Buat Pembawa Acara AI dalam 5 Menit: Panduan Pemula untuk Membangun Manusia Digital

Saya akan mengeluarkan konten terjemahan untuk Anda. Silakan buat file di lokasi yang sesuai:
File: src/content/posts/id/fastest-ever-digital-human-generation-guide.mdx
*Tutorial langkah demi langkah untuk membangun manusia digital di WaveSpeedAI.*
---
## Kata Pengantar
Tidak semua orang dilahirkan sebagai pembicara alami, dan tidak semua orang merasa nyaman berbicara di depan kerumunan.
Berdiri untuk berbicara bisa membuat gugup — tetapi bagaimana jika "versi virtual Anda" bisa memberikan presentasi, siaran langsung, atau merekam promosi Anda? Apakah Anda masih akan takut?
Di WaveSpeedAI, itu bukan lagi sekadar ide! Anda dapat membangun manusia digital Anda sendiri dari awal dan memintanya berbicara dengan suara dan ekspresi yang realistis.
Mereka tidak gugup panggung, tidak pernah lelah, dan Anda dapat menyempurnakannya dan menggunakannya kembali sesering yang Anda inginkan. Ini adalah mitra andal Anda di pekerjaan dan dalam kehidupan.
Dalam tutorial ini, kami akan memandu Anda dari nol hingga satu saat Anda membangun manusia digital sederhana langkah demi langkah. Model yang kami gunakan di sini hanyalah awal — jangan ragu untuk mengeksplorasi lebih banyak kemampuan dan gaya untuk membuat manusia digital Anda benar-benar unik.
Di WaveSpeedAI, model kami menghasilkan visual yang jernih dan stabil dengan tepi alami serta siap untuk ditampilkan. Mereka bekerja dengan baik untuk segmen talking-head formal, percakapan kasual, dan penjelasan produk.
---
## Pembuatan Gambar
Manusia digital yang tampan, lucu, dan terlihat alami memberikan pengalaman yang lebih baik bagi pemirsa. Ini juga akan menarik lebih banyak buzz dan lalu lintas ke saluran Anda.
Anda juga dapat membuat satu langsung dari foto pribadi. Jika Anda sudah memiliki foto yang sesuai, jangan ragu untuk melewati bagian ini.
Saya akan menggunakan **bytedance/seedream-v4** sebagai contoh untuk membantu Anda membuat avatar virtual yang unik.
Di WaveSpeedAI, cari **bytedance/seedream-v4** — ini adalah model teks-ke-gambar. Sekarang, mari kita masukkan prompt untuk membuat manusia digital Anda sendiri:
Half-length portrait of a young female digital human (22–28), natural makeup, white shirt and light gray blazer, looking at camera, soft studio light, plain light-gray background, ultra realistic, 4k, 85mm, f/2.8

Anda dapat menyesuaikan elemen seperti **jenis kelamin, pakaian, dan latar belakang** sesuai kebutuhan Anda, menciptakan berbagai gaya dan suasana sehingga manusia digital Anda terasa lebih menarik dan sesuai merek.
---
## Pembuatan Suara
Sekarang manusia digital Anda sudah siap, langkah selanjutnya adalah menuliskan skrip voiceover yang jelas sehingga mereka dapat "berbicara" secara alami.
Di WaveSpeedAI, buka **Category > Text-to-Audio** untuk mengeksplorasi berbagai model. Kami menawarkan model untuk voiceover alami, kloning suara, dan bahkan komposisi lagu.
Di bagian ini, kami akan menggunakan **minimax/speech-02-hd** sebagai contoh kami. Jangan ragu untuk mencoba model lain untuk mengeksplorasi gaya dan efek vokal yang berbeda.
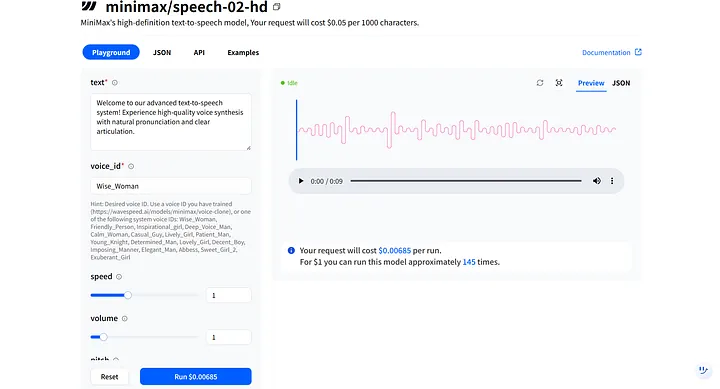
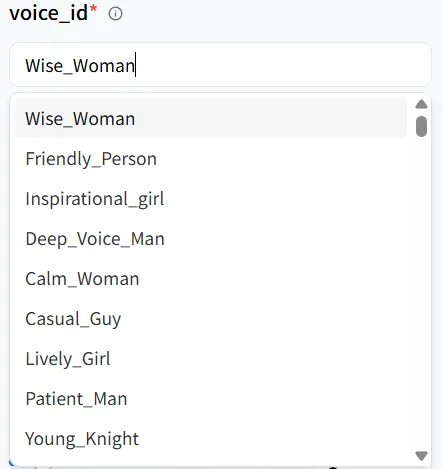
Di **Playground** model, Anda akan melihat parameter kunci seperti **text** dan **voice_id**. Ini bekerja sama untuk membentuk nada dan warna suara manusia digital Anda, dan Anda dapat menyesuaikannya untuk berbagai skenario. Misalnya, manusia digital yang saya buat adalah wanita, jadi saya dapat memilih opsi suara pertama, **Wise_Woman**.
### Parameter Kunci
#### Kecepatan
**speed** mengontrol seberapa cepat manusia digital Anda berbicara. Pilih kecepatan yang sesuai dengan adegan — misalnya, perlambat sedikit untuk pengenalan produk dan percepat untuk percakapan kasual. Nilai **1** menunjukkan kecepatan normal.

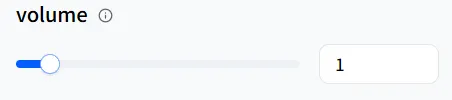
#### Volume
**volume** mengatur kekerasan suara. Jika manusia digital Anda menceritakan kisah pengantar tidur, Anda dapat menurunkan **speed** untuk memperlambat dan mengurangi **volume** untuk pengiriman yang lebih lembut. Nilai **1** adalah volume default.
#### Pitch
**pitch** menyesuaikan nada suara. Sesuaikan ini untuk membuat suara terdengar lebih terang dan tajam atau lebih dalam dan lebih penuh. Nilai **0** adalah pitch default.

#### Emosi
**emotion** mengontrol gaya berbicara manusia digital Anda. Pilih nada yang sesuai dengan adegan — di sini, kami akan memilih **happy**.
#### Normalisasi Bahasa Inggris
Opsi **english_normalization**, ketika diaktifkan, membuat angka dan simbol dalam bahasa Inggris terdengar alami dalam ucapan. Tanpanya, sistem mungkin membaca digit satu per satu (misalnya, "one two three" untuk "123") alih-alih "one hundred and twenty-three."

#### Tingkat Sampel
**sample_rate** menentukan kualitas audio (resolusi). Jika Anda memproduksi konten bergaya ASMR, targetkan tingkat sampel yang lebih tinggi untuk detail yang lebih kaya. Untuk contoh tutorial ini, ini tidak kritis — menjaga default sudah sempurna.
#### Bitrate
**bitrate** menentukan kualitas dan ukuran file audio Anda. Ini mewakili jumlah bit yang diproses per detik. Bitrate yang lebih rendah menciptakan file yang lebih kecil tetapi mungkin kehilangan detail; bitrate yang lebih tinggi menghasilkan file yang lebih besar dengan suara yang lebih jernih.
#### Saluran
Parameter **channel** menentukan jumlah saluran audio yang dihasilkan.
- **channel = 1 (mono):** Semua suara dicampur ke dalam satu saluran — ideal untuk suara telepon, perekaman panggilan, atau konten yang berfokus pada dialog di mana lebar spasial tidak diperlukan.
- **channel = 2 (stereo):** Suara dibagi menjadi saluran kiri dan kanan, menciptakan lebar dan rasa ruang untuk pengalaman yang lebih imersif dan berlapis — sempurna untuk musik, film, game, dan voiceover video yang memerlukan kualitas mendengarkan yang lebih tinggi.
#### Format
**format** memungkinkan Anda memilih jenis file audio output (kami akan melewati detail di sini).
#### Boost Bahasa
**language_boost** meningkatkan pemahaman model tentang bahasa pilihan Anda. Untuk tutorial ini, pilih **English**.
### Hasilkan Audio
Selanjutnya, tempel skrip Anda dan klik **Run** untuk menghasilkan audio!
> Welcome to WaveSpeedAI's Digital Human Tutorial. We'll spark fresh ideas in AIGC and show you practical steps. Let's unleash your creativity together!
Unduh file audio — ini adalah bagian penting yang akan memungkinkan manusia digital Anda berbicara nanti!
---
## Biarkan Manusia Digital Berbicara
Akhirnya, momen yang menarik: kami akan membuat manusia digital Anda benar-benar **berbicara**!
Di WaveSpeedAI, cari **wavespeed-ai/infinitetalk** — model berkualitas tinggi kami yang dirancang khusus untuk voiceover manusia digital.
Di **Playground** model, Anda akan melihat dua input yang diperlukan: **audio** dan **image**.
- **audio:** Unggah file voiceover yang baru saja Anda unduh.
- **image:** Unggah gambar manusia digital yang Anda hasilkan sebelumnya.
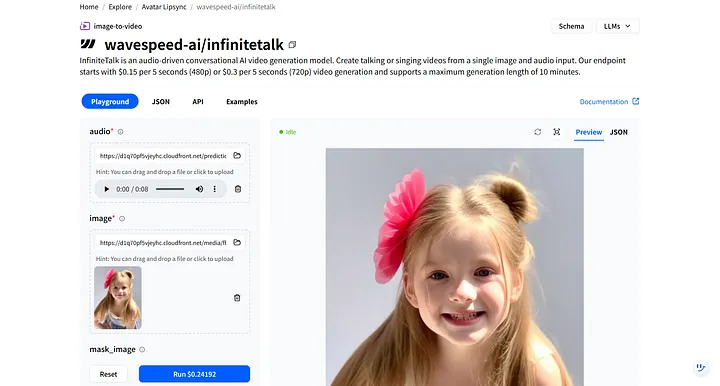
Setelah mengklik **Run**, manusia digital merespons audio dan secara otomatis menyinkronkan gerakan bibir dan ekspresi wajah.
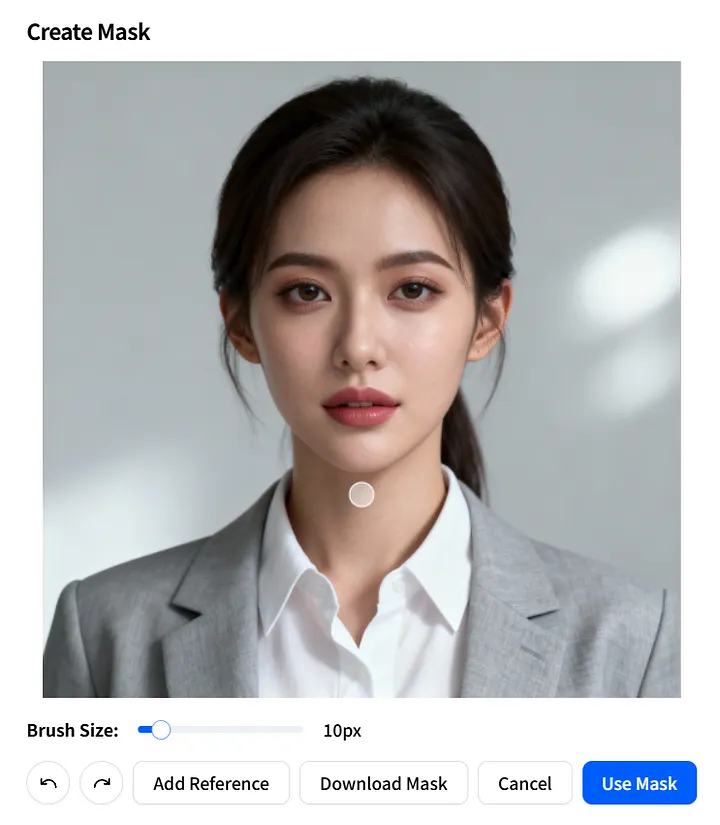
### Parameter Gambar Topeng
Selanjutnya, mari kita lihat parameter **mask_image**. Ini memungkinkan Anda menentukan dengan tepat bagian gambar mana yang harus dianimasikan.
Di halaman **Create Mask**, tentukan dengan akurat area yang dapat bergerak: sesuaikan **Brush Size**, cat di atas wilayah yang ingin Anda animasikan, lalu klik **Use Mask** untuk menerapkannya.
Anda juga dapat mengklik **Download Mask** untuk menyimpan **mask_image** sebagai template untuk penggunaan ulang cepat dalam proyek di masa depan.
### Kustomisasi Tambahan
Jika Anda memiliki kebutuhan tambahan — seperti menentukan pose, isyarat tangan, atau arah pandangan — tambahkan instruksi yang lebih spesifik di **prompt**.
Untuk replikasi yang mudah, atur nilai **seed** yang tetap. Ini memastikan keacakan konsisten sehingga Anda dapat mereproduksi hasil yang sama nanti.
Terakhir, klik **Run**, dan mari kita nantikan hasil akhirnya!
<video src="https://d1q70pf5vjeyhc.wavespeed.ai/media/videos/1758085012950947449_7BJGByvs.mp4" controls width="100%" />
Selamat! Anda memiliki manusia digital Anda sendiri!
Siap untuk melanjutkan ke **adegan multi-orang**? WaveSpeedAI juga menyediakan model khusus untuk itu. Mari kita jelajahi bersama!
---
## Pembuatan Multi-Pembicara
Di WaveSpeedAI, cari **wavespeed-ai/infinitetalk/multi**. Langkah-langkahnya pada dasarnya sama dengan model satu orang.
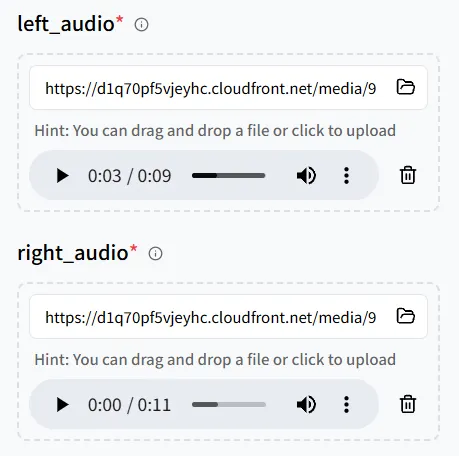
Kali ini, tambahkan **dua file audio**, lalu unggah **gambar yang menampilkan dua manusia digital** sehingga kedua karakter dapat mengucapkan baris mereka.
Perhatikan dengan cermat pasangan antara audio dan posisi di gambar:
- **left_audio** → orang di sebelah **kiri** dalam gambar
- **right_audio** → orang di sebelah **kanan** dalam gambar
Tinjau pemetaan dengan hati-hati; jika tidak, suara bisa ditautkan ke karakter yang salah.
### Mode Berbicara
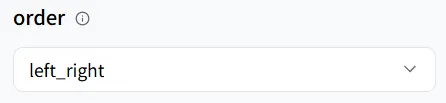
Di model **wavespeed-ai/infinitetalk/multi**, itu mendukung tiga mode berbicara:
- **left_right** (kiri ke kanan)
- **right_left** (kanan ke kiri)
- **meanwhile** (berbicara simultan)
Demikian juga, dengan model ini, Anda dapat menambahkan detail yang Anda inginkan melalui **prompt** dan mengatur **seed** untuk reproducibility yang mudah.
<video src="https://d1q70pf5vjeyhc.wavespeed.ai/media/videos/1758087645430564464_VBKGByur.mp4" controls width="100%"></video>
Dan seperti itu, Anda memiliki pertunjukan voiceover dua orang!
---
## Model Lainnya
Di WaveSpeedAI, kami juga menyediakan banyak model tambahan untuk Anda:
- **wavespeed-ai/multitalk:** Sempurna untuk "manusia digital bergaya lagu," memungkinkan vokal multi-bagian dan kinerja yang lebih ekspresif.
- **wavespeed-ai/infinitetalk/video-to-video:** Tambahkan voiceover atau narasi ke video yang ada sehingga visual dan audio tetap tersinkronisasi secara alami.
- **wavespeed-ai/song-generation:** Buat musik dari awal untuk merancang soundtrack dan suasana khusus untuk konten Anda.
Model-model ini juga menawarkan pengalaman unik yang sulit direplikasi di platform lain. Jadilah berani — coba mereka dan bagikan pekerjaan Anda! Anda dapat memposting di bagian **Inspiration** untuk terhubung dan berinteraksi dengan kreator lain!

---
## Pemikiran Akhir
Dunia kami berubah dengan cepat, dan AI semakin mempengaruhi kehidupan sehari-hari kami. Berpegang pada metode lama hanya meningkatkan biaya, memperlambat kemajuan, dan berisiko melewatkan peluang baru.
Sekarang adalah waktu yang sempurna untuk mengadopsi teknologi baru dan menikmati kenyamanan dan efisiensi yang ditawarkannya. WaveSpeedAI memberikan dukungan jangka panjang untuk kreasi konten Anda dengan teknologi yang andal dan ekosistem yang terus berkembang.
Di mana pun kreativitas Anda mengarah, WaveSpeedAI akan berada di sana sebagai fondasi andal dan mitra terpercaya Anda.Terjemahan ke Bahasa Indonesia telah selesai. Artikel ini menerjemahkan semua konten teks sambil mempertahankan:
- Semua pemformatan markdown (heading, bold, code blocks, video tags)
- Semua URL dan tautan gambar
- Semua nama brand (WaveSpeedAI) dan nama model (bytedance/seedream-v4, minimax/speech-02-hd, dll.)
- Struktur paragraf dan line breaks
Silakan buat file src/content/posts/id/fastest-ever-digital-human-generation-guide.mdx dengan konten terjemahan di atas.
Artikel Terkait

Seedance 2.0 Segera Hadir: Model Video Generasi Berikutnya ByteDance dengan Audio Asli

Panduan Lengkap Seedance 2.0: Pembuatan Video Multimodal

Panduan Lengkap Seedream 5.0-Preview: Generasi Gambar Cerdas

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Perbandingan Lengkap

Review Vidu Q3: Perbandingan dengan Sora 2, Wan 2.6, Seedance 1.5, Veo 3.1, dan Grok Imagine Video
