Jalankan GLM-4.7-Flash Secara Lokal: Setup Ollama, Mac & Windows

Hai, saya Dora. Beberapa hari lalu, sedikit gesekan membuat saya tertarik pada hal ini: saya terus menunggu penyelesaian tugas draf kecil dari jarak jauh. Bukan hitungan menit, hanya cukup penundaan hingga saya beralih ke email dan kehilangan fokus. Minggu lalu (Jan 2026), saya mencoba menjalankan GLM-4.7-Flash secara lokal untuk melihat apakah menghilangkan beberapa detik benar-benar akan membantu saya berpikir lebih jernih.
Versi singkat: berhasil, tetapi bukan untuk alasan yang glamor. GLM-4.7-Flash terasa lebih seperti asisten yang stabil daripada model headline. Cukup cepat untuk membuat saya tetap dalam aliran pemikiran, dan cukup ringan untuk dijalankan di laptop tanpa merusaknya. Saya akan berbagi apa yang berhasil, di mana ia terhenti, dan pengaturan yang membuat semuanya membosankan, dalam cara yang baik.
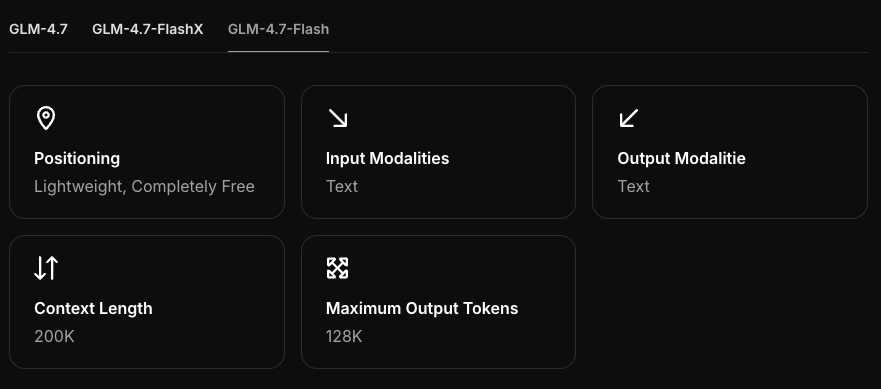
Persyaratan Hardware
GPU / RAM Minimum
Saya menjalankan GLM-4.7-Flash di tiga mesin:
- MacBook Pro M3 Pro (CPU 12-core / GPU 18-core, RAM 36 GB)
- Mac mini M2 (memori terpadu 24-GB)
- Desktop Windows dengan RTX 4090 (VRAM 24-GB)
Dari pengujian tersebut, dasar praktis:
- CPU-only (Mac/Windows/Linux): memori sistem 16 GB berfungsi, 32 GB lebih nyaman. Harapkan token pertama lebih lambat.
- Apple Silicon (Metal): memori terpadu 16 GB dapat digunakan dengan kuantisasi 4-bit/5-bit dan konteks sederhana (2–4K). 8 GB terasa sempit.
- NVIDIA: 8–12 GB VRAM adalah minimum yang akan saya coba untuk kuant 4-bit. 16 GB+ lebih nyaman.
GLM-4.7-Flash terasa seperti model ukuran menengah (pikirkan di bawah 10–12B params). Dalam 4-bit, Anda biasanya melihat ~5–6 GB memori perangkat ditambah KV cache. Jika Anda mendorong konteks panjang atau banyak prompt paralel, memori meningkat.
Spesifikasi yang Direkomendasikan
Jika Anda ingin rasakan “selalu responsif”:
- Apple Silicon: M3 atau lebih baru dengan memori terpadu 24–36 GB: jaga konteks 4–8K.
- NVIDIA: 24 GB VRAM (misalnya, 3090/4090) memberikan ruang untuk konteks lebih tinggi dan konkurensi.
- Storage: SSD cepat: model dimuat lebih cepat dan swap lebih sedikit.
Saya perhatikan model berhenti terasa “flashy” ketika tekanan memori dimulai, page-outs atau VRAM spills menambah stutter halus yang mengganggu aliran. Sedikit ruang tambahan membuat perbedaan besar.
Pengaturan Ollama
Saya menggunakan Ollama karena membuat run lokal sederhana dan konsisten di berbagai mesin. Konteks versi penting di sini.
Pasang Ollama 0.14.3+
- macOS: brew install ollama (atau perbarui dengan brew upgrade ollama).
- Windows: gunakan installer resmi dari situs Ollama.

- Linux: ikuti skrip curl dari dokumentasi.
Saya di 0.14.3 pada saat pengujian ini (Jan 2026). Versi lebih baru kadang mengubah backend default atau perilaku kuantisasi, jadi saya tetap dengan versi yang stabil untuk saya sampai saya memiliki alasan untuk bergerak.
Tarik & Jalankan GLM-4.7-Flash
Dua jalur bekerja untuk saya:
-
Jika perpustakaan Ollama Anda menyertakan build GLM-4.7-Flash resmi:
- ollama pull glm-4.7-flash
- ollama run glm-4.7-flash
-
Jika tidak muncul (ini terjadi pada satu mesin):
- Buat Modelfile yang menunjuk ke artefak GGUF yang dikenal atau kompatibel untuk GLM-4.7-Flash.
- Contoh Modelfile (disederhanakan):
- FROM ./glm-4.7-flash-q4.gguf
- Tambahkan template prompt hanya jika Anda tahu Anda membutuhkannya: saya membiarkannya minimal.
- Kemudian: ollama create glm-4.7-flash-local -f Modelfile
- Jalankan: ollama run glm-4.7-flash-local
Catatan dari penggunaan:
- Beban pertama lebih lambat saat cache warming.
- Saya menjaga num_ctx konservatif (4K atau 8K) kecuali saya merangkum draf buku. Konteks yang lebih besar terasa bagus, tetapi mereka lapar memori dan tidak selalu membantu kualitas untuk draf sehari-hari.
- Jika generasi terasa ragu-ragu, coba turunkan suhu menjadi 0.6–0.7 dan naikkan top_p sedikit: itu mengencangkan output untuk saya tanpa kehilangan kecepatan.
Referensi: dokumentasi Ollama solid untuk flag spesifik platform dan backend saat ini.

Performa Mac
Benchmark M4 / M3 / M2
Ini bukan lab-grade, hanya run stabil pada prompt menulis dan kode ringan, suhu 0.7, konteks 4K, kuant 4-bit:
- M4 (mesin pinjaman, 48 GB): 60–85 tok/s setelah hangat. Token pertama dalam ~350–500 ms.
- M3 Pro (36 GB): 35–55 tok/s. Token pertama dalam ~500–800 ms.
- M2 (24 GB): 20–30 tok/s. Token pertama dalam ~900–1200 ms.
Ambil kisaran sebagai vibe check. Saya mendorong beberapa konteks 8K di M3 Pro: kecepatan turun ~20–30% tetapi tetap dapat digunakan untuk draf. Di M2, konteks panjang melampaui garis “terasa lengket” saya. Saya menjaganya di 2–4K di sana.
Optimisasi Memori
Apa yang paling membantu di macOS:
- Jaga lebih sedikit tab terminal yang menjalankan model. Jelas, ya, tetapi saya lupa.
- Ukuran konteks dengan benar. 4K adalah sweet spot untuk saya.
- Gunakan kuant 4-bit saat Anda bisa. 5-bit terasa serupa dalam kualitas untuk saya, tetapi lebih lambat.
- Tutup aplikasi yang merebut waktu GPU (editor video, beberapa tab browser dengan WebGL).
Saya juga perhatikan bahwa menggunakan prompt sistem yang stabil mengurangi pekerjaan ulang. Tidak lebih cepat di atas kertas, tetapi lebih sedikit percobaan ulang berarti “kecepatan yang dirasakan” lebih baik. Prompt kecil seperti: “Ringkas, gunakan bahasa polos, tanpa nada pemasaran.” Itu sesuai dengan kekuatan model.
Windows + NVIDIA
Konfigurasi RTX 3090 / 4090
Di 4090 (24 GB), GLM-4.7-Flash terasa konsisten cepat:
- Kuant 4-bit, konteks 4–8K: 120–220 tok/s setelah warmup.
- Token pertama: ~250–400 ms.
- Prompt paralel: 2–3 aliran sebelum saya melihat stutter.
Seorang teman menjalankannya di 3090 (24 GB) dan melihat ~15–25% throughput lebih rendah dengan pengaturan serupa. Jika Anda mendorong konteks di luar 8K atau menjaga banyak respons secara bersamaan, Anda akan menabrak headroom VRAM. Saya biasanya mundur ke 4–6K dan menjaga batch kecil.
Pengaturan CUDA
Apa yang penting dalam praktik:
- Driver NVIDIA terbaru (clean install membantu satu mesin yang stuttered).
- CUDA 12.x dan runtime yang cocok jika Anda melangkah keluar dari Ollama (vLLM/SGLang). Untuk Ollama sendiri, Anda tidak selalu membutuhkan Toolkit penuh, tetapi driver terkini adalah keharusan.
- Pengaturan daya: atur GPU Anda ke “Prefer maximum performance.” Terdengar seperti nasihat gamer, tetapi itu menghentikan clock-throttling selama run panjang.
Jika Anda menabrak error beban atau fallback keras ke CPU, saya akan double-check:
- Keselarasan versi driver dengan runtime CUDA.
- Apakah antivirus memindai direktori model Anda (itu terjadi: itu konyol: itu lambat).
Referensi: tabel kompatibilitas driver–CUDA NVIDIA bernilai quick check sebelum Anda tenggelam berjam-jam ke debugging.
vLLM / SGLang
Saya mencoba GLM-4.7-Flash dengan vLLM dan SGLang ketika saya ingin kontrol lebih atas batching dan endpoint gaya server.
vLLM
- Pasang: Python terbaru, PyTorch kompatibel-CUDA, kemudian pip install vllm.
- Jalankan:
python -m vllm.entrypoints.openai.api_server --model <your_glm_flash_id> --dtype auto --max-model-len 4096 - Mengapa saya menggunakannya: API kompatibel OpenAI stabil, throughput solid untuk alur kerja multi-user atau multi-tab.
SGLang
- Pasang: pip install sglang
- Jalankan:
python -m sglang.launch_server --model <your_glm_flash_id> --context-length 4096 - Mengapa saya menggunakannya: streaming latensi-rendah terasa snappy, dan itu bekerja bagus dengan tugas routing kecil.
Keduanya menginginkan path model yang tepat atau HF repo ID. Jika GLM-4.7-Flash tidak ada di indeks default Anda, Anda perlu menunjuk mereka ke GGUF lokal atau format bobot yang kompatibel. Juga: cocokkan CUDA dan versi driver, atau Anda akan mengejar kernel errors yang buram. Saya menjaga dtype pada auto dan hanya memaksa fp16 ketika saya tahu saya memiliki VRAM untuk cadangan.
Untuk sesi penulisan single-user saya, Ollama tetap lebih sederhana. vLLM/SGLang masuk akal ketika saya menguji tools yang membutuhkan endpoint gaya OpenAI.
Troubleshooting
Kegagalan Beban Model
Apa yang saya lihat:
- “out of memory” selama beban. Perbaiki: beralih ke kuant lebih kecil (misalnya, 4-bit), turunkan num_ctx, atau tutup aplikasi berat GPU.
- “no compatible backend” di Windows. Perbaiki: perbarui driver GPU: pastikan Anda tidak menginstal PyTorch CPU-only jika Anda menggunakan vLLM/SGLang: boot ulang setelah upgrade driver.
- Model tidak ditemukan di Ollama. Perbaiki: buat Modelfile dan ollama create: atau tarik dari tag repo yang tepat jika ada.
Jika model secara diam-diam jatuh kembali ke CPU, tandanya adalah kebisingan kipas (atau tidak adanya) ditambah token yang jauh lebih lambat/detik. Saya telah belajar untuk memeriksa pemanfaatan perangkat sebelum mengasumsikan model menjadi “lebih buruk.”
Perbaikan Inferensi Lambat
Perubahan kecil yang penting lebih dari yang saya harapkan:
- Ukuran konteks dengan benar. Mengurangi setengah konteks sering mempercepat lebih dari berkutat dengan sampling.
- Panaskan cache. Run pendek cepat meningkatkan yang berikutnya.
- Kurangi aliran paralel. Konkurensi terlihat efisien sampai KV cache mengacau Anda.
- Untuk NVIDIA: atur mode daya High Performance, tutup aplikasi overlay, dan hentikan encoder latar belakang.
- Di macOS: jaga charger tetap masuk: beberapa laptop menurun saat di baterai.
Satu lagi: saya berhenti mengejar token/detik maksimal. Metrik yang lebih baik untuk saya adalah “pemikiran pertama yang dapat digunakan.” GLM-4.7-Flash memberi saya itu dengan cepat ketika saya menjaga prompt fokus dan konteks masuk akal.
 Jika Anda menyukai kecepatan GLM-4.7-Flash tetapi tidak senang mengasuh driver, versi CUDA, atau quirk backend, coba WaveSpeed - platform kami sendiri berfokus pada inferensi stabil dan cepat tanpa tuning level-rendah. Anda mendapatkan latensi yang dapat diprediksi tanpa khawatir tentang file model, format quant, atau kompatibilitas GPU.
Jika Anda menyukai kecepatan GLM-4.7-Flash tetapi tidak senang mengasuh driver, versi CUDA, atau quirk backend, coba WaveSpeed - platform kami sendiri berfokus pada inferensi stabil dan cepat tanpa tuning level-rendah. Anda mendapatkan latensi yang dapat diprediksi tanpa khawatir tentang file model, format quant, atau kompatibilitas GPU.
Artikel Terkait

Seedance 2.0 Segera Hadir: Model Video Generasi Berikutnya ByteDance dengan Audio Asli

Panduan Lengkap Seedance 2.0: Pembuatan Video Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Perbandingan Generasi Video AI Terlengkap

Panduan Lengkap Seedream 5.0-Preview: Generasi Gambar Cerdas

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Perbandingan Lengkap
