Seedance 1.5 Pro: Langkah Besar Menuju Generasi Audio-Visual Asli

Saat video generatif bergerak ke produksi nyata, visual saja tidak lagi cukup. Alur kerja modern semakin memerlukan video dan audio dihasilkan bersama—secara native dan tersinkronisasi.
Seedance 1.5 Pro, model generasi audio-visual nativ ByteDance berikutnya, kini tersedia di WaveSpeedAI. Dibangun dari awal untuk sinkronisasi yang andal, dapat dikontrol, dan siap produksi, ini menandai langkah penting menuju generasi multimodal yang benar-benar terpadu.
Dalam artikel berteknis mendatang, kami akan melihat lebih dekat Seedance 1.5 Pro—mengeksplorasi kemampuan model, kasus penggunaan praktis, wawasan benchmark, dan arsitektur multimodal di baliknya.
Kemampuan Model Inti (Fitur & Penggunaan Praktis)
1. Generasi Audio-Visual Native dengan Sinkronisasi Fidelitas Tinggi
Terobosan paling fundamental dalam Seedance 1.5 Pro adalah paradigma generasi audio-visual-native-nya. Dalam satu pass inferensi, model menghasilkan frame video dan jalur audio yang sesuai, menjaga ritme ucapan, gerakan bibir, gerakan karakter, dan dinamika kamera selaras dalam referensi temporal yang sama.
Di seluruh beberapa putaran evaluasi, Seedance 1.5 Pro secara konsisten mengungguli pipeline penjahitan “video + TTS” arus utama — terutama dalam dialog panjang, gerakan bibir cepat, dan skenario aksi-dengan-suara di mana pendekatan tradisional cenderung melenceng.
Prompts: Seorang pria tampan berdiri di puncak pegunungan yang diselimuti kabut. Dia mengenakan pakaian petualangan gelap yang ramping dan praktis — jaket tahan angin batu bara gelap, celana panjat profesional, dan ransel di kedua bahu. Angin gunung lembut mengacak rambutnya; ekspresinya tenang dan tegas. Di belakangnya, awan dan kabut yang bergolak berputar di antara batu-batu bergerigi, sesekali terbuka untuk mengungkapkan puncak bersalju yang jauh. Kamera perlahan bergerak maju dari belakang saat dia memandang ke dalam jurang awan bergulir di bawah. Di udara yang dingin, napasnya mengembun menjadi kabut putih, menambah detail atmosfer alami. Dia sedikit berputar menghadap kamera, mata tajamnya penuh dengan determinasi yang tak tergoyahkan, dan berkata dengan suara yang stabil dan kuat: “Aku suka tantangan.”
2. Generasi Multi-Pembicara, Multi-Bahasa, dan Sadar Dialek
Seedance 1.5 Pro mendukung generasi audio-visual di seluruh bahasa global utama dan dialek regional. Ini melestarikan waktu spesifik bahasa, fonem, dan ekspresi, memberikan sinkronisasi bibir yang presisi dan keselarasan emosional yang alami—bahkan di seluruh beberapa pembicara dan pertukaran bahasa cepat.
Prompts: Sebuah film pendek gaya anime Jepang sinematik yang menggambarkan keagungan festival kembang api musim panas. Penekanan ditempatkan pada tekstur detail tinggi (kain kimono, rambut, kulit), micro-expressions halus, gerakan alami dan lancar, serta storytelling yang lembut dan kaya emosi. Kembang api menyerupai pencahayaan sinematik lembut, meningkatkan suasana emosional. (prompt dihilangkan…) Dia lembut berkata dalam bahasa Jepang: “Aku sangat menyukaimu”. Pria itu membungkuk sedikit dan memutuskan untuk berkata: “Sebenarnya, aku juga menyukaimu”. (prompt dihilangkan…)
3. Gerakan Ekspresif & Kinerja Emosional
Seedance 1.5 Pro bergerak melampaui strategi gerak yang konservatif dan berisiko rendah. Animasi karakter menunjukkan amplitudo yang lebih besar, variasi tempo yang lebih kaya, dan niat emosional yang lebih jelas — sambil mempertahankan stabilitas keseluruhan.
Ekspresi wajah berkembang dari hanya dapat dikenali menjadi benar-benar performatif: micro-expressions, transisi emosional, dan bahasa tubuh selaras secara alami dengan dialog yang diucapkan. Hasilnya adalah gerakan yang terasa jauh lebih hidup.
Prompts: Seorang astronot muda dalam setelan ruang angkasa usang duduk di kokpit redup pesawat ruang angkasa. Visor helm tertutup kabut dan goresan, dan panel kontrol berkilau dengan lampu oranye-kuning, menciptakan suasana tegang dan sepi. Video dimulai dengan frame pembuka statis ini. Kamera kemudian dengan cepat memperbesar wajah astronot sebelum memotong ke eksterior, mengungkapkan pesawat ruang angkasa melintasi badai seperti badai puing kosmik. Gaya thriller sci-fi. Musik latar: synthesizer elektronik rendah dipasangkan dengan string yang membengkak cepat untuk membangun suspense. Efek suara: dengungan mesin mendesak dan kebisingan badai luar angkasa yang melolong. Dialog: “Di kekosongan ruang angkasa, satu gerakan salah…” diikuti oleh kesunyian singkat, diakhiri dengan: “Mayday… sistem gagal.”
4. Estetika Visual Sinematik dan Berorientasi Fotoreal
Secara visual, Seedance 1.5 Pro cenderung ke arah tampilan live-action alami daripada stilisasi berat atau efek yang berlebihan.
Pencahayaan, komposisi, harmoni warna, dan depth-of-field konsisten stabil, menghasilkan output yang mendekati sinematografi tingkat komersial daripada citra sintetis.
Prompts: POV orang pertama dari kursi depan roller coaster baja raksasa. Roller coaster mencapai puncak dan jatuh lurus ke dalam terowongan gelap. Pemandangan sekitarnya (taman hiburan saat matahari terbenam) sedikit buram, sementara angin diwakili sebagai partikel udara bersiul.
5. Adaptasi Durasi Video Otomatis
Dengan menetapkan parameter panjang video ke -1, Seedance 1.5 Pro secara otomatis memilih durasi paling sesuai dalam rentang 4–12 detik (hanya integer detik).
Model mengevaluasi ritme narasi, kelengkapan gerakan, dan penutupan audio-visual untuk memilih titik akhir yang alami. Ini mengurangi generasi terbuang dan penyetelan manual yang disebabkan oleh durasi tetap yang dipilih dengan buruk.
Prompts: Gaya pixel art 8-bit, pahlawan berlari dan melompat saat matahari terbenam, dengan efek scanline dan musik video game retro.
6. Efek Built-In melalui Kontrol Prompt
Seedance 1.5 Pro menyertakan berbagai efek built-in langsung dalam model dasar. Ini dapat dipicu melalui instruksi prompt daripada sepenuhnya mengandalkan kompositing pasca-produksi.
Ini sangat berharga untuk konten animation-heavy atau bergaya — seperti motion comics — di mana kepadatan dan waktu efek sangat penting.
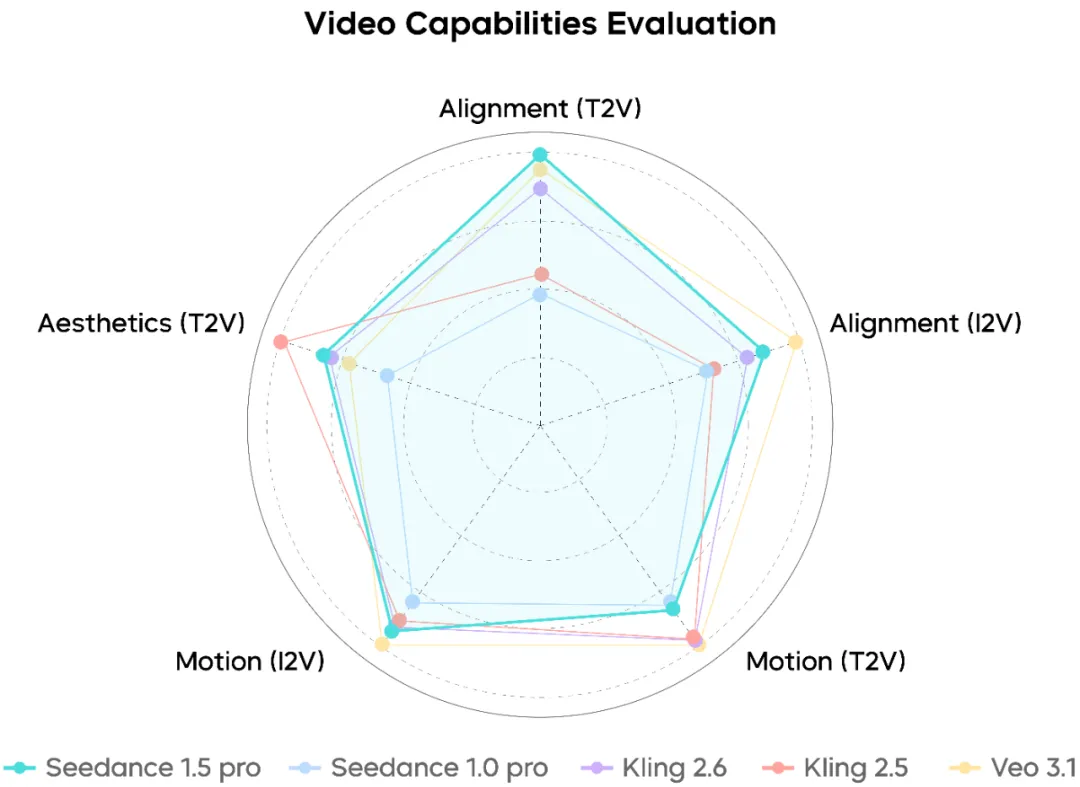
Performa Generasi Video
Seedance 1.5 Pro menunjukkan pemahaman kuat tentang prompt kompleks yang melibatkan koreografi kamera, pengurutuan aksi, dan pacing narasi. Close-up wajah terlihat alami, sementara long takes dan gerakan kamera gabungan tetap relatif mulus dan koheren.
Meskipun demikian, dalam skenario gerakan intensitas sangat tinggi, masih ada ruang untuk peningkatan stabilitas lebih lanjut.
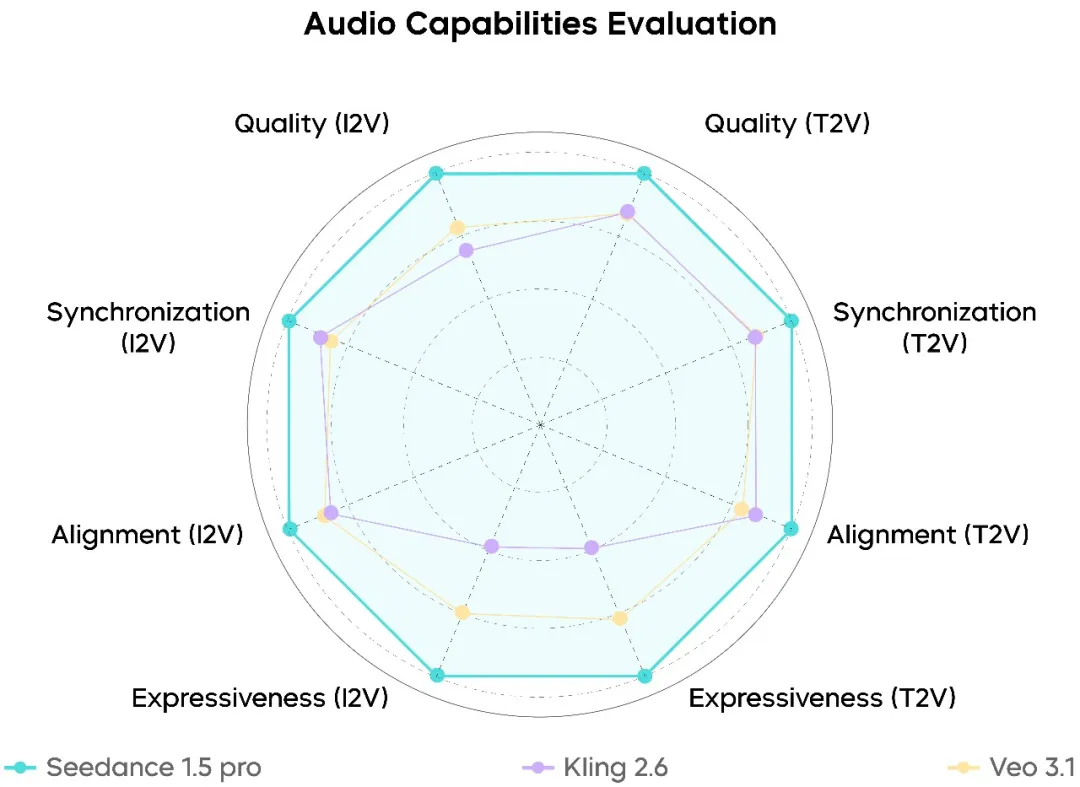
Performa Generasi Audio
Di sisi audio, Seedance 1.5 Pro duduk dengan teguh di tingkat teratas model saat ini:
- Suara manusia yang sangat alami dengan artefak mekanik berkurang
- Karakteristik audio spasial dan reverb yang lebih realistis
- Jauh lebih sedikit kesalahan keselarasan audio-visual
Performa sangat kuat dalam dialog Mandarin dan heavy-dialek, di mana kelengkapan dan kejelasan pengucapan sudah memenuhi persyaratan produksi nyata.
Arsitektur Ko-Generasi Multimodal: Bagaimana Visi dan Audio Tetap Tersinkronisasi
Seedance 1.5 Pro bukan patchwork modul independen — pipeline pelatihan dan inferensinya dirancang ulang dari awal hingga akhir.
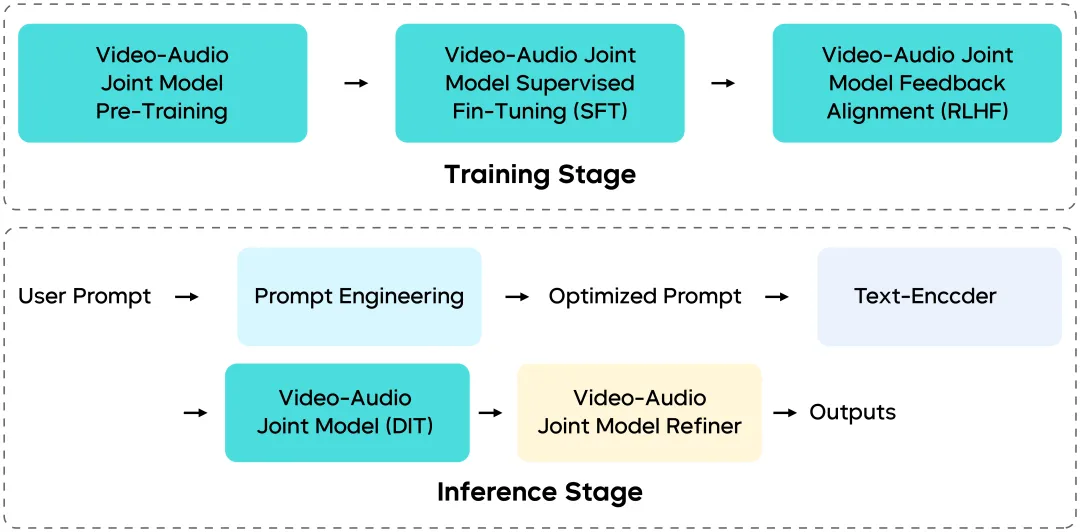
Arsitektur Multimodal Terpadu (Berbasis MMDiT)
Dibangun di atas arsitektur MMDiT-style yang ditingkatkan, model memungkinkan interaksi mendalam antara aliran visual dan audio dalam ruang temporal yang sama, memastikan:
- Sinkronisasi temporal
- Konsistensi semantik
- Emosi dan ritme yang terkoordinasi
Pelatihan multi-tugas modal-campuran berskala besar lebih lanjut meningkatkan generalisasi di seluruh tugas downstream.
Pipeline Data Multi-Tahap
Pipeline data dirancang untuk menyeimbangkan:
- Keselarasan audio-visual
- Ekspresi gerakan
- Jadwal pelatihan berbasis kurikulum
Selain data video-caption tradisional, deskripsi audio terstruktur diperkenalkan secara sistematis, memungkinkan model menginternalisasi ruang semantik audio-visual gabungan yang lebih kaya.
Pelatihan Pasca-Harian & RLHF
Dataset audio-visual berkualitas tinggi digunakan untuk fine-tuning yang diawasi, bersama model RLHF yang dirancang khusus untuk output audio-visual, memperkuat:
- Kualitas gerakan
- Estetika visual
- Kesetiaan audio
Inferensi Efisien & Kesiapan Deployment
Melalui distilasi multi-tahap, kuantisasi, dan optimisasi inferensi paralel:
- Jumlah evaluasi fungsi (NFE) berkurang secara signifikan
- Inferensi end-to-end mencapai 10×+ speedup sambil mempertahankan kualitas
Efisiensi ini adalah alasan utama Seedance 1.5 Pro dapat di-deploy dengan andal di WaveSpeedAI.
Kasus Penggunaan Siap Produksi
Seedance 1.5 Pro sangat cocok untuk:
- E-commerce lintas batas dan iklan terlokalisasi
- Konten narasi dan episodik short-form
- Motion comics dan animasi ekspresif
- Brand storytelling dan pemasaran sinematik
- Pre-visualisasi film dan validasi konsep
Pemikiran Akhir
Nilai Seedance 1.5 Pro bukanlah tentang membuktikan bahwa model dapat menghasilkan suara—ini tentang menetapkan panggung agar koordinasi audio-visual menjadi default yang dapat diandalkan.
Untuk tim yang mengejar produksi konten yang dapat diskalakan, pendekatan terpadu dari awal ini menjanjikan lebih sedikit perbaikan pasca-produksi, kebebasan kreatif yang lebih besar, dan alur kerja video generatif yang dirancang untuk bertahan dalam lingkungan produksi nyata.
Artikel Terkait

Seedance 2.0 Segera Hadir: Model Video Generasi Berikutnya ByteDance dengan Audio Asli

Panduan Lengkap Seedance 2.0: Pembuatan Video Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Perbandingan Generasi Video AI Terlengkap

Panduan Lengkap Seedream 5.0-Preview: Generasi Gambar Cerdas

Review Vidu Q3: Perbandingan dengan Sora 2, Wan 2.6, Seedance 1.5, Veo 3.1, dan Grok Imagine Video
