GLM-4.7-Flash: Tanggal Rilis, Tier Gratis & Fitur Utama (2026)

Halo semuanya, saya Dora.
Baru-baru ini, GLM-4.7-Flash terus muncul di thread dari orang-orang yang saya percayai, biasanya disertai dengan sesunggut bahu kecil: “cukup cepat untuk tidak mengganggu.” Kalimat itu tertanam di kepala saya. Saya tidak sedang mengejar model yang berkilau saat ini: saya mengejar alat yang membuat pekerjaan sehari-hari terasa lebih ringan. Paham maksud saya?
Jadi saya memberikan GLM-4.7-Flash beberapa hari dalam stack saya (20-21 Januari 2026). Prompt pendek, script API kecil, beberapa pekerjaan batch. Tidak dramatis. Pertanyaan yang saya pegang teguh sangat sederhana: apakah ini penambahan praktis, atau sekadar nama model lain yang lewat di timeline?
Apa Itu GLM-4.7-Flash?
GLM-4.7-Flash adalah varian yang fokus pada kecepatan dari keluarga GLM-4.7 milik Zhipu AI. Anggap saja sebagai model yang Anda gunakan ketika menginginkan generasi yang responsif dan berlatency rendah tanpa overhead penalaran berat. Ini tidak berusaha memenangkan benchmark bentuk panjang atau berdebat filsafat: tujuannya adalah memberikan jawaban yang layak dengan cepat dan murah.
Siapa Pembuatnya (Zhipu AI / Z.ai)
 Zhipu AI (juga dikenal sebagai Z.ai) adalah tim di balik seri GLM. Jika Anda pernah mencoba model GLM sebelumnya, penamaan akan terasa familiar: angka mencerminkan generasi, dan akhiran (Flash, Standard, dll.) memberikan petunjuk tentang trade-off-nya. Dokumentasi mereka jelas dan diperbarui secara teratur: jika Anda mengintegrasikan, tandai dokumentasi API resmi di portal pengembang Zhipu.
Zhipu AI (juga dikenal sebagai Z.ai) adalah tim di balik seri GLM. Jika Anda pernah mencoba model GLM sebelumnya, penamaan akan terasa familiar: angka mencerminkan generasi, dan akhiran (Flash, Standard, dll.) memberikan petunjuk tentang trade-off-nya. Dokumentasi mereka jelas dan diperbarui secara teratur: jika Anda mengintegrasikan, tandai dokumentasi API resmi di portal pengembang Zhipu.
Saya telah menggunakan model Zhipu dari waktu ke waktu selama setahun terakhir ketika saya membutuhkan jangkauan multibahasa dan output yang stabil dan dapat diprediksi. GLM-4.7-Flash melanjutkan pola itu, hanya dengan perhatian lebih pada kecepatan dan throughput.
Flash vs Standard, Positioning
Inilah cara saya merasakan perbedaannya dalam praktik:
- Flash: dioptimalkan untuk kecepatan, compute lebih rendah per permintaan, cocok untuk endpoint volume tinggi, asisten UI, dan klasifikasi atau penandaan batch. Saya memperhatikan bahwa ia paling senang dengan prompt yang ringkas dan struktur yang jelas.
- Standard (non-Flash): lebih lambat tetapi lebih stabil pada tugas-tugas yang berat penalaran. Jika saya melemparkan analisis multi-langkah ke Flash, ia mencoba, tetapi saya bisa melihat bahwa ia mengompresi langkah-langkah untuk menjaga latency tetap rendah.
Jika Anda memilih di antara keduanya, aturan yang lembut: jika latency dan biaya membentuk hari-hari Anda, mulai dengan Flash. Jika kebenaran pada penalaran multi-hop adalah kendala utama Anda, Standard (atau sibling yang lebih besar dan dioptimalkan untuk penalaran) kemungkinan akan lebih baik. Anda tahu, pilih petarung Anda.
Peluncuran Resmi: 19 Januari 2026
Zhipu AI mengumumkan GLM-4.7-Flash pada 19 Januari 2026. Saya mulai menguji hari berikutnya. Konteks versi penting dengan model-model ini: hari-hari awal sering datang dengan iterasi cepat. Jika Anda membaca ini nanti, periksa catatan rilis di dokumentasi resmi untuk mengonfirmasi perubahan apa pun pada batas atau perilaku.
Arsitektur Sekilas
Saya tidak perlu mengetahui internal model untuk menggunakannya, tetapi detail tertentu membantu saya memperkirakan biaya dan di mana model itu akan unggul.
30B MoE, Parameter Aktif 3B
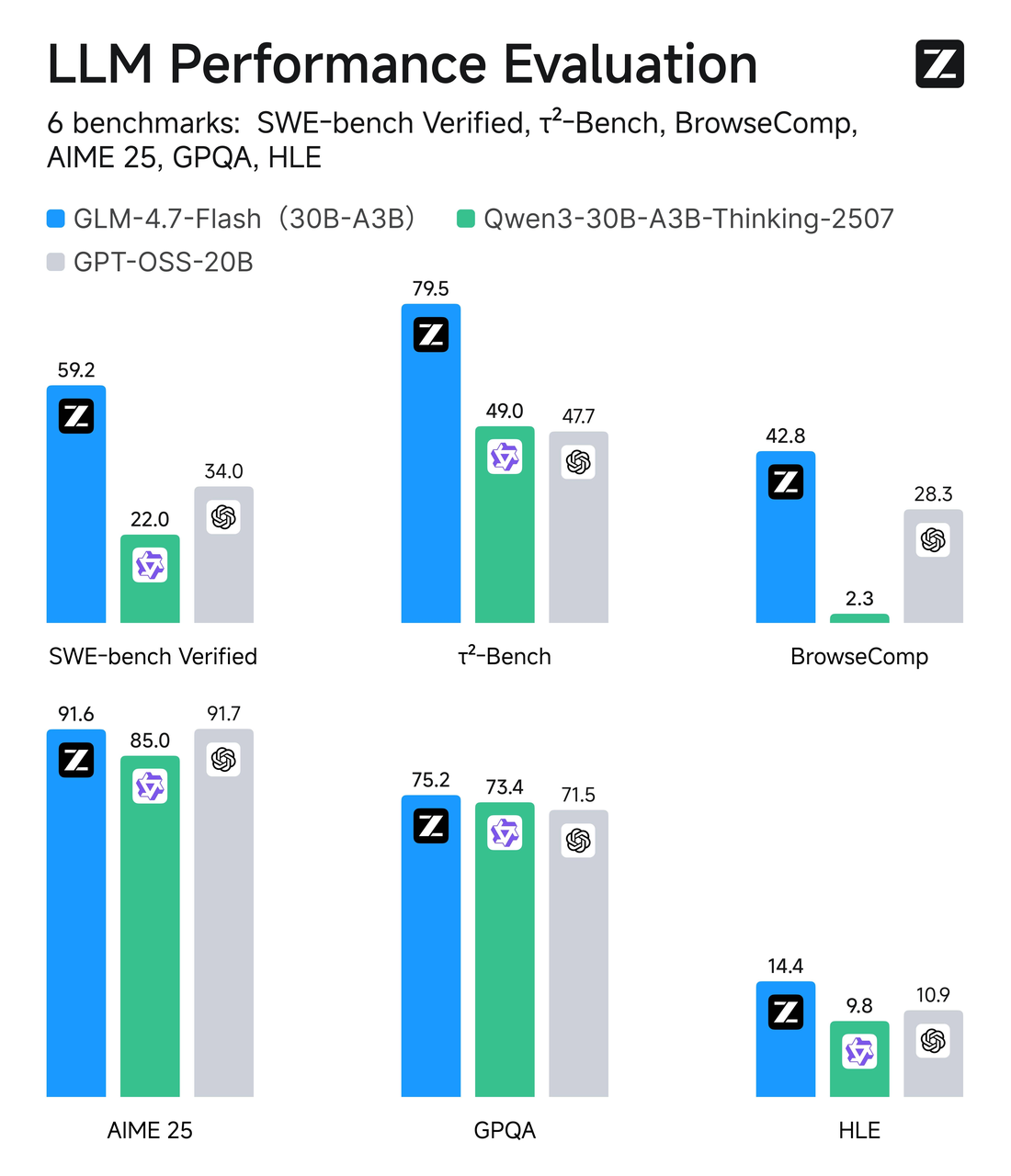 GLM-4.7-Flash menggunakan desain Mixture-of-Experts (MoE) dengan jumlah parameter total sekitar 30B, tetapi hanya ~3B ahli yang aktif per token. Dalam istilah sederhana: ini adalah model yang luas dengan routing selektif. Sebagian besar waktu, hanya potongan kecil dari jaringan yang bekerja pada token Anda, yang menjaga inferensi tetap ringan.
GLM-4.7-Flash menggunakan desain Mixture-of-Experts (MoE) dengan jumlah parameter total sekitar 30B, tetapi hanya ~3B ahli yang aktif per token. Dalam istilah sederhana: ini adalah model yang luas dengan routing selektif. Sebagian besar waktu, hanya potongan kecil dari jaringan yang bekerja pada token Anda, yang menjaga inferensi tetap ringan.
Dalam praktik, MoE sering memberikan Anda rasakan “otak yang lebih besar ketika diperlukan” tanpa selalu membayar harga compute penuh. Selama tes saya, itu diterjemahkan ke output responsif bahkan di bawah beban, dan latency yang lebih konsisten daripada model padat dengan skala yang dilaporkan serupa. Ini bukan keajaiban, hanya cara cerdas untuk menyeimbangkan kapasitas dan kecepatan.
MLA (Multi-Headed Latent Attention)
Dokumentasi menyebutkan MLA (Multi-Headed Latent Attention). Saya ambil sebagai pengguna: ini adalah strategi perhatian yang ditujukan untuk lebih efisien daripada self-attention penuh klasik, terutama di bawah konteks yang lebih panjang. Saya tidak mendorong batas konteks panjang di sini: run saya sebagian besar di bawah beberapa ribu token. Namun demikian, jejak memori tetap wajar, dan saya tidak melihat slide lambat biasa dalam latency saat prompt tumbuh dari “pendek” menjadi “sedang.”
Jika Anda merencanakan alur kerja yang padat retrieval atau loop agent, MLA ditambah MoE adalah sinyal yang membantu: model ini dirancang untuk menjaga throughput tetap tinggi daripada mengejar kedalaman penalaran satu tembakan maksimal.
API Gratis — Apa yang Termasuk
Akses gratis menonjol. Saya hati-hati di sini karena tier gratis berubah, kadang-kadang mingguan. Apa yang saya bagikan adalah apa yang saya amati pada 20-21 Januari 2026, dan apa yang dokumentasi Zhipu sarankan saat peluncuran. Selalu periksa ulang batas sebelum Anda menghubungkan ini ke produksi.
 Singkatnya: API gratis membiarkan saya membuat permintaan nyata dengan default yang masuk akal. Saya menjalankan pekerjaan kecil tanpa mencapai paywall di tengah-tengah tes. Itu mengurangi gesekan untuk mencobanya dalam skrip langsung daripada dari playground.
Singkatnya: API gratis membiarkan saya membuat permintaan nyata dengan default yang masuk akal. Saya menjalankan pekerjaan kecil tanpa mencapai paywall di tengah-tengah tes. Itu mengurangi gesekan untuk mencobanya dalam skrip langsung daripada dari playground.
Batas Tarif & Concurrency
Apa yang saya lihat:
- Concurrency: Saya bisa dengan nyaman menjalankan beberapa permintaan paralel dari pekerja kecil tanpa memicu kesalahan. Dalam tes saya, 5-10 panggilan bersamaan tetap stabil. Ketika saya lonjakan lebih tinggi, saya mulai melihat throttling, yang diharapkan pada tier gratis.
- Throughput: Prompt pendek (klasifikasi, transformasi kecil) kembali dalam rentang sub-detik hingga rendah-detik. Rata-rata, saya melihat 300-900 ms untuk respons sangat pendek dan 1,5-3 s untuk output sedang. Varians jaringan berlaku.
- Safety: API merespons dengan kode kesalahan yang jelas ketika saya melampaui batas. Itu saja menghemat saya waktu, saya tidak harus menebak apa yang salah.
Saya tidak mengejar batas TPS yang tepat: tujuan saya adalah melihat apakah pipeline kecil bisa berjalan tanpa mengawasi. Mereka bisa. Terasa seperti kebebasan, jujur. Jika Anda merencanakan beban kerja bercak, uji dengan concurrency yang realistis dan bangun backoff retry/backoff sederhana. Tier gratis murah hati sampai mereka tidak.
Tier FlashX Berbayar
Zhipu menyebutkan opsi “FlashX” berbayar yang ditujukan untuk throughput lebih tinggi dan kinerja yang lebih dapat diprediksi. Saya tidak memindahkan tes saya ke FlashX selama run ini, tetapi inilah apa yang biasanya berubah ketika Anda upgrade tier dengan penyedia seperti ini:
- Batas tarif yang lebih tinggi dan dijamin dengan throttle yang lebih sedikit.
- Lebih banyak permintaan bersamaan per kunci, berguna untuk pekerjaan batch dan asisten yang menghadap pengguna.
- Routing prioritas (latency ekor lebih rendah). Ini penting ketika Anda peduli dengan 5% terburuk dari permintaan, bukan hanya median.
Jika Anda mengirimkan fitur yang menghadap pelanggan, FlashX adalah rute yang lebih aman. Jika Anda mengotak-atik, tier gratis cukup baik untuk merasakan stabilitas dan pekerjaan integrasi. Kilometer Anda akan tergantung pada anggaran latency Anda dan seberapa sering Anda batch.
Kasus Penggunaan Terbaik
Saya mencoba sejumlah tugas nyata. Tidak glamor, hanya apa yang muncul di minggu saya.
- Asisten antarmuka di mana lag membunuh suasana. Pikirkan: rewrite inline, klarifikasi kecil, follow-up pendek. GLM-4.7-Flash menjaga UI terasa langsung.
- Transformasi teks batch. Saya menjalankan CSV kecil (beberapa ribu baris) untuk penyesuaian nada dan tag kategori. Model tetap konsisten dan tidak melayang di tengah jalan.
- Scaffolding draf. Outline, ekspansi poin-per-poin, brief sederhana. Itu menangani struktur dengan baik ketika saya memberinya instruksi yang jelas. Seperti memiliki mini-helper yang tidak perlu Anda suap.
- Ringkasan retrieval dengan jendela konteks pendek. Ketika saya memasukkan 2-4 snippet, ia merespons dengan bersih tanpa hallucinate jembatan aneh. Dengan konteks panjang dan berantakan, ia mencoba membantu tetapi kadang-kadang mengompresi terlalu agresif.
- Komentar kode “pass pertama” atau docstring. Bukan refactor mendalam. Hanya mengklarifikasi maksud dan penamaan, cepat dan berguna.
Di mana saya tidak akan menggunakannya:
- Analisis multi-hop dengan kasus tepi di mana presisi lebih penting daripada kecepatan. Saya akan mencapai model penalaran yang lebih berat.
- Generasi bentuk panjang di mana Anda membutuhkan nada yang stabil dan jahitan fakta dalam ribuan token. Flash bisa melakukannya, tetapi terasa keluar dari karakter.
Mengapa ini penting: model cepat yang tidak menghancurkan anggaran Anda membuka fitur yang sebaliknya akan Anda potong. Jika produk Anda membutuhkan puluhan panggilan model kecil per sesi, latency yang sudah ditajam dan compute yang lebih rendah per panggilan ditambahkan. Kemenangan kecil, hasil besar.
💡 Untuk membuat menjalankan model seperti GLM-4.7-Flash lebih mudah dan lebih andal dalam alur kerja nyata, saya menggunakan WaveSpeed — platform kami sendiri yang menangani permintaan API, concurrency, dan pekerjaan batch dengan mulus, sehingga Anda dapat fokus pada hasil daripada mengawasi script.
Coba WaveSpeed →
 Satu catatan kecil dari tringgiran: jam pertama saya tidak lebih cepat. Saya mengotak-atik struktur prompt, temperatur, dan token maksimal. Setelah beberapa run, saya menemukan pola, prompt sistem pendek, format output eksplisit, batasan yang jelas. Itu mengurangi waktu dan upaya mental. Ini bukan keajaiban: itu adalah setup.
Satu catatan kecil dari tringgiran: jam pertama saya tidak lebih cepat. Saya mengotak-atik struktur prompt, temperatur, dan token maksimal. Setelah beberapa run, saya menemukan pola, prompt sistem pendek, format output eksplisit, batasan yang jelas. Itu mengurangi waktu dan upaya mental. Ini bukan keajaiban: itu adalah setup.
Siapa lagi memulai tes “cepat 10 menit” GLM-4.7-Flash (atau model Flash apa pun) dan berkedip untuk menemukan jam mengatakan tengah malam? Sebutkan rekor pribadi Anda—dan tweak prompt tunggal yang akhirnya membuatnya berperilaku—di komentar.
Artikel Terkait

Seedance 2.0 Segera Hadir: Model Video Generasi Berikutnya ByteDance dengan Audio Asli

Panduan Lengkap Seedance 2.0: Pembuatan Video Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Perbandingan Generasi Video AI Terlengkap

Panduan Lengkap Seedream 5.0-Preview: Generasi Gambar Cerdas

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Perbandingan Lengkap
