DeepSeek V4 vs Claude Opus 4.5 untuk Coding: Perbandingan Benchmark

Hei semuanya! Dora di sini. Minggu pagi lalu, saya melompat antara editor saya dan jendela chat untuk menambal tes yang mudah berubah, dan model terus mengarang impor yang tidak ada. Bukan masalah besar, hanya salah satu luka kertas yang memperlambat tangan Anda. Saya ingin melihat apakah beralih model akan meringankan beban, bukan hanya pada waktu dinding jam, tetapi pada upaya mental yang diperlukan untuk mempercayai apa yang mendarat di repo saya.
Jadi saya menghabiskan minggu terakhir (27 Jan–1 Feb, 2026) menjalankan loop sederhana yang dapat diulang: tugas yang sama, snapshot repo yang sama, bergantian antara DeepSeek V4 dan Claude Opus 4.5. Ini bukan studi lab. Ini adalah jenis pemeriksaan yang akan saya lakukan sebelum memasang model ke CI. Jika Anda juga mempertimbangkan DeepSeek V4 vs Claude Opus 4.5 untuk pengkodean, ini adalah catatan yang ingin saya baca sebelum melakukan peralihan.

Pemimpin Benchmark Saat Ini
Peringkat SWE-bench Terverifikasi
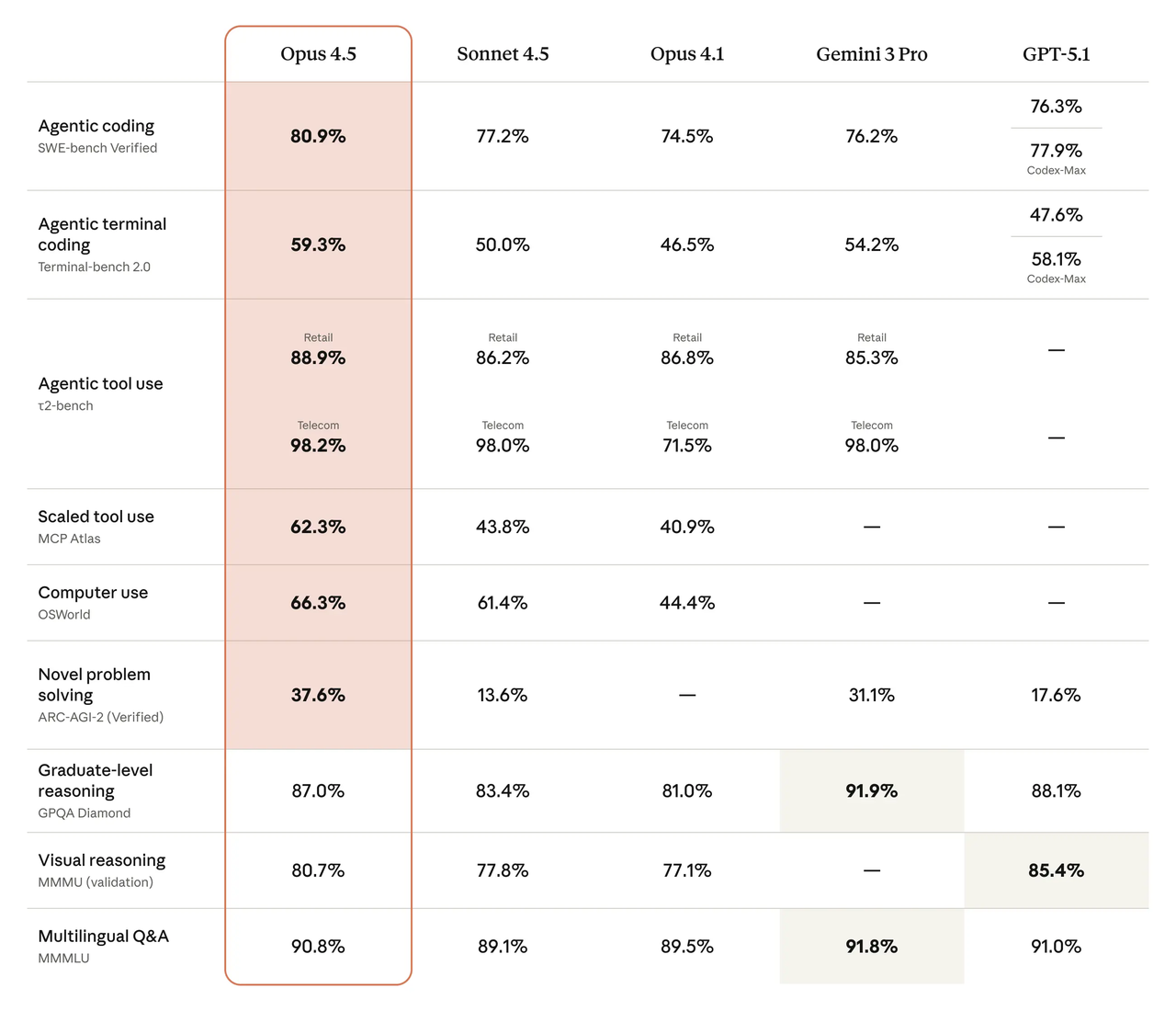
Ketika saya membutuhkan gambaran cepat tentang ke mana angin bertiup, saya mulai dengan papan peringkat publik. Di papan peringkat SWE-bench Terverifikasi, baik model terbaru DeepSeek maupun keluarga Claude yang lebih baru dari Anthropic duduk di dekat puncak, dengan celah kecil yang berubah minggu ke minggu saat prompt, tool, dan harnes evaluasi bergeser. Apa yang penting bagi saya bukanlah angka tunggal, tetapi polanya: model mana yang menyelesaikan masalah end-to-end secara konsisten tanpa sanggahan tool, dan seberapa sensitif mereka terhadap tweak prompt.
Bacaan cepat saya, pada awal Februari 2026:
- DeepSeek V4 menunjukkan pergerakan kuat pada tugas multi-file, skala repo ketika Anda memberinya semua konteks yang diminta. Ini mendapat manfaat dari prompt panjang dan peta file eksplisit.
- Claude Opus 4.5 menghasilkan hasil yang stabil dan cenderung mundur lebih sedikit ketika saya memotong konteks atau menghapus pesan sistem. Ini tidak mencolok, tetapi lantainya terasa tinggi.
Skor HumanEval
HumanEval lebih sempit, masalah pengkodean pendek dengan tes unit, tetapi ini adalah tes aroma yang berguna untuk pembuatan kode out-of-the-box. Ringkasan terkini di repo HumanEval OpenAI dan pelacak komunitas seperti papan peringkat EvalPlus menempatkan kedua model di tingkat atas. Saya tidak menambatkan pada skor pass@1 yang tepat di sini: saya mengamati stabilitas di seluruh seed dan seberapa sering model bergantung pada trik bahasa daripada menulis kode yang langsung dan idiomatis.
 Dalam percobaan saya, DeepSeek V4 kadang menghasilkan solusi yang lebih panjang dan lebih “penjelasan”, baik, tetapi tidak selalu apa yang saya inginkan dalam diff yang ketat. Claude Opus 4.5 lebih sering mengembalikan fungsi kompak yang berlayar melalui tes tanpa komentar tambahan. Benchmark menunjukkan perbedaan ini: pekerjaan hands-on membuatnya jelas.
Dalam percobaan saya, DeepSeek V4 kadang menghasilkan solusi yang lebih panjang dan lebih “penjelasan”, baik, tetapi tidak selalu apa yang saya inginkan dalam diff yang ketat. Claude Opus 4.5 lebih sering mengembalikan fungsi kompak yang berlayar melalui tes tanpa komentar tambahan. Benchmark menunjukkan perbedaan ini: pekerjaan hands-on membuatnya jelas.
Di Mana Setiap Model Unggul
Konteks Panjang (DeepSeek)
Jika Anda ingin mereproduksi setup ini dari awal hingga akhir, saya menyiapkan panduan quick start DeepSeek V4 singkat yang menjelaskan dasar-dasar chat dan API yang saya andalkan di sini.
Saya memberikan kedua model tugas nyata: refactor layanan FastAPI kecil yang telah tumbuh menjadi kekacauan. Sekitar 14 file penting, ditambah README yang… optimis. Saya memzip snapshot repo dan memberi ringkasan file bersama dengan call graph yang saya buat dengan skrip cepat. DeepSeek V4 merasa tenang dengan jangkauan itu. Ini melacak efek lintas file dan tidak panik ketika saya meminta rencana bertahap: antarmuka pertama, tes kedua, penangan terakhir. Bagian yang mengejutkan adalah betapa baiknya penggunaan hint struktural, ketika saya memberikannya “peta” sederhana dari nama file dan tanggung jawab, itu berhenti menyarankan edit ke file yang tidak ada.
Dua catatan praktis:
- Itu membutuhkan ruang untuk bernapas. Ketika saya memotong konteks terlalu agresif, itu menjadi hati-hati dan mulai meminta melihat file yang sudah saya berikan. Setelah saya memberinya gambaran lengkap, itu bergerak dengan bersih.
- Ini menangani prompt “Apa yang saya lewatkan?” dengan baik. Saya akan meminta edge case berdasarkan suite tes dan itu mengungkap tiga yang saya lupakan: header auth kosong, param pagination yang rusak, dan jalur lambat dalam error logging.
Ini tidak menghemat waktu pada awalnya. Setup awal, konteks kemasan, menulis peta file singkat, memakan waktu sekitar 20 menit. Tetapi setelah beberapa kali, beban mental turun. Saya tidak menggoda-godai sebanyak kekhawatiran “apakah saya memberitahunya X?”. Jika hari pengkodean Anda terlihat seperti diff besar tersebar di beberapa modul, DeepSeek V4 memiliki tangan yang stabil ketika konteksnya menjadi luas.
Keandalan Kode (Claude)
 Claude Opus 4.5 memenangkan saya dengan cara yang berbeda: lebih sedikit tepi tajam. Ketika saya meminta patch minimal, itu memberinya satu. Ketika saya meminta rencana tiga langkah dengan dry run, itu tidak menghidupkan perintah. Dan itu menolak dorongan untuk “meningkatkan” hal yang tidak saya minta.
Claude Opus 4.5 memenangkan saya dengan cara yang berbeda: lebih sedikit tepi tajam. Ketika saya meminta patch minimal, itu memberinya satu. Ketika saya meminta rencana tiga langkah dengan dry run, itu tidak menghidupkan perintah. Dan itu menolak dorongan untuk “meningkatkan” hal yang tidak saya minta.
Contoh kecil: saya memiliki tes yang mudah berubah di sekitar matematika zona waktu. Prompt saya kasar: “Perbaiki tes tanpa mengubah kode produksi, dan jelaskan akar penyebabnya dalam satu kalimat.” Claude menyarankan parametrisasi fixture tz dan menyesuaikan satu pernyataan untuk menggunakan datetime yang aware. Itu lulus pada percobaan pertama. DeepSeek juga memperbaikinya, tetapi itu mencoba refactor pembantu dalam napas yang sama. Tidak salah, hanya lebih berat dari yang saya inginkan.
Selama lima tugas, diff Claude secara konsisten lebih kecil. Lebih sedikit impor muncul dari tidak ada. Dan ketika itu menebak, itu meninggalkan catatan yang rapi: “Asumsi pytz tersedia: jika tidak, ganti dengan zoneinfo.” Jenis saran yang hedged itu mudah diaudit.
Dua batasan muncul:
- Claude bermain aman pada kinerja. Dalam satu kasus, itu memilih kejelasan daripada peningkatan O(n) sederhana yang DeepSeek tunjukkan segera. Saya harus mendorongnya: “Optimalkan dalam batasan yang sama.” Itu memang, tetapi tidak akan melompat duluan.
- Dengan prompt yang sangat panjang, saya mencapai plafon lebih cepat. Ringkasan membantu, tetapi DeepSeek terasa kurang sempit ketika saya ingin model untuk “menahan seluruh aplikasi dalam kepalanya.”
Jika hari Anda sebagian besar adalah patch bedah, perbaikan tes, dan kode lem di sekitar API, Claude Opus 4.5 menjaga perubahan ramping dan dapat diprediksi. Itu, dalam praktik, adalah keandalan yang bisa saya rasakan.
Cara Menjalankan Perbandingan Anda Sendiri
 Jika Anda ragu-ragu tentang DeepSeek V4 vs Claude Opus 4.5 untuk pengkodean, eksperimen singkat yang membosankan memberitahu Anda lebih banyak daripada leaderboard apa pun. Berikut adalah loop yang saya gunakan, tweak dengan bebas.
Jika Anda ragu-ragu tentang DeepSeek V4 vs Claude Opus 4.5 untuk pengkodean, eksperimen singkat yang membosankan memberitahu Anda lebih banyak daripada leaderboard apa pun. Berikut adalah loop yang saya gunakan, tweak dengan bebas.
1. Pilih tugas yang bergema dengan minggu Anda
- Satu chore repo (refactor atau ekstraksi modul)
- Satu tes yang mudah berubah
- Satu perubahan integrasi API
- Satu penyesuaian algoritma kecil
Jaga masing-masing di bawah 45 menit. Timebox interaksi, bukan hanya generasi model.
2. Bekukan input
- Pin commit spesifik. Jangan pindahkan target sementara Anda menguji.
- Tentukan apa yang dapat dilihat model: file lengkap vs. excerpt. Tulis peta file singkat jika Anda melewati excerpt.
- Gunakan gaya prompt sistem yang sama untuk kedua model. Saya menyimpannya polos: “Anda adalah asisten pengkodean yang membantu. Lebih suka diff minimal dan kode yang dapat dijalankan.”
3. Tulis prompt yang dapat Anda gunakan kembali
- Tugas: “Ini adalah tujuan, batasan, dan tes.”
- Konteks: daftar file atau ringkasan, ditambah pit falls yang diketahui.
- Format output: “Usulkan rencana (bullets), kemudian diff, kemudian catatan risiko satu kalimat.”
4. Tangkap sinyal yang sama untuk keduanya
- Upaya untuk melewati tes (1–N)
- Baris berubah dalam diff (kasar baik-baik saja)
- Catatan yang harus Anda tulis untuk model (“Berhenti mengedit X”, “Gunakan pembantu Y yang ada”)
- Waktu ke tes hijau pertama
5. Lindungi dari kebocoran
- Nonaktifkan tool kecuali Anda berencana membandingkan penggunaan tool. Jika satu model shell out dan yang lain tidak, Anda tidak menguji hal yang sama.
- Jika Anda mengizinkan pengambilan, tunjuk keduanya ke snapshot doc yang sama.
6. Sanity-check dengan benchmark, jangan menyembah mereka
- Lihat sekilas SWE-bench Terverifikasi untuk melihat apakah hasil Anda terlihat sangat berbeda. Jika demikian, periksa prompt Anda sebelum Anda menyalahkan model.
- Untuk masalah gigitan, skim sampel HumanEval di repo resmi atau jalankan beberapa secara lokal. Konsistensi di seluruh beberapa seed lebih mengungkapkan daripada satu lari.
7. Opsional: tambahkan rubrik kecil
Skor 1–5 pada:
- Minimalisme diff (apakah itu hanya menyentuh apa yang diperlukan?)
- Disiplin fixture (tes, env, dependensi)
- Perilaku pemulihan (apakah itu self-correct ketika Anda menunjukkan miss?)
- Kualitas penjelasan (satu atau dua kalimat yang jelas, bukan posting blog)
Apa yang saya perhatikan dalam praktik
- Apakah model menghormati batasan pertama kali?
- Ketika itu salah, apakah itu salah dengan cara yang mudah diketahui?
- Apakah saya merasa aman membiarkan itu menyarankan patch saat saya context-switching?
Ini berhasil untuk saya, perjalanan Anda mungkin berbeda. Intinya bukan mahkota pemenang: ini untuk melihat mana yang mengurangi drag kognitif Anda dengan kode Anda, dalam jadwal Anda.
Artikel Terkait

Seedance 2.0 Segera Hadir: Model Video Generasi Berikutnya ByteDance dengan Audio Asli

Panduan Lengkap Seedance 2.0: Pembuatan Video Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Perbandingan Generasi Video AI Terlengkap

Panduan Lengkap Seedream 5.0-Preview: Generasi Gambar Cerdas

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Perbandingan Lengkap
