Demo Online TranslateGemma + Panduan Memulai Cepat

Halo, saya Dora. Pernahkah Anda mendengar tentang “TranslateGemma”?
Dorongan untuk ini cukup kecil: seorang klien mengirimkan naskah dengan campuran bahasa Inggris dan Spanyol plus beberapa placeholder tersembunyi, dan saya tidak ingin mengawasi model terjemahan baris demi baris. Anda tahu jenisnya: satu langkah salah dan placeholder akan berantakan. Saya terus melihat “TranslateGemma” muncul di thread, jadi saya mencobanya, bukan karena itu baru, tetapi karena saya ingin cara yang lebih tenang untuk mendapatkan terjemahan yang setia tanpa merusak pemformatan. Spoiler: sebagian besar berhasil. Saya mengujinya selama Januari 2026 di beberapa demo online dan setup lokal. Berikut adalah apa yang benar-benar membantu, di mana ia tersandung, dan bagaimana saya akhirnya menyusun prompt untuk menjaganya tetap stabil.
Coba TranslateGemma Online (Tanpa Setup)
Saya tidak suka menginstal sesuatu hanya untuk melihat apakah itu berguna. Jadi saya mulai dengan TranslateGemma online. Jika Anda mencari “TranslateGemma online,” Anda akan menemukan segelintir playground yang dihosting: Hugging Face Spaces, demo Replicate, dan beberapa antarmuka web ringan yang membungkus checkpoint berbasis Gemma yang disetel untuk terjemahan. Beberapa memerlukan login gratis: beberapa tidak. Bagaimanapun, Anda biasanya dapat menempel teks dan memilih bahasa.
Apa yang mengejutkan saya: kecepatan cukup baik bahkan di demo bersama. Paragraf pendek kembali dalam satu atau dua detik: halaman yang lebih panjang membutuhkan waktu lebih lama, tetapi tidak cukup untuk mendorong saya menuju kopi. Saya terus menatap layar bagaimanapun. Kebiasaan lama, saya rasa. Perbedaan yang lebih besar bukanlah kecepatan, tetapi bagaimana saya merumuskan prompt.
Sebuah “Terjemahkan ke Prancis” sederhana berhasil, tetapi output melayang ketika teks mencampur nada, berisi kode inline, atau menggunakan variabel seperti {{first_name}}. Perbaikannya adalah serangkaian instruksi pendek dan eksplisit. Ketika demo mengekspos kolom “system prompt”, saya menggunakannya. Ketika tidak, saya menempatkan instruksi di bagian atas pesan pengguna.
Berikut adalah prompt minimal yang secara konsisten mengurangi pembersihan untuk saya:
- Beri nama bahasa sumber dan target.
- Katakan kepada model apa yang harus tetap tidak berubah (placeholder, blok kode, tag).
- Batasi teks sehingga model tahu di mana dimulai dan berhenti.
- Minta terjemahan murni tanpa komentar.
Contoh yang saya gunakan online:
Contoh yang saya gunakan online:
Terjemahkan teks berikut dari Inggris ke Spanyol. Jaga placeholder seperti {{first_name}}, {{price}}, dan tag HTML tetap tidak berubah. Pertahankan jeda baris dan tanda baca. Kembalikan hanya teks yang diterjemahkan, bukan apa pun lagi.
<<<
Subject: Welcome, {{first_name}}.
Your total is {{price}}.
Click <a href="/start">here</a> to begin.
>>>Ini tidak menghemat waktu pertama kali. Setelah dua larian, itu berhasil, sebagian besar karena saya berhenti memperbaiki placeholder yang rusak. Jika Anda hanya melakukan pemeriksaan akal sehat TranslateGemma online, coba bagian pendek dengan dan tanpa struktur itu. Perbedaannya muncul dengan cepat.
Format Template Obrolan yang Harus Anda Ikuti
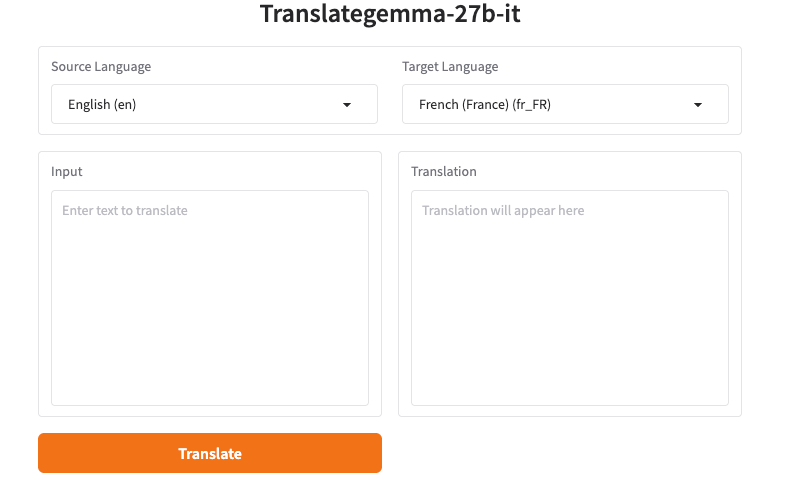 Model obrolan gaya Gemma merespons paling baik ketika Anda menghormati penanda giliran. Beberapa UI menambahkannya untuk Anda. Yang lain mengharapkan teks mentah. Jika Anda mengirimkan prompt secara langsung (API, Python, atau UI yang sangat sederhana), template yang jelas dan dapat diulang membantu.
Model obrolan gaya Gemma merespons paling baik ketika Anda menghormati penanda giliran. Beberapa UI menambahkannya untuk Anda. Yang lain mengharapkan teks mentah. Jika Anda mengirimkan prompt secara langsung (API, Python, atau UI yang sangat sederhana), template yang jelas dan dapat diulang membantu.
Dua pola yang dapat diandalkan berhasil untuk saya:
1. Template teks biasa (berfungsi di sebagian besar demo web)
Anda adalah asisten terjemahan yang presisi.
- Bahasa sumber: Inggris
- Bahasa target: Spanyol
- Jaga placeholder seperti {{...}}, backtick markdown, dan tag HTML tetap tidak berubah.
- Pertahankan tanda baca dan jeda baris. Jangan tambahkan penjelasan.
Teks untuk diterjemahkan:
<<<
[TEMPEL TEKS ANDA DI SINI]
>>>2. Gaya giliran obrolan Gemma (berguna di perpustakaan yang mengekspos template obrolan)
<start_of_turn>user
Anda adalah asisten terjemahan yang presisi.
Sumber: Inggris
Target: Spanyol
Aturan: jaga {{placeholder}}, blok kode, dan HTML tetap utuh: pertahankan jeda baris: hanya keluarkan terjemahan.
Teks:
<<<
[TEMPEL TEKS ANDA DI SINI]
>>>
<end_of_turn>
<start_of_turn>modelSaya tidak mengharapkan penanda giliran itu sangat penting, tetapi mereka penting. Tanpa mereka, saya melihat lebih banyak parafrase “membantu” (model mencoba meningkatkan redaksi). Dengan mereka, dan dengan input yang dibatasi, model tetap lebih dekat dengan tugas.
Detail-detail kecil yang membuat perbedaan besar:
- Beri nama bahasa secara eksplisit. “Dari Inggris ke Spanyol” berkinerja lebih baik daripada “Terjemahkan ke Spanyol.”
- Letakkan aturan sebelum teks. Jika Anda menyelusuri aturan setelah teks, mereka lebih mudah diabaikan.
- Batasi teks dengan awal/berhenti yang berbeda (
<<<dan>>>atau triple backticks). Ini mengurangi pemotongan yang tidak disengaja di awal atau akhir.
Jalankan TranslateGemma Secara Lokal (Python)
 Saya suka memiliki fallback lokal untuk pekerjaan yang lebih lama atau draf sensitif. Anggap saya paranoid, tetapi kadang-kadang cloud terasa terlalu… cerewet. Di mesin saya (32 GB RAM, GPU konsumen), checkpoint terjemahan berbasis Gemma yang lebih kecil berjalan dengan nyaman: yang lebih besar membutuhkan lebih banyak VRAM atau kuantisasi. Jika Anda hanya CPU, itu lambat tetapi dapat dilakukan dengan pengaturan yang hati-hati.
Saya suka memiliki fallback lokal untuk pekerjaan yang lebih lama atau draf sensitif. Anggap saya paranoid, tetapi kadang-kadang cloud terasa terlalu… cerewet. Di mesin saya (32 GB RAM, GPU konsumen), checkpoint terjemahan berbasis Gemma yang lebih kecil berjalan dengan nyaman: yang lebih besar membutuhkan lebih banyak VRAM atau kuantisasi. Jika Anda hanya CPU, itu lambat tetapi dapat dilakukan dengan pengaturan yang hati-hati.
Berikut adalah pola sederhana dengan Hugging Face Transformers. Saya telah membuat model_id generic dengan sengaja, pilih model terjemahan berbasis Gemma atau turunan Gemma yang Anda percayai dari Hub, idealnya yang didokumentasikan untuk terjemahan. Template di bawah ini mencerminkan prompt online.
# Diuji Jan 2026 dengan transformers >= 4.40
from transformers import AutoTokenizer, AutoModelForCausalLM, TextStreamer
import torch
model_id = "<your-gemma-translation-checkpoint>" # e.g., a Gemma chat or translation-tuned model
device = "cuda" if torch.cuda.is_available() else "cpu"
dtype = torch.float16 if device == "cuda" else torch.float32
# Load
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=dtype,
device_map="auto" if device == "cuda" else None
)
# Prompt template (plain text). Swap for chat turns if your model requires them.
prompt = (
"You are a precise translation assistant.\n"
"Source language: English\n"
"Target language: Spanish\n"
"Rules: keep placeholders like {{...}}, code blocks, and HTML tags unchanged: "
"preserve punctuation and line breaks: output only the translation.\n\n"
"Text:\n<<<\n"
"Subject: Welcome, {{first_name}}.\nYour total is {{price}}.\n"
"<p>Click <a href=\"/start\">here</a> to begin.</p>\n"
">>>\n"
)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
gen = model.generate(
**inputs,
max_new_tokens=300,
temperature=0.3,
top_p=0.9,
repetition_penalty=1.02,
do_sample=True,
eos_token_id=tokenizer.eos_token_id,
)
output = tokenizer.decode(gen[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(output)Beberapa catatan dari pengujian
- Jika checkpoint Anda menyertakan template obrolan, gunakan utilitas
apply_chat_template()perpustakaan alih-alih string manual. Ini memotong perilaku ganjil setengahnya. - Untuk input panjang, atur
max_new_tokenscukup tinggi dan jagatemperaturerendah (0,2–0,4). Sampling yang lebih hangat mengundang “perbaikan.” Beberapa membantu, beberapa… tidak begitu banyak. - Kuantisasi membantu di GPU yang lebih kecil. 4-bit (bitsandbytes) bertahan dengan baik untuk terjemahan langsung.
- Jika Anda memerlukan workload terjemahan batch, bungkus prompt dalam fungsi kecil dan alirkan baris. Saya menemukan chunking berdasarkan paragraf lebih aman daripada blob raksasa, kemungkinan lebih kecil kehilangan struktur.
Perlu menjalankan workload terjemahan tanpa mengelola infrastruktur GPU atau setup lokal?
Kami membangun WaveSpeed sehingga tim kami dapat memanggil model melalui API terpadu dan menangani tugas batch tanpa memutar server atau bergulat dengan driver → Coba di sini!
Kesalahan Umum dan Perbaikan
 Ini adalah pola yang saya jalankan paling banyak saat mencoba TranslateGemma online dan secara lokal, ditambah apa yang benar-benar mengurangi gesekan untuk saya.
Ini adalah pola yang saya jalankan paling banyak saat mencoba TranslateGemma online dan secara lokal, ditambah apa yang benar-benar mengurangi gesekan untuk saya.
Output Bukan dalam Bahasa Target
Saya melihat ini sebagian besar ketika saya tidak mendeklarasikan bahasa sumber. Input campuran bahasa membingungkan cukup untuk menyimpan frasa Inggris. Perbaikan yang berhasil:
- Beri nama kedua bahasa: “Terjemahkan dari Inggris ke Spanyol.” Jangan mengandalkan deteksi ketika akurasi penting.
- Turunkan suhu (0,2–0,4) dan gunakan
repetition_penaltyringan (sekitar 1,02). Itu mendorong model menjauh dari penulisan ulang kreatif. - Tambahkan baris penjaga akhir: “Jika teks sudah dalam bahasa Spanyol, kembalikan tidak berubah.” Ini memotong over-translation pada snippet bilingual.
Pemformatan atau Placeholder yang Hilang
Ini adalah yang besar dengan email pemasaran dan string produk. Lari awal rusak {{variables}} atau mengurutkan ulang HTML. Apa yang membantu:
- Jadilah eksplisit: “Jaga placeholder seperti
{{...}}dan tag HTML tetap tidak berubah. Jangan terjemahkan di dalam pagar kode.” - Batasi input dan pertahankan jeda baris. Pola
<<<dan>>>berfungsi lebih baik daripada mengandalkan baris kosong. - Untuk konten yang rapuh, apit placeholder dengan penanda dalam prompt: “Placeholder dilindungi dengan kurung kurawal ganda seperti
{{this}}. Jangan ubah mereka.” Jika demo terus menjatuhkan kurung kurawal, saya sementara mengganti{{dengan[[[dan}}dengan]]]sebelum terjemahan, kemudian ditukar kembali. Ini tidak elegan, tetapi lebih aman untuk pekerjaan massal.
Model Menulis Ulang Alih-alih Menerjemahkan
Kadang-kadang output berbunyi seperti penulisan ulang editor, bukan terjemahan. Membantu dalam beberapa konteks, mengganggu di sebagian besar. Perbaikan praktis saya:
- Nyatakan peran dan batasan di bagian atas: “Anda adalah asisten terjemahan. Keluarkan hanya terjemahan yang setia. Tidak ada ringkasan, tidak ada penjelasan.”
- Suhu lebih rendah dan hindari
max_new_tokenspanjang pada input pendek: ruang tambahan mendorong komentar di beberapa checkpoint. - Jika model masih menghiasi, coba template giliran obrolan dengan berhenti yang jelas. Dalam kode lokal, atur urutan berhenti ke penanda giliran Anda (misalnya,
<end_of_turn>). Di demo yang dihosting tanpa dukungan berhenti, menambahkan “Kembalikan hanya teks yang diterjemahkan” mengurangi omong kosong sekitar 80% dari waktu.
Satu catatan senyap lagi: beberapa checkpoint komunitas yang diberi label untuk terjemahan sebenarnya adalah model umum yang disetel dengan instruksi. Mereka akan menerjemahkan, tetapi mereka lebih cerewet. Jika Anda mengalami ketiga masalah sekaligus, coba checkpoint berbeda atau yang lebih kecil dan lebih ketat. Lebih sedikit pintar sering berarti lebih setia di jalur ini. Dan jujur, itu semua yang saya butuhkan.
Apakah Anda sudah mencoba TranslateGemma? Apa prompt pilihan Anda untuk menjaga placeholder tetap utuh, atau teks paling sulit yang membuatnya tersandung? Bagikan kemenangan, kegagalan, atau trik favorit Anda di bawah!
Artikel Terkait

Seedance 2.0 Segera Hadir: Model Video Generasi Berikutnya ByteDance dengan Audio Asli

Panduan Lengkap Seedance 2.0: Pembuatan Video Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Perbandingan Generasi Video AI Terlengkap

Panduan Lengkap Seedream 5.0-Preview: Generasi Gambar Cerdas

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Perbandingan Lengkap
