DeepSeek V4 Konteks 1M Token: Cara Meminta Seluruh Codebase

Hei teman-teman. Saya Dora. Pertama kali saya memasukkan proyek lengkap ke jendela token 1M milik DeepSeek V4, saya tidak merasa kuat. Saya merasa hati-hati. Satu juta token terdengar seperti kopi tak terbatas, tetapi siapa pun yang pernah mencoba berpikir selama berjam-jam dengan cairan kafein tahu bahwa tepinya menjadi kabur. Saya ingin melihat apakah ukuran konteks baru ini benar-benar akan mengubah cara saya bekerja, atau hanya mendorong saya untuk menempel lebih banyak.
Saya menghabiskan beberapa hari (27-30 Jan, 2026) menggunakan DeepSeek V4 1M token pada tiga tugas yang sering saya hadapi:
- membaca monorepo berukuran sedang tanpa menyiapkan secara lokal,
- melacak bug di seluruh layanan yang saling berkomunikasi terlalu banyak,
- dan meminta saran refactor yang tidak menghancurkan test.
Apa yang saya pelajari: Anda bisa menampung banyak hal, tetapi model masih membutuhkan Anda untuk menunjuk di peta. Keuntungan tidak datang dari menyodorkan lebih banyak file: keuntungan datang dari cara saya mengatur prompt dan cara saya meminta model bergerak melaluinya.
Apa yang 1M Token Sebenarnya Berarti
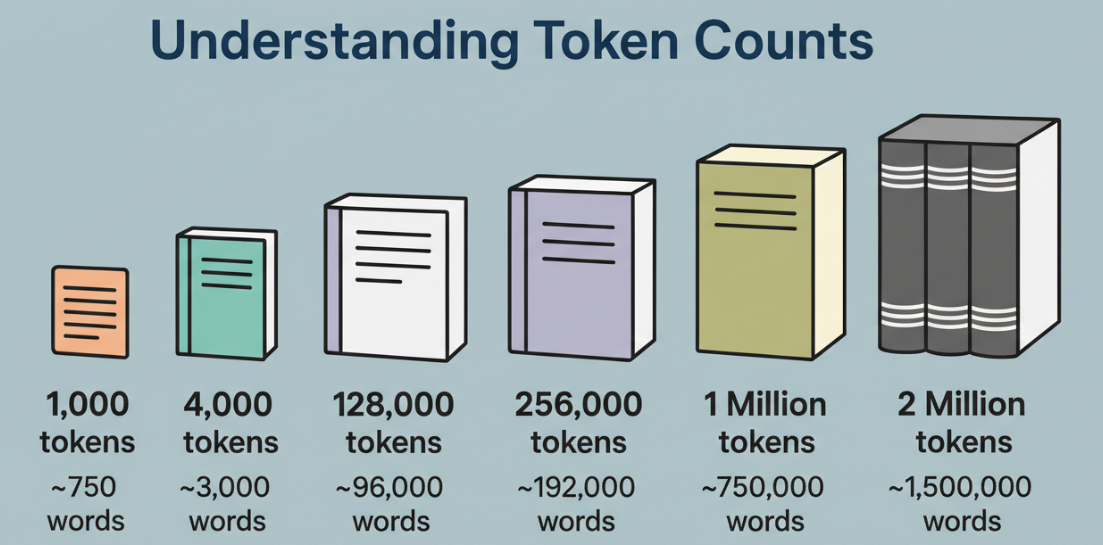 Saya tidak peduli dengan angkanya sendiri. Saya peduli dengan apa yang dapat ditampungnya dengan pikiran yang jernih.
Saya tidak peduli dengan angkanya sendiri. Saya peduli dengan apa yang dapat ditampungnya dengan pikiran yang jernih.
Sebuah token bukanlah kata. Itu adalah potongan, kadang-kadang kata lengkap, kadang-kadang bagian dari satu, kadang-kadang tanda baca. Dalam teks bahasa Inggris, saya biasanya menganggap 1 token sebagai ~0,75 kata untuk perencanaan kasar. Untuk kode, token datang cepat: kurung kurawal, titik, nama metode, semuanya dipotong. Satu juta token adalah banyak wilayah, tetapi itu bukan perhatian yang tak terbatas.
Apa yang berubah untuk saya minggu ini: saya berhenti memangkas secara agresif. Dengan konteks 128K, saya akan merangkum secara agresif dan tetap hanya jalur panas. Dengan 1M, saya bisa menjaga jalur panas ditambah file “dingin” yang cenderung mengejutkan saya nanti (config, migrasi, script build, workflow glue). Artinya, jika saya menumpahkan semuanya sekaligus, jawabannya menjadi samar. Ketika saya memberi makan model secara bertahap, dengan signpost yang jelas, output terasa tertanam.
Setara dengan Baris Kode
Matematika kasar yang saya gunakan saat bekerja:
- Banyak repo mencampur kode dan docs. Di folder yang berat kode, saya melihat ~2-3 token per karakter dalam bahasa padat, tetapi shortcut praktis: pikirkan ~4 token per baris untuk baris sederhana, ~8-12 untuk baris dunia nyata dengan indentasi, nama, dan komentar.
- Dengan kecepatan itu, 1M token menampung sekitar 80K-150K baris kode, tergantung gaya dan bahasa. Layanan TypeScript dengan komentar dan naming ramah-lint berada di sisi yang lebih tinggi. Bundle minified meledak hitungannya dan tidak layak untuk disertakan.
Dalam praktiknya, “kecocokan aman” saya adalah ~60K baris sumber yang bermakna + docs dan test yang ditargetkan. Saya bisa lebih tinggi, tetapi latensi naik dan jawaban melunak. Hasil Anda mungkin berbeda dengan aturan tokenizer dan campuran bahasa.
vs Model Saat Ini (128K)
Melompat dari 128K ke 1M terasa kurang seperti ransel yang lebih besar dan lebih seperti membawa gerobak. Anda dapat membawa lebih banyak, tetapi Anda tidak akan berlari cepat.
Apa yang saya perhatikan:
- Latensi: Prompt dengan konteks penuh memakan waktu lebih lama. Ketika saya membagi sesi (tahap demi tahap), latensi terasa dapat dikelola.
- Recall: Dengan 128K, model sering “lupa” file sebelumnya kecuali saya mengulangi bagian kuncinya. Dengan 1M, itu tidak lupa, tetapi kadang-kadang menggeneralisasi daripada mengutip spesifik. Saya beruntung lebih besar ketika saya memintanya untuk mengutip jalur file dan jangkauan baris jika memungkinkan.
- Presisi: Semakin besar konteksnya, semakin banyak Anda membutuhkan perilaku pengindeksan dalam prompt Anda. Jika tidak, Anda mendapatkan ringkasan yang kompeten yang menghindari kasus tepi yang berantakan yang benar-benar Anda pedulikan.
Jika Anda berharap 1M token berarti “tidak ada lagi prompt engineering,” saya tidak akan mengandalkannya. Ini menggeser jenis steering yang Anda lakukan.
Struktur Prompt untuk Codebase Besar
 Saya berhenti menganggap prompt sebagai pesan dan mulai memperlakukannya seperti rencana membaca. Model dapat membaca banyak sekarang, tetapi masih mendapat manfaat dari daftar isi dan jejak.
Saya berhenti menganggap prompt sebagai pesan dan mulai memperlakukannya seperti rencana membaca. Model dapat membaca banyak sekarang, tetapi masih mendapat manfaat dari daftar isi dan jejak.
Apa yang paling berhasil untuk saya terlihat seperti ini: framing sistem pendek, indeks proyek ringkas, urutan penjelajahan yang dideklarasikan, kemudian tugas spesifik. Dan kemudian saya terus percakapan dalam putaran, bukan satu mega-prompt.
Urutan File
Saya mendapat jawaban yang lebih andal ketika saya memberi tahu model apa yang harus dibuka terlebih dahulu, kedua, ketiga. Satu daftar di atas membantu membangun tumpukan mental:
- Mulai dengan entry point (CLI, HTTP handler, job). Ini menempatkan aliran.
- Kemudian lapisan komposisi (DI container, main.ts, app.py) tempat dependensi terhubung.
- Selanjutnya, modul domain inti dan antarmuka mereka.
- Hanya kemudian: pembantu, utils, dan potongan lintas-cutting (logging, telemetri, config).
- Test terakhir, kecuali saya men-debug kegagalan spesifik, dalam hal itu, mulai dengan spec yang gagal untuk menetapkan harapan.
Saya juga menyertakan catatan “jangan baca” untuk folder yang terlihat penting tetapi tidak: kode yang dihasilkan, aset yang dikompilasi, snapshot. Ini menghemat token dan menjaga perhatian model pada kode yang hidup.
Sebuah trik kecil: saya meminta model untuk mempertahankan daftar rolling “file aktif” (jalur dan ringkasan singkat) dan untuk memperbaruinya saat kami bergerak. Ketika itu melayang, saya bisa menunjuk kembali ke daftar itu dan berkata, “Tetaplah di dalam set ini untuk sekarang.” Itu menjaga jawaban konkret.
Pemetaan Dependensi
Salah satu pass paling berguna adalah meminta peta dependensi awal, bukan sebagai diagram tetapi sebagai tabel tepi sederhana: modul A mengimpor B, B menggunakan C, C mengenai variabel lingkungan, dan seterusnya. Saya menjaganya tekstual dan ringkas.
Apa yang ini lakukan dalam praktik:
- Itu mengekspos dependensi tersesat (jenis yang mencurangi masalah di seluruh folder).
- Ini memberi saya daftar pendek “titik tekanan” untuk ditinjau sebelum refactor apa pun.
- Ini membantu model mereferensikan tempat yang tepat ketika saya meminta perubahan.
Saya juga membuat model menyatakan asumsi, apa yang disimpulkannya dari penamaan, komentar, atau test. Ketika asumsi keluar, saya memperbaikinya sekali, dan langkah-langkah selanjutnya tetap lebih bersih.
Satu peringatan: meminta peta dependensi lengkap di repo besar dalam satu kali menarik waktu tunggu dan grafik samar. Saya mendapat hasil yang lebih baik dengan lingkup menurut lapisan (misalnya, hanya akses data, hanya HTTP handler) dan kemudian menggabungkan catatan sendiri. Dibutuhkan 10 menit ekstra tetapi membayar kembali dalam akurasi.
Strategi Chunking Saat Dibutuhkan
 Bahkan dengan jendela token 1M, saya masih chunking. Bukan karena itu tidak bisa muat, tetapi karena pemikiran saya lebih baik dalam tahap, dan model menjawab dengan lebih presisi ketika saya mempersempit bidang pandangannya.
Bahkan dengan jendela token 1M, saya masih chunking. Bukan karena itu tidak bisa muat, tetapi karena pemikiran saya lebih baik dalam tahap, dan model menjawab dengan lebih presisi ketika saya mempersempit bidang pandangannya.
Beberapa pola yang bertahan minggu ini:
- Tahapkan ringkasan: Saya mulai dengan konteks kecil, indeks proyek, tugas, kendala yang diketahui, kemudian meminta rencana membaca dan verifikasi. Hanya setelah itu saya memberi makan kode dalam urutan yang kami setujui.
- Batasi set aktif: Untuk refactor, saya menjaga hanya 5-12 file yang sedang dimainkan dan meminta perubahan dengan jalur eksplisit. Jika edit menyentuh util bersama, saya menambahkan file itu di putaran berikutnya. Model tetap ketat.
- Ringkas pada tepi: Sebelum pindah ke folder baru, saya meminta ringkasan singkat tentang apa yang kami pelajari dan ketidakpastian apa pun. Ringkasan ini bertindak seperti breadcrumb di seluruh putaran tanpa menempel ulang setiap file.
- Gunakan pengambilan dengan tujuan: Untuk repo yang tidak muat dengan nyaman, saya menggunakan embedding untuk memanggil file berdasarkan kueri (“normalisasi id pembayaran”, “backoff retry”). Saya menjaga set yang diambil tetap kecil per putaran, biasanya di bawah 40K token, sehingga balasan tidak buram.
- Verifikasi maju, bukan mundur: Alih-alih bertanya, “Apakah Anda menggunakan semuanya yang saya tempel?” Saya bertanya, “Tunjukkan kepada saya fungsi spesifik dan baris yang saran Anda bergantung.” Itu memaksa referensi konkret dan membuat kesalahan jelas.
Gesekan yang saya alami:
- Latensi merambat ketika Anda mengirim pesan konteks penuh setiap putaran. Staging memotong waktu respons rata-rata saya dari 70-90 detik menjadi 20-40 detik pada tugas yang sama.
- Biaya penting. Prompt besar bertambah. Saya menghemat token dengan memangkas komentar yang mengulangi yang jelas, menghapus artefak yang dikompilasi, dan melewati bundle vendor.
- Efek posisi nyata. Konten di awal atau akhir prompt raksasa cenderung lebih “tersedia.” Saya mengatasi ini dengan mengulangi kendala kecil yang penting di dekat akhir setiap putaran.
Siapa yang mendapat manfaat dari jendela 1M?

- Jika Anda tinggal di monorepo, menangani audit, atau melakukan refactor lintas-cutting, itu membeli Anda lebih sedikit langkah setup dan overhead pengindeksan lokal. Itu titik awal yang lebih tenang.
- Jika pekerjaan Anda sebagian besar perbaikan bug terfokus di layanan kecil, kapasitas ekstra tidak akan banyak membantu. Konteks yang lebih kecil ditambah pipeline retrieval yang ketat akan terasa lebih cepat.
Catatan tentang kepercayaan: Saya meminta model untuk mengutip baris kode yang tepat untuk perubahan berisiko (migrasi, auth). Ketika itu ragu atau parafrase, saya memperlakukannya sebagai bendera untuk mempersempit ruang lingkup atau menempel file spesifik lagi. Kebiasaan kecil itu mencegah beberapa kesalahan hampir-misses.
Jika Anda ingin deskripsi formal tentang batas model atau perilaku tokenizer, periksa docs penyedia. Ketika saya membutuhkan spesifik, saya kembali ke kartu model resmi dan catatan jendela konteks. Itu membuat saya jujur tentang apa yang saya minta model lakukan.
Ini bukan sihir. Ini hanya meja yang lebih besar. Berguna, jika Anda mengatur kursinya.
Saya terus memikirkan satu hal kecil dari Selasa: saya meminta perbaikan, dan model menyarankan untuk mengubah fungsi yang terlihat benar pada pandangan sekilas. Itu tidak. Bug itu hidup di pembantu dua lapisan ke bawah. Satu juta token tidak mengubah itu. Catatan saya lakukan.
Artikel Terkait

Seedance 2.0 Segera Hadir: Model Video Generasi Berikutnya ByteDance dengan Audio Asli

Panduan Lengkap Seedance 2.0: Pembuatan Video Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Perbandingan Generasi Video AI Terlengkap

Panduan Lengkap Seedream 5.0-Preview: Generasi Gambar Cerdas

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Perbandingan Lengkap
