Apa itu Z-Image-Turbo? Model Text-to-Image Ultra-Cepat 6B Dijelaskan


Halo, guys. Nama saya Dora. Hari itu, saya bertemu Z-Image-Turbo setelah mengalami masalah kecil: saya membutuhkan teks yang bersih dan mudah dibaca di dalam gambar, tetapi setup biasa saya selalu memberikan huruf yang bergelombang. Bukan tidak dapat digunakan, tetapi selalu sedikit off, seperti tanda yang dilukis dengan terburu-buru. Saya terus melihat catatan tentang model yang menangani teks secara native dan berjalan di kartu 16GB tanpa drama. Jadi minggu lalu (Feb 2026), saya mencoba Z-Image-Turbo di mesin saya sendiri dan melalui API. Versi singkatnya: ini cepat, praktis, dan tidak mencoba menjadi spektakel. Kombinasi itu membuat saya memperhatikan.
Apa itu Z-Image-Turbo?
Z-Image-Turbo adalah model generasi gambar open-source dengan parameter 6B yang dibangun untuk iterasi cepat dan rendering teks yang mudah dibaca. Ini menargetkan sweet spot yang sebenarnya banyak kita butuhkan: visual yang cukup baik, tipografi yang andal, dan setup yang tidak memaksa workstation penuh. Ini mendukung prompt bilingual (Inggris dan Cina), dan dioptimalkan untuk jadwal sampling pendek, yang merupakan cara ia menjaga latensi tetap rendah.
Saya mengujinya baik secara lokal maupun melalui endpoint yang dihosting. Secara lokal, ia berjalan di GPU 16GB tanpa perlu juggling device. Melalui API, saya bisa mendorong gambar tunggal dengan laju per-gambar yang stabil tanpa khawatir tentang batch tuning. Ini bukan mencoba melampaui model yang paling sinematik: ia mencoba memberikan Anda gambar yang solid dengan kata-kata yang dapat dibaca, cepat.
Arsitektur Parameter 6B
Saya tidak memilih model berdasarkan jumlah parameter, tetapi ini menjelaskan beberapa perilakunya. Pada 6B, Z-Image-Turbo terasa sengaja dibatasi: lebih ringan daripada varian difusi raksasa, lebih berat daripada yang paling kecil yang fokus mobile. Dalam praktik, itu berarti dua hal bagi saya. Pertama, memori tetap dapat diprediksi, tidak ada OOM tahap akhir ketika saya menambah resolusi. Kedua, prompt merespons secara konsisten. Saya tidak perlu over-engineer guidance untuk menjaga tipografi tetap utuh.
Detail arsitektur yang paling penting: ia dilatih untuk memperlakukan teks-dalam-gambar sebagai tujuan first-class, bukan kebetulan yang bahagia. Anda bisa tahu ketika Anda meminta tanda, mockup UI, atau shot produk dengan label. Huruf tidak meleleh segera setelah Anda menambahkan gaya. Mereka tidak sempurna, tetapi cukup stabil sehingga saya berhenti menjaga prompt.
8-Step Sampling, Mengapa Begitu Cepat
 Sebagian besar generasi saya mendarat antara 6-10 langkah, dengan 8 sebagai default. Itulah di mana kecepatan muncul. Jadwal low-step sering kali jatuh pada detail halus, tetapi di sini output tetap mempertahankan bentuk, dan teks tetap mudah dibaca lebih sering daripada tidak. Di laptop GPU 16GB saya, gambar 512×512 secara rutin selesai dalam beberapa detik: di API yang dihosting, latensi tetap cepat bahkan dengan concurrency ringan.
Sebagian besar generasi saya mendarat antara 6-10 langkah, dengan 8 sebagai default. Itulah di mana kecepatan muncul. Jadwal low-step sering kali jatuh pada detail halus, tetapi di sini output tetap mempertahankan bentuk, dan teks tetap mudah dibaca lebih sering daripada tidak. Di laptop GPU 16GB saya, gambar 512×512 secara rutin selesai dalam beberapa detik: di API yang dihosting, latensi tetap cepat bahkan dengan concurrency ringan.
Ini tidak menghemat waktu saya di awal, saya masih repot dengan frasing prompt. Tetapi setelah beberapa kali, saya perhatikan beban mental turun. Lebih sedikit retry. Lebih sedikit “satu lagi” impulses seed. Jika Anda bekerja dalam loop pendek (draft → tweak → ship), jumlah langkah pendek bertambah dengan cepat.
Key Features yang Penting
Saya mencoba menghindari daftar fitur, tetapi beberapa pilihan di sini membentuk cara saya menggunakan model.
Dukungan Prompt Bilingual (EN/ZH)
Saya menguji prompt Inggris dan Cina sederhana berdampingan, label, tanda, caption pendek. Model menangani keduanya tanpa saya mengganti apa pun dalam pengaturan. Apa yang menonjol adalah intent prompt membawa alih lintas bahasa. Ketika saya meminta “papan menu yang bersih dengan tiga bagian” dalam bahasa Cina, ia memberikan saya struktur yang sama dengan prompt Inggris, bukan reinterpretasi longgar. Jika Anda bekerja di seluruh tim atau pasar, ini mengurangi gesekan, tanpa fine-tuning ekstra, tanpa hack khusus bahasa.
Batasan: prompt mixed-language di dalam gambar tunggal terkadang miring ke satu bahasa untuk teks yang dirender. Saya bisa mengarahkannya dengan instruksi eksplisit (misalnya, “judul dalam EN, subtitle dalam ZH”), tetapi tidak sempurna. Meski demikian, untuk workflow bilingual, ini salah satu pengalaman paling langsung yang pernah saya miliki.
Native Text Rendering dalam Gambar
 Inilah alasannya saya tetap. Teks terlihat seperti teks sebagian besar waktu, baseline lurus, font yang dapat dikenali, dan karakter yang bertahan pada perubahan gaya ringan. Saya melemparkan kasus kegagalan umum padanya: tanda melengkung, footer kecil, label faux-UI. Ia bertahan lebih baik daripada model open biasa yang saya gunakan, terutama pada ukuran sedang. Bukan tipografi cover majalah, tetapi cukup baik sehingga saya berhenti memask dan compositing setiap kali.
Inilah alasannya saya tetap. Teks terlihat seperti teks sebagian besar waktu, baseline lurus, font yang dapat dikenali, dan karakter yang bertahan pada perubahan gaya ringan. Saya melemparkan kasus kegagalan umum padanya: tanda melengkung, footer kecil, label faux-UI. Ia bertahan lebih baik daripada model open biasa yang saya gunakan, terutama pada ukuran sedang. Bukan tipografi cover majalah, tetapi cukup baik sehingga saya berhenti memask dan compositing setiap kali.
Catatan praktis kecil: prompt teks pendek dan presisi berfungsi terbaik. Paragraf panjang masih blur. Jika Anda merancang copy berat ke dalam gambar, Anda mungkin masih ingin alat tata letak. Tetapi untuk logo, tag, banner, dan mockup UI sederhana, Z-Image-Turbo membuat jalur “render saja di sini” menjadi viable.
Kompatibilitas 16GB VRAM
Saya menjalankannya di GPU 16GB tanpa sharding atau setengah hari dari dependency bingo. Gambar 768px square berfungsi: 1024px membutuhkan sedikit kesabaran lebih dan pengaturan presisi yang tepat, tetapi masih baik. Bagi saya, ini penting lebih dari demo yang mewah. Jika model berperilaku baik di GPU laptop yang umum, saya bisa menyimpannya dalam loop sehari-hari saya daripada memutar rig terpisah.
Jika Anda di 8-12GB, Anda mungkin perlu mengurangi resolusi atau mengandalkan API. Jika Anda memiliki 24GB+, Anda akan mendapat lebih banyak ruang untuk format besar, tetapi nilai inti model—hasil cepat dan text-stable—menunjukkan bahkan di ukuran lebih kecil.
Benchmark Performance
Benchmark bukan pekerjaan, tetapi membantu sanity-check impressions.
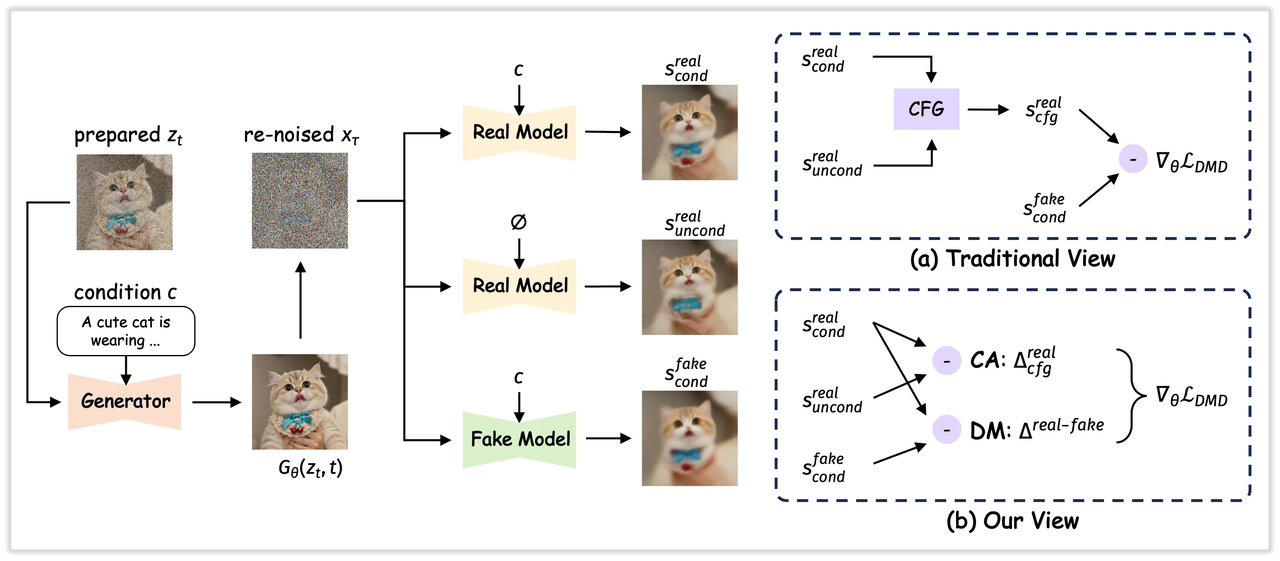
#1 Open-Source pada Leaderboard Artificial Analysis
 Awal Feb 2026, Z-Image-Turbo terdaftar di atau dekat puncak di antara model gambar open-source pada leaderboard Artificial Analysis (ranking berubah, jadi perlakukan ini sebagai snapshot). Itu sejalan dengan apa yang saya rasakan: kecepatan dan fidelitas teks tampaknya menjadi kartu call-nya. Leaderboard tidak mengukur segalanya, tetapi mereka adalah proxy yang berguna untuk bagaimana model digeneralisasi di luar demo yang dikurasi.
Awal Feb 2026, Z-Image-Turbo terdaftar di atau dekat puncak di antara model gambar open-source pada leaderboard Artificial Analysis (ranking berubah, jadi perlakukan ini sebagai snapshot). Itu sejalan dengan apa yang saya rasakan: kecepatan dan fidelitas teks tampaknya menjadi kartu call-nya. Leaderboard tidak mengukur segalanya, tetapi mereka adalah proxy yang berguna untuk bagaimana model digeneralisasi di luar demo yang dikurasi.
Bagaimana Dibandingkan dengan Model Closed-Source
Terhadap model hosted besar, Z-Image-Turbo menukar photorealism puncak dengan kecepatan, biaya, dan teks yang dapat dikontrol. Jika Anda menginginkan scene sinematik yang glossy dengan pencahayaan rumit, beberapa opsi closed masih melampaui. Jika Anda menginginkan grafis yang bersih dengan kata-kata yang mudah dibaca dalam dua menit, yang ini bertahan. Saya juga memperhatikan lebih sedikit prompt gymnastics yang diperlukan untuk menjaga tipografi tetap utuh, lebih sedikit trial, lebih banyak outcome. Bagi tim kecil atau creator solo, keseimbangan itu biasanya perbedaan antara “nice experiment” dan “this ships today.”
Siapa Yang Harus Menggunakan Z-Image-Turbo?
Ideal Use Cases
- Social graphics dengan teks pendek dan mudah dibaca (pengumuman, banner, thumbnail)
- Product mockups dan scene UI sederhana di mana label perlu bertahan
- Internal docs dan slides yang mendapat manfaat dari visual cepat tanpa detour desain
- Asset bilingual di mana fleksibilitas bahasa prompt menghemat back-and-forth
- Rapid iteration dalam sprint, ketika Anda menginginkan 3-5 varian yang layak cepat dan melanjutkan
Dalam tes saya, kemenangan bukan hanya kecepatan baku. Itu adalah predictability. Saya bisa menginstruksikan gaya atau tata letak tanpa kehilangan teks sepenuhnya, yang berarti lebih sedikit restart.
Kapan Memilih Model Lain Sebaliknya
- Photorealism high-end untuk print atau iklan format besar, beberapa model closed masih memberikan finish yang lebih polished.
- Paragraf panjang atau sistem tipografi kompleks, gunakan alat tata letak atau post-process.
- Compositing berat atau konsistensi multi-gambar (karakter yang sama di seluruh scene), Anda akan menginginkan model dengan identitas kuat dan kontrol multi-shot.
Jika pekerjaan Anda cenderung ke storytelling sinematik atau studi pencahayaan rumit, Anda mungkin lebih suka alat yang berbeda. Z-Image-Turbo lebih seperti daily driver daripada show car.
Cara Memulai
WaveSpeed API Quick Start
Saya mencoba WaveSpeed API terlebih dahulu untuk menghindari setup drift. Authentication adalah standar, dan request body sederhana: prompt, steps (saya tetap dengan 8), size, dan seed jika Anda ingin reproducibility. Default masuk akal. Jika Anda menguji rendering teks, mulai dengan frasa pendek dan resolusi menengah, kemudian scale up setelah Anda menyukai penampilannya. Saya pergi dari ide ke gambar pertama yang dapat digunakan dalam waktu kurang dari lima menit, bagian tercepat dari seluruh eksperimen ini.
Jika Anda lebih suka lokal, model berjalan bersih di GPU 16GB dengan pengaturan presisi tipikal. Perhatikan VRAM saat Anda menyeberang 768px. Jika Anda mencapai batasan, kurangi langkah sebelum Anda kurangi guidance: sampling 8-step adalah poin di sini.
Pricing Overview ($0.005/image)
 Melalui WaveSpeed, pricing keluar menjadi sekitar $0.005 per gambar pada pengaturan standar. Itu sulit untuk komplain untuk draft, social assets, atau quick experiments. Jika Anda menghasilkan pada skala besar, pantau concurrency caps, latensi tetap rendah bagi saya dengan burst kecil, tetapi saya tidak stress test di luar segelintir pekerjaan paralel.
Melalui WaveSpeed, pricing keluar menjadi sekitar $0.005 per gambar pada pengaturan standar. Itu sulit untuk komplain untuk draft, social assets, atau quick experiments. Jika Anda menghasilkan pada skala besar, pantau concurrency caps, latensi tetap rendah bagi saya dengan burst kecil, tetapi saya tidak stress test di luar segelintir pekerjaan paralel.
Ini berhasil untuk saya, mileage Anda mungkin berbeda. Jika Anda menggugurkan prompt bilingual atau hanya menginginkan teks yang terlihat seperti miliknya dalam gambar, itu layak dilihat. Hal terakhir yang saya perhatikan, hampir secara kebetulan: saya berhenti screenshot dan edit berulang kali. Lebih sedikit detour. Itu terasa seperti pointnya.
Artikel Terkait

Seedance 2.0 Segera Hadir: Model Video Generasi Berikutnya ByteDance dengan Audio Asli

Panduan Lengkap Seedance 2.0: Pembuatan Video Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Perbandingan Generasi Video AI Terlengkap

Panduan Lengkap Seedream 5.0-Preview: Generasi Gambar Cerdas

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Perbandingan Lengkap
