GLM-4.7-Flash vs GLM-4.7: Model Mana yang Cocok untuk Proyek Anda?

Halo teman-teman saya. Saya Dora. Jika ini terdengar familiar, Anda tidak sendirian. Saya pernah di sana: menatap antrian prompt kecil dan berulang yang hanya butuh jawaban cepat dan solid—sementara beberapa tugas penalaran multi-langkah yang bandel duduk di sudut, diam-diam menuntut jauh lebih banyak tenaga.
Jadi akhirnya saya mengajukan pertanyaan dengan lantang: di mana sebenarnya GLM-4.7-Flash yang ringkas dan secepat kilat bersinar, dan di mana Anda perlu membawa GLM-4.7 yang lebih berat dan lebih terukur? Ini adalah jawaban langsung, tanpa hype yang saya dapatkan—didasarkan pada real runs, benchmark ketika penting, dan tujuan tenang membuat stack harian Anda terasa jauh lebih ringan. Jika Anda pernah berhenti di “model mana yang seharusnya saya gunakan di sini?”, ini adalah untuk Anda.
Jawaban 30 Detik
Jika kecepatan dan biaya rendah adalah yang utama, GLM-4.7-Flash kemungkinan akan terasa tepat. Jika pekerjaan Anda bergantung pada kedalaman penalaran, tooling, atau output berkualitas lebih tinggi, GLM-4.7 adalah pilihan yang lebih stabil. Sisanya adalah nuansa di sekitar latency budget, ukuran konteks, dan bagaimana prompt Anda bersikap di bawah tekanan.
Pilih Flash Jika…
Flash bukanlah “lebih lemah”—hanya sangat jujur tentang apa yang baik untuk dilakukannya.
- Anda mengirimkan banyak pekerjaan kecil: ringkasan, tag, draft, transformasi cepat.
- Latency lebih penting daripada menyisir 10% kualitas terakhir.
- Anda bereksperimen, membuat prototipe, atau membangun interaksi UI yang seharusnya terasa instan.
- Wobble sesekali dalam langkah penalaran panjang tidak akan menggagalkan Anda.
- Anda menginginkan model default yang lebih murah dan dapat meningkat ke GLM-4.7 hanya ketika diperlukan.
Pilih GLM-4.7 Jika…
Ini adalah model “jangan sampai salah” Anda.
- Anda peduli tentang keandalan kode, penalaran multi-langkah, atau presisi penggunaan tool.
- Prompt panjang, instruksi ketat, atau output perlu konsisten.
- Anda menjalankan evaluator, tes, atau alur kerja di mana satu kesalahan mahal.
- Anda membutuhkan hasil yang lebih kuat pada tugas pengkodean dan konteks panjang.
- Anda dapat mentolerir biaya lebih tinggi dan sedikit lebih banyak latency untuk hasil yang lebih baik.
Perbedaan Arsitektur
 Saya tidak mengejar jumlah parameter untuk olahraga, tapi arsitektur menjelaskan banyak tentang perilaku: mengapa satu model terasa cepat dan yang lain terasa terukur.
Saya tidak mengejar jumlah parameter untuk olahraga, tapi arsitektur menjelaskan banyak tentang perilaku: mengapa satu model terasa cepat dan yang lain terasa terukur.
Parameter Count & Active Experts
GLM-4.7 tampaknya menjalankan backbone yang lebih besar dan (dari catatan publik) menggunakan expert routing yang memprioritaskan penalaran. Flash dioptimalkan untuk throughput, routing yang lebih ringan, fewer active experts per token, dan pengaturan efisiensi agresif. Dalam praktik, itu cenderung menunjukkan:
- Flash: per-token compute yang lebih rendah, waktu token pertama yang cepat, tetapi dapat menghilangkan rantai penalaran di bawah tekanan.
- GLM-4.7: lebih banyak compute per token, path penalaran yang lebih stabil, pilihan tool-call yang lebih baik.
Jika Anda membaca diagram provider, Anda akan melihat hints tentang mixture-of-experts (MoE) dan activation sparsity. Angka yang tepat bergeser di seluruh versi, jadi saya memperlakukannya sebagai directional, bukan absolute. Ide besarnya: Flash menghabiskan lebih sedikit “pemikiran” per token jadi bergerak lebih cepat; GLM-4.7 berpikir lebih lama dan tersandung lebih sedikit pada edge case.
Context Window & Output Limit
Dua pertanyaan praktis lebih penting daripada headline context number:
- Seberapa jauh ke dalam prompt panjang, kualitas bertahan?
- Ketika output menjadi panjang, apakah model kehilangan benang merah?
Flash biasanya mengiklankan context window yang sehat, tetapi kualitas cenderung meruncing lebih cepat dengan prompt sangat panjang atau instruksi padat. GLM-4.7 mempertahankan kohesi lebih dalam ke dalam konteks panjang dan tetap lebih patuh pada struktur dalam output panjang. Jika Anda mengemas knowledge base, GLM-4.7 adalah default yang lebih aman. Jika Anda membagi input atau menggunakan retrieval untuk menjaga prompt tetap slim, Flash sering cukup baik—dan jauh lebih cepat.
Perbandingan Benchmark
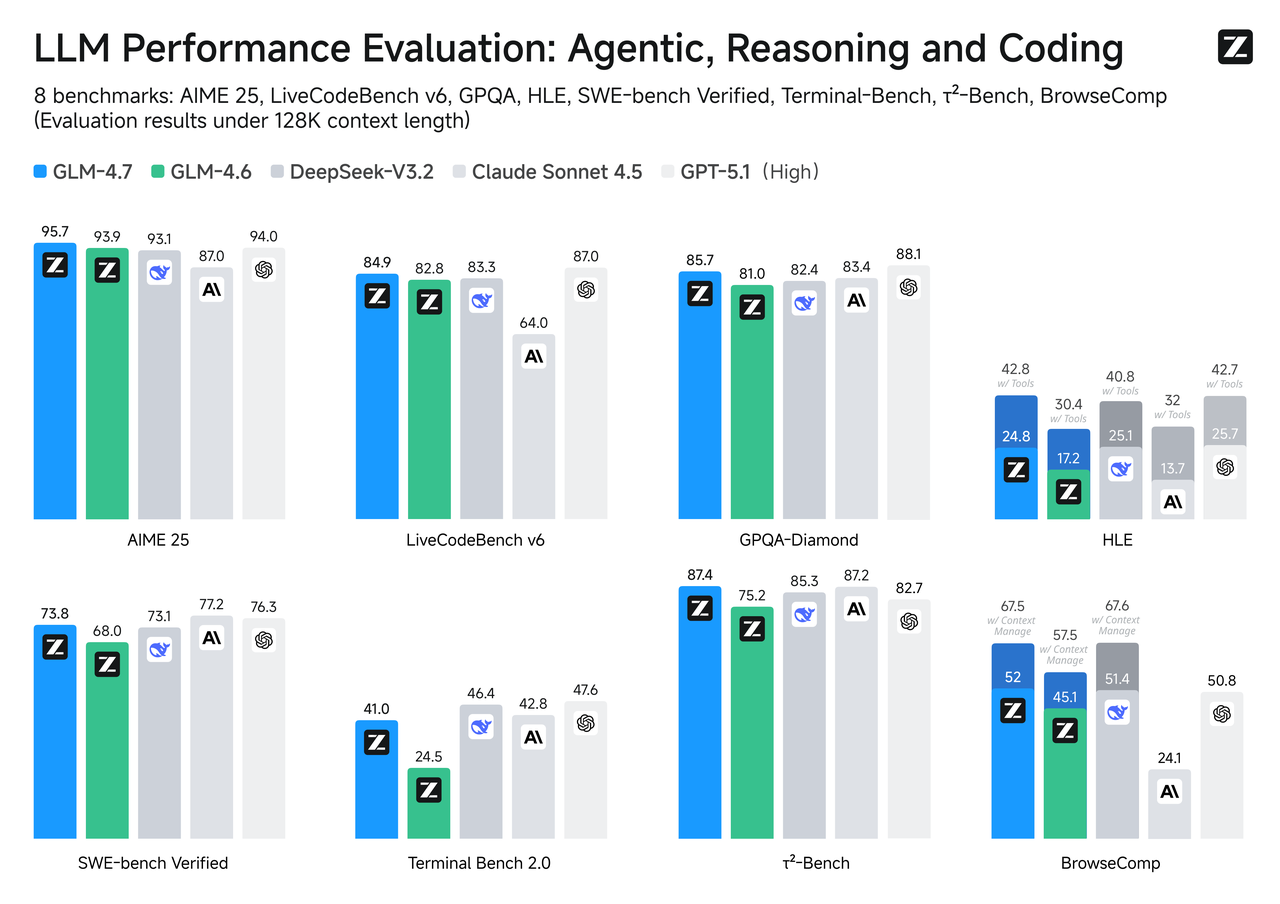 Benchmark bukan cerita selengkapnya, tetapi mereka adalah kompas yang berguna, terutama ketika use case Anda selaras dengan tugas.
Benchmark bukan cerita selengkapnya, tetapi mereka adalah kompas yang berguna, terutama ketika use case Anda selaras dengan tugas.
SWE-bench Verified
Untuk perubahan kode yang benar-benar harus dikompilasi dan lulus tes, GLM-4.7 cenderung rank di atas sibling Flash-nya. Itu sesuai dengan apa yang Anda harapkan dari model yang dioptimalkan untuk kedalaman penalaran dan penggunaan tool. Flash dapat draft perbaikan dan menjelaskan kode dengan baik, tetapi ketika patch memerlukan beberapa pengeditan terkoordinasi di seluruh file, GLM-4.7 lebih mungkin mengikuti chain tanpa menghilangkan langkah.
Jika pipeline Anda mencakup auto-PR atau repair loop, sebaiknya lakukan sanity check dengan sample kecil lebih dulu. Perbedaannya muncul lebih banyak pada isu multi-hop daripada pada tweak single-file.
LiveCodeBench / τ²-Bench
Pada benchmark koding live atau time-rotating, GLM-4.7 umumnya track lebih dekat ke top tier mengingat reasoning budget yang lebih berat. Flash, dioptimalkan untuk kecepatan, duduk satu tier lebih rendah tetapi merespons dengan cepat. Jika produk Anda mengandalkan kualitas code synthesis lebih daripada interaction speed, GLM-4.7 adalah pilihan conservative. Jika kodenya advisory (Anda akan meninjau anyway) dan responsiveness penting, Flash bisa menjadi trade yang tepat.
Kecepatan & Latency
Di sini splitnya terasa paling jelas. Flash sering mengembalikan token pertama dengan terasa lebih cepat, dan total time-to-last-token tetap rendah untuk output short dan medium. Itu menambah jika Anda menjalankan banyak small call atau streaming ke UI.
GLM-4.7 dimulai lebih lambat dan berjalan lebih berat, tetapi lebih stabil pada generasi panjang dan urutan tool-call kompleks. Anda akan melihat lebih sedikit stall, lebih sedikit detour aneh, dan adhesi lebih baik ke function schema.
Jika Anda membangun sistem:
- Gunakan Flash untuk momen UX lalu lintas tinggi: autocomplete, ringkasan cepat, bantuan inline.
- Gunakan GLM-4.7 untuk slow lane: evaluator, code action, policy check, final pass.
Aturan routing sederhana sering membayar untuk dirinya sendiri: mulai dengan Flash, escalate ke GLM-4.7 ketika confidence drop atau threshold terlampaui. Biarkan rules memutuskan jadi Anda tidak harus.
Breakdown Harga
Harga bergeser menurut region dan provider, jadi saya perlakukan angka sebagai moving target dan jaga struktur tetap stabil.
Flash Free Tier vs GLM-4.7 Pay-per-Token
-
Flash: Banyak platform mengekspos tier free atau biaya rendah untuk model seperti Flash, dengan rate limit murah dibanding flagship model. Bagus untuk prototyping, background chore, dan UI polish.
-
GLM-4.7: Biasanya billed per token pada rate lebih tinggi. Better cost-to-value pada tugas serious, tetapi mudah overspend jika Anda tinggalkan sebagai default.
 Tips praktis:
Tips praktis: -
Cap output token secara default. Naik cap hanya di route yang membutuhkannya.
-
Gunakan retrieval untuk menjaga prompt tetap short: jangan tuang seluruh corpus ke window.
-
Cache hasil sub-deterministic (regex map, schema snippet, few-shot block) jadi Anda tidak bayar lagi.
-
Log token cost per route. Report yang benar-benar Anda baca adalah yang duduk di workflow mingguan Anda, bukan yang paling banyak chart.
Ketika ragu, mulai murah, ukur, kemudian promote. Escalation mengalahkan optimism.
Pilih menurut Use Case
Ini adalah cara saya akan slot mereka ketika goal adalah fewer headache:
- Content ops lalu lintas tinggi (snippet, subject line, metadata): Flash. Menang adalah throughput dan consistency pada biaya rendah.
- Support macro dan quick triage: Flash dulu, kemudian escalate ke GLM-4.7 jika detection flag complexity atau policy risk.
- Research note, synthesis, structured summary: Flash untuk skim; GLM-4.7 untuk pass yang harus source-faithful dan well-scaffolded.
- Code assistance: Flash untuk explanations dan “apa yang dilakukan ini?”; GLM-4.7 untuk multi-file edit, migration, dan test-aware change.
- Data cleanup dan transformation: Flash bagus untuk simple mapping; GLM-4.7 untuk strict schema, validation, dan multi-step join.
- Agent dan tool use: GLM-4.7. Anda akan dapatkan function argument lebih reliable dan fewer retry.
- Long-context reading atau doc-grounded QA: GLM-4.7 jika Anda push window; Flash jika Anda keep chunk lean.
Beberapa field note yang saya keep close:
- Short prompt hide perbedaan. Gap menunjukkan ketika instruksi dense atau output harus follow struktur.
- Routing membantu. Bahkan rule sederhana, “Flash kecuali prompt > N token, kemudian GLM-4.7”, save uang tanpa drama.
- Guardrail penting lebih daripada model choice untuk tugas repetitive. Validation, retry, dan small checker prevent downstream mess.
- Jangan fetishize kecepatan. Di bawah satu detik terasa “instant” untuk sebagian besar user. Setelah itu, stable behavior beat shave 100 ms.
Mengapa ini penting: tools usia baik ketika mereka reduce mental load. Flash keep small stuff light. GLM-4.7 carry heavy box tanpa drop mereka. Sebagian besar stack butuh keduanya.
Jika Anda unsure, mulai dengan Flash sebagai default Anda dan buat clear lane untuk GLM-4.7. Biarkan route, bukan mood, putuskan. Mileage Anda mungkin berbeda, dan itu fine.
Saya masih notice, pada quiet day, bagaimana split ini reduce decision fatigue. Tidak ada yang flashy—hanya fewer headache.
Bagaimana saya benar-benar menjalankan split ini dalam praktik
 Ketika saya perlu route fast job ke Flash dan escalate yang lebih berat ke GLM-4.7 tanpa babysit script, saya gunakan WaveSpeed — platform kami sendiri.
Ketika saya perlu route fast job ke Flash dan escalate yang lebih berat ke GLM-4.7 tanpa babysit script, saya gunakan WaveSpeed — platform kami sendiri.
Kami built untuk handle model switch, concurrency, dan batch call cleanly, jadi pattern “Flash first, escalate ketika perlu” tetap simple daripada brittle.
Jika Anda menjalankan banyak small call dan tidak ingin routing logic menjadi hal lain untuk maintain, coba Wavespeed!
FAQ: GLM-4.7-Flash vs GLM-4.7
1. Apa perbedaan utama antara GLM-4.7-Flash dan GLM-4.7?
GLM-4.7-Flash adalah varian ringan dan dioptimalkan dari GLM-4.7. Ini mencapai inference lebih cepat dan biaya lebih rendah dengan mengurangi jumlah active expert, menyederhanakan routing, dan menerapkan tweak efisiensi. GLM-4.7 mempertahankan backbone yang lebih besar dan kemampuan penalaran yang lebih kuat, excel dalam complex multi-step reasoning, long-context coherence, dan precise tool calling.
Singkatnya: Flash trade beberapa intelligence untuk kecepatan; GLM-4.7 prioritaskan depth dan reliability.
2. Model mana yang lebih cepat, dan dalam skenario mana perbedaan kecepatan paling terlihat?
GLM-4.7-Flash memiliki significantly lower time-to-first-token (TTFT) dan per-token latency. Ini bersinar dalam high-throughput, low-latency use case seperti real-time UI interaction, content summarization, metadata generation, dan rapid prototyping.
GLM-4.7 memiliki higher startup overhead dan heavier computation tetapi tetap lebih stabil untuk long output atau complex tool-call sequence. Dalam praktik, Flash noticeably lebih cepat untuk short-to-medium output (di bawah 500 token).
3. Model mana yang lebih kuat dalam intelligence dan penalaran?
GLM-4.7 outperform Flash dalam multi-step reasoning, code reliability, tool use, dan long-context task. Contoh:
- SWE-bench Verified: GLM-4.7 lead dalam multi-file code editing dan coordinated patch.
- LiveCodeBench / τ²-Bench: GLM-4.7 deliver higher-quality code, terutama untuk deep-reasoning scenario.
Flash cocok untuk single-file edit atau assistive task yang tolerate human review, tetapi degrade lebih cepat pada long reasoning chain atau dense prompt.
4. Bagaimana context length dan output limit dibandingkan?
Kedua model berbagi similar context window, tetapi GLM-4.7 maintain lebih baik coherence dan instruction-following pada very long context (>32k token) atau dense prompt. Flash degrade lebih cepat di bawah extreme prompt length atau density—pair dengan chunking atau RAG untuk hasil terbaik.
5. Bagaimana cara saya memilih berdasarkan pricing dan cost control?
GLM-4.7-Flash biasanya menawarkan higher free quota dan lower (atau bahkan zero) per-token pricing, menjadikannya ideal untuk prototyping, background task, dan high-volume low-risk call. GLM-4.7 memiliki higher per-token cost tetapi better value untuk critical task.
Rekomendasi: default ke Flash, escalate ke GLM-4.7 untuk complex work, dan selalu set token cap dan caching untuk prevent overspending.
Artikel Terkait

Seedance 2.0 Segera Hadir: Model Video Generasi Berikutnya ByteDance dengan Audio Asli

Panduan Lengkap Seedance 2.0: Pembuatan Video Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Perbandingan Generasi Video AI Terlengkap

Panduan Lengkap Seedream 5.0-Preview: Generasi Gambar Cerdas

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Perbandingan Lengkap
