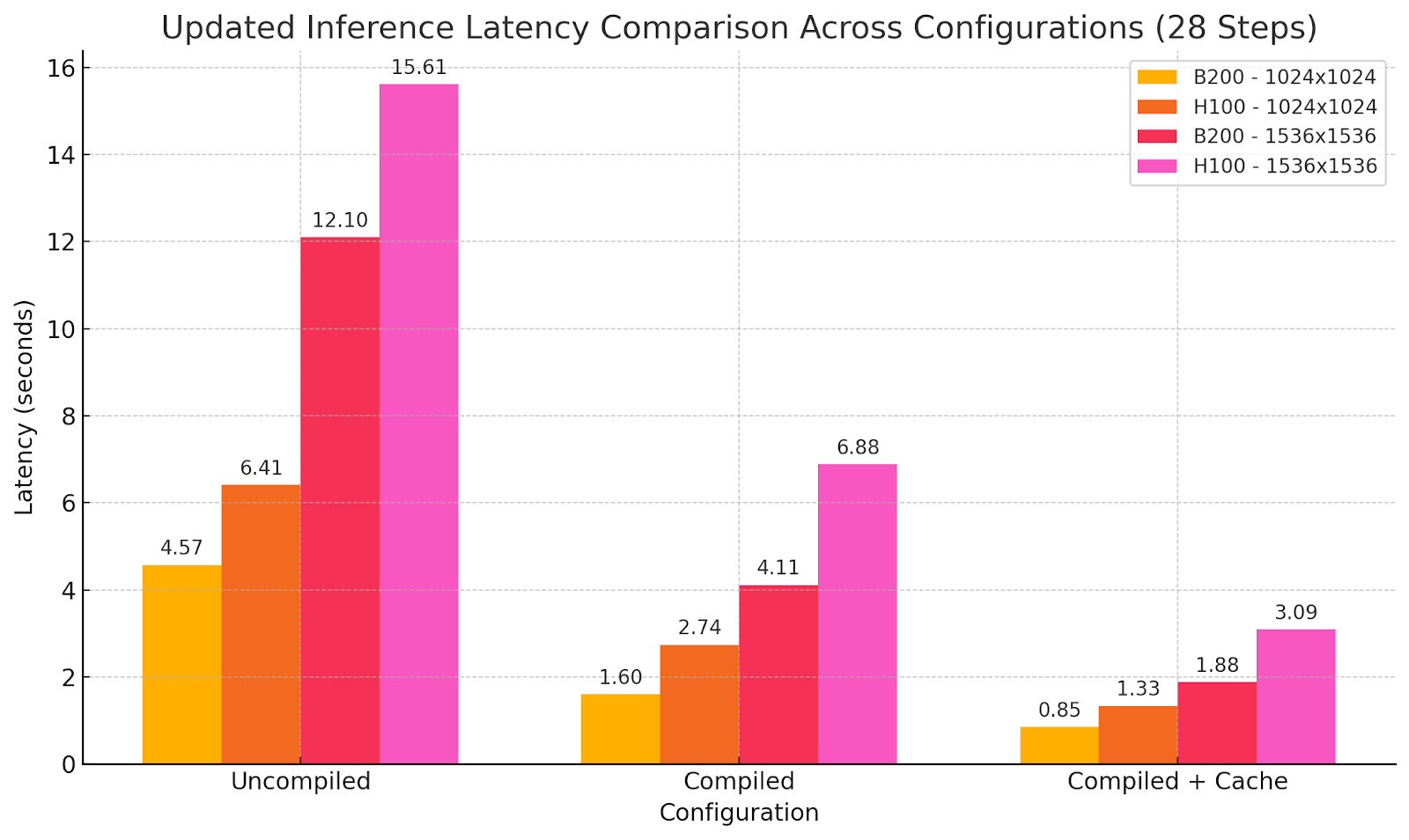
Output model menggunakan pengaturan optimasi berbeda:

Prompt: photograph of an alternative female with an orange bandana, light brown long hair, clear frame glasses, septum piecing [sic], beige overalls hanging off one shoulder, a white tube top underneath, she is sitting in her apartment on a bohemian rug, in the style of a vogue magazine shoot
Implikasi
Peningkatan kinerja diterjemahkan menjadi:
- Desain algoritma AI (misalnya DiT activation caching) dan optimasi sistem, menggunakan kernel yang dioptimalkan untuk arsitektur GPU, untuk utilasi HW yang lebih baik;
- Latensi inferensi yang dikurangi membuka kemungkinan baru (misalnya Test-Time Compute in diffusion models);
- Biaya per gambar yang lebih rendah karena efisiensi yang ditingkatkan dan pemanfaatan hardware yang berkurang.
Kami telah mencapai B200 sama dengan rasio cost-performance H100 tetapi setengah dari latensi generasi. Jadi, biaya per generasi tidak meningkat sambil sekarang memungkinkan kemungkinan real-time baru tanpa mengorbankan kemampuan model. Kadang lebih banyak bukan berarti lebih banyak tetapi berbeda, dan di sini kami telah mencapai tahap performa baru, memberikan tingkat pengalaman pengguna baru dalam generasi gambar menggunakan model SOTA.
Ini memungkinkan alat kreatif yang responsif, platform konten yang dapat diskalakan, dan struktur biaya yang berkelanjutan untuk AI generatif dalam skala besar.
Kesimpulan dan Langkah Selanjutnya
Penyebaran FLUX-dev menggunakan B200 mendemonstrasikan apa yang mungkin ketika hardware kelas dunia bertemu dengan software terbaik di kelasnya. Kami mendorong batas-batas kecepatan dan efisiensi inferensi di WaveSpeedAI, didirikan oleh Zeyi Cheng — kreator stable-fast, ParaAttention, dan mesin inferensi in-house kami. Dalam rilis berikutnya, kami akan fokus pada inferensi generasi video yang efisien dan bagaimana mencapai inferensi hampir real-time. Kemitraan kami dengan DataCrunch merepresentasikan peluang untuk mengakses GPU cutting-edge seperti B200 dan NVIDIA GB200 NVL72 yang akan datang (Pre-order cluster NVL72 GB200 dari DataCrunch) sambil mengembangkan bersama stack infrastruktur inferensi yang kritis.
Mulai Hari Ini:
- Website WaveSpeedAI
- WaveSpeedAI Semua Model
- Dokumentasi API WaveSpeedAI
- Instans on-demand/spot DataCrunch B200
Bergabunglah dengan kami saat kami membangun infrastruktur inferensi generatif tercepat di dunia.
Artikel Terkait

Panduan Lengkap Seedream 5.0-Preview: Generasi Gambar Cerdas

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Perbandingan Lengkap

Apple SHARP: Ubah Foto Apa Pun Menjadi 3D dalam Kurang dari Satu Detik

Seedream 4.5 vs Nano Banana Pro: Model AI Mana yang Terbaik?
Alternatif Adobe Firefly Terbaik di 2026: WaveSpeedAI untuk Generasi Gambar AI