WaveSpeedAI X DataCrunch : Inférence d'Images FLUX en Temps Réel sur B200

WaveSpeedAI X DataCrunch : Inférence d’images FLUX en temps réel sur B200
WaveSpeedAI s’est associée au fournisseur de cloud GPU européen DataCrunch pour réaliser une avancée majeure dans le déploiement de modèles de génération d’images et de vidéos. En optimisant le modèle open-weight FLUX-dev sur les GPU NVIDIA B200 de pointe de DataCrunch, notre collaboration offre une inférence d’images jusqu’à 6× plus rapide par rapport aux bases de référence standards de l’industrie.
Dans cet article, nous fournissons un aperçu technique du modèle FLUX-dev et du GPU B200, discutons des défis de la mise à l’échelle de FLUX-dev avec des piles d’inférence standard, et partageons les résultats des benchmarks démontrant comment le framework propriétaire de WaveSpeedAI améliore significativement la latence et l’efficacité des coûts. Les équipes ML d’entreprise apprendront comment cette solution WaveSpeedAI + DataCrunch se traduit par des réponses API plus rapides et une réduction significative du coût par image – permettant aux applications d’IA du monde réel de fonctionner. (WaveSpeedAI a été fondée par Zeyi Cheng, qui dirige notre mission d’accélérer l’inférence de l’IA générative.)
Cet article est également publié sur le blog de DataCrunch.
FLUX-Dev : modèle de génération d’images SOTA
FLUX-dev est un modèle de génération d’images open-source de pointe (SOTA) capable de générer des images à partir de texte et d’image à partir d’image. Ses capacités incluent une bonne compréhension du monde et une adhérence aux instructions (grâce à l’encodeur de texte T5), la diversité des styles, la compréhension de la sémantique et de la composition des scènes complexes. La qualité de la sortie du modèle est comparable ou peut surpasser les modèles fermés populaires comme Midjourney v6.0, DALL·E 3 (HD) et SD3-Ultra. FLUX-dev est rapidement devenu le modèle de génération d’images le plus populaire dans la communauté open-source, établissant un nouveau benchmark pour la qualité, la polyvalence et l’alignement avec les instructions.
FLUX-dev utilise le flow matching, et son architecture de modèle est basée sur une architecture hybride de blocs transformateur de diffusion multimodaux et parallèles. L’architecture contient 12B paramètres, environ 33 GB en fp16/bf16. Par conséquent, FLUX-dev est très exigeant en termes de calcul avec ce grand nombre de paramètres et ce processus de diffusion itérative. Une inférence efficace est essentielle pour les scénarios d’inférence à grande échelle où l’expérience utilisateur est cruciale.
Architecture GPU Blackwell de NVIDIA : B200
L’architecture Blackwell inclut de nouvelles fonctionnalités telles que les cœurs tenseurs de 5e génération (fp8, fp4), la Mémoire Tensor (TMEM) et les paires CTA (2 CTA).
-
TMEM : Tensor Memory est un nouveau niveau de mémoire sur puce, complétant la hiérarchie traditionnelle des registres, de la mémoire partagée (L1/SMEM) et de la mémoire globale. Dans Hopper (par ex. H100), les données sur puce étaient gérées via les registres (par thread) et la mémoire partagée (par bloc de thread ou CTA), avec des transferts à haute vitesse via l’Accélérateur de Mémoire Tensor (TMA) dans la mémoire partagée. Blackwell conserve ceux-ci mais ajoute TMEM comme 256 KB supplémentaires de SRAM par SM dédiés aux opérations de cœur tenseur. TMEM ne change pas fondamentalement la façon dont vous écrivez les noyaux CUDA (l’algorithme logique est le même) mais ajoute de nouveaux outils pour optimiser le flux de données (voir ThunderKittens Now Optimized for NVIDIA Blackwell GPUs).
-
2CTA (Paires CTA) et Coopération en Cluster : Blackwell introduit également les paires CTA comme un moyen de coupler étroitement deux CTA sur le même SM. Une paire CTA est essentiellement un cluster de taille 2 (deux blocs de thread planifiés simultanément sur un SM avec des capacités de synchronisation spéciales). Bien que Hopper permette jusqu’à 8 ou 16 CTA dans un cluster pour partager des données via DSM, la paire CTA de Blackwell leur permet d’utiliser collectivement les cœurs tenseurs sur les données communes. En fait, le modèle PTX de Blackwell permet à deux CTA d’exécuter les instructions des cœurs tenseurs qui accèdent au TMEM les uns des autres.
-
Cœurs tenseurs de 5e génération (fp8, fp4) : Les cœurs tenseurs du B200 sont notablement plus grands et ~2–2,5× plus rapides que les cœurs tenseurs du H100. L’utilisation élevée des cœurs tenseurs est essentielle pour réaliser les améliorations majeures de matériel de nouvelle génération (voir Benchmarking and Dissecting the Nvidia Hopper GPU Architecture).
Chiffres de performance sans sparsité
| Spécifications Techniques | ||
|---|---|---|
| H100 SXM | HGX B200 | |
| FP16/BF16 | 0.989 PFLOPS | 2.25 PFLOPS |
| INT8 | 1.979 PFLOPS | 4.5 PFLOPS |
| FP8 | 1.979 PFLOPS | 4.5 PFLOPS |
| FP4 | NaN | 9 PFLOPS |
| Mémoire GPU | 80 GB HBM3 | 180GB HBM3E |
| Largeur de bande de mémoire GPU | 3.35 TB/s | 7.7TB/s |
| Largeur de bande NVLink par GPU | 900GB/s | 1,800GB/s |
L’analyse comparative au niveau de l’opérateur des noyaux GEMM et attention montre les éléments suivants :
- Noyaux cuBLAS et CUTLASS GEMM en BF16 et FP8 : jusqu’à 2× plus rapides que les GEMM cuBLAS sur H100 ;
- Attention : la vitesse cuDNN est 2× plus rapide que FA3 sur H100.
Les résultats des benchmarks suggèrent que le B200 est exceptionnellement bien adapté aux charges de travail d’IA à grande échelle, en particulier pour les modèles génératifs nécessitant un débit de mémoire élevé et un calcul dense.
Défis des piles d’inférence standard
L’exécution de FLUX-dev sur des pipelines d’inférence typiques (par ex., PyTorch + Hugging Face Diffusers), même sur des GPU haut de gamme comme H100, présente plusieurs défis :
- Latence élevée par image due aux surcharges CPU-GPU et à l’absence de fusion de noyaux ;
- Utilisation GPU sous-optimale et cœurs tenseurs inactifs ;
- Goulots d’étranglement de mémoire et de largeur de bande lors des étapes de diffusion itératives.
Les objectifs d’optimisation de la distribution à grande échelle et de l’inférence bon marché sont un débit plus élevé et une latence plus faible, réduisant le coût de génération d’images.
Framework d’inférence propriétaire de WaveSpeedAI
WaveSpeedAI résout ces goulots d’étranglement avec un framework propriétaire spécialement conçu pour l’inférence générative. Développé par le fondateur Zeyi Cheng, ce framework est notre moteur d’inférence haute performance interne optimisé spécifiquement pour les modèles de transformateur de diffusion de pointe tels que FLUX-dev et Wan 2.1. Les innovations clés du moteur d’inférence incluent :
- Exécution GPU de bout en bout éliminant les goulots d’étranglement CPU ;
- Noyaux CUDA personnalisés et fusion de noyaux pour une exécution optimisée ;
- Quantification avancée et précision mixte (BF16/FP8) utilisant le Moteur Transformer Blackwell tout en maintenant la plus haute précision ;
- Planification mémoire optimisée et préallocation ;
- Mécanismes de planification prioritaires aux latences qui privilégient la vitesse par rapport à la profondeur de traitement par lots.
Notre moteur d’inférence suit une conception matériel-logiciel cooptimisée, utilisant pleinement la capacité de calcul et de mémoire du B200. Elle représente un progrès significatif dans la diffusion des modèles d’IA, nous permettant de fournir une inférence à ultra-faible latence et haute efficacité à l’échelle de la production. Nous évaluons comment ces optimisations impactent la qualité de la sortie, en donnant la priorité aux optimisations sans perte par rapport aux optimisations loosely. Autrement dit, nous n’appliquons pas d’optimisations qui pourraient réduire significativement les capacités du modèle ou effondrer complètement la qualité de sortie visible, comme le rendu de texte et la sémantique de scène.
Benchmark : WaveSpeedAI sur B200 vs. Baseline H100
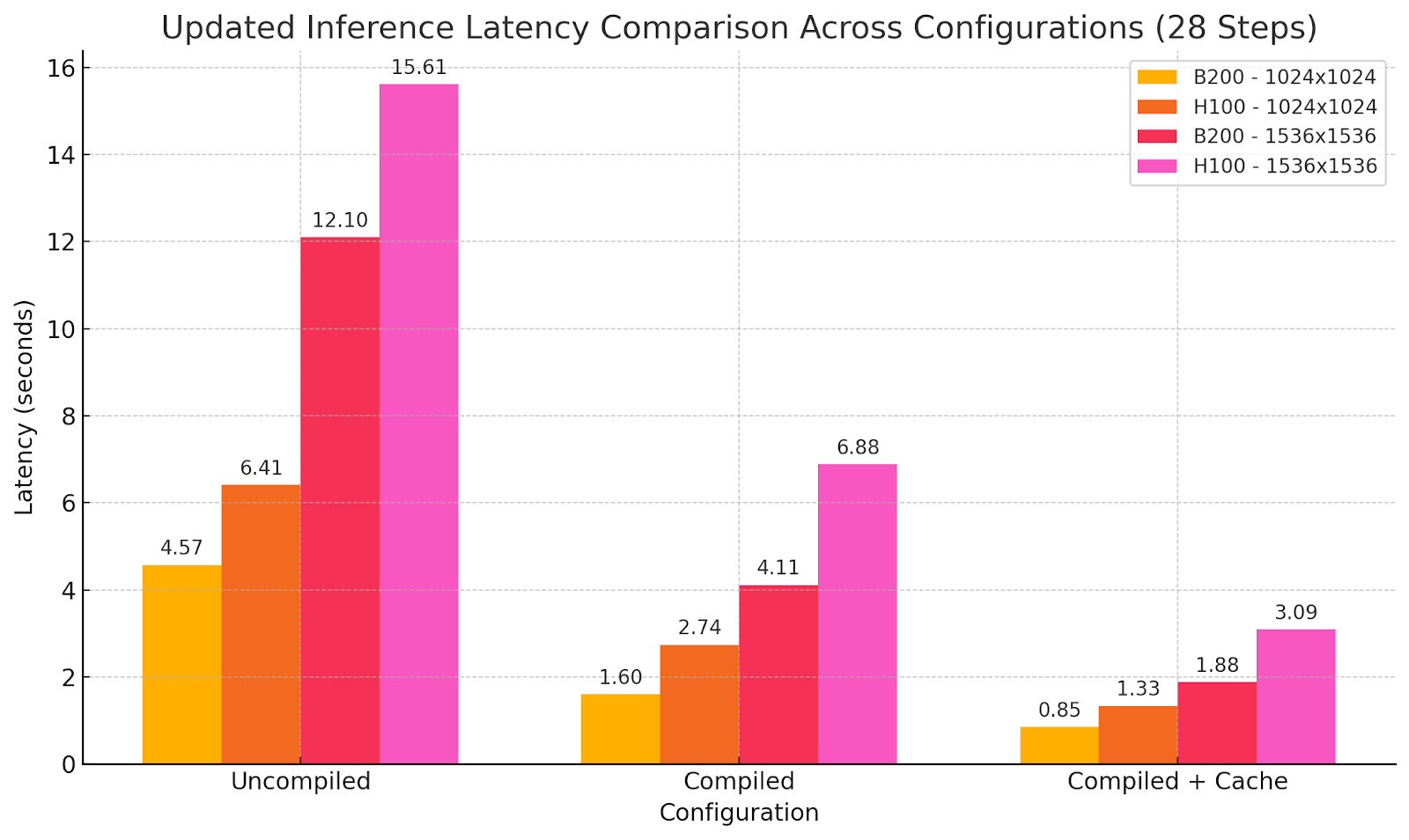
Sorties de modèle utilisant différents paramètres d’optimisation :

Prompt : photographie d’une femme alternative avec un bandana orange, longs cheveux brun clair, lunettes à monture claire, piercing au septum [sic], salopette beige qui glisse sur une épaule, un débardeur blanc en dessous, elle est assise dans son appartement sur un tapis bohème, dans le style d’une séance photo du magazine Vogue
Implications
Les améliorations de performance se traduisent par :
- Conception d’algorithmes d’IA (par ex. mise en cache d’activation DiT) et optimisation système, utilisant des noyaux accordés à l’architecture GPU, pour une meilleure utilisation du matériel ;
- Latence d’inférence réduite ouvrant de nouvelles possibilités (par ex. Test-Time Compute in diffusion models) ;
- Coût par image réduit grâce à une efficacité améliorée et une utilisation réduite du matériel.
Nous avons réalisé un ratio coût-performance B200 égal à H100 mais avec la moitié de la latence de génération. Ainsi, le coût par génération n’augmente pas tout en permettant maintenant de nouvelles possibilités en temps réel sans sacrifier les capacités du modèle. Parfois, plus n’est pas mieux mais différent, et ici nous avons atteint un nouveau stade de performance, offrant un nouveau niveau d’expérience utilisateur dans la génération d’images en utilisant des modèles SOTA.
Cela permet des outils réactifs et créatifs, des plateformes de contenu évolutives et des structures de coûts durables pour l’IA générative à l’échelle.
Conclusion et prochaines étapes
Le déploiement de FLUX-dev utilisant B200 démontre ce qui est possible quand un matériel de classe mondiale rencontre un logiciel de meilleure en sa classe. Nous repoussons les frontières de la vitesse et de l’efficacité de l’inférence chez WaveSpeedAI, fondée par Zeyi Cheng — créateur de stable-fast, ParaAttention et notre moteur d’inférence interne. Dans les prochaines versions, nous nous concentrerons sur l’inférence efficace de la génération vidéo et sur la façon d’réaliser une inférence proche du temps réel. Notre partenariat avec DataCrunch représente une opportunité d’accéder à des GPU de pointe comme B200 et aux futures NVIDIA GB200 NVL72 (Pré-commandez les clusters GB200 NVL72 de DataCrunch) tout en co-développant une pile d’infrastructure d’inférence critique.
Commencez aujourd’hui :
- Site Web WaveSpeedAI
- Tous les modèles WaveSpeedAI
- Documentation API WaveSpeedAI
- Instances DataCrunch B200 à la demande/spot
Rejoignez-nous pour construire l’infrastructure d’inférence générative la plus rapide du monde.
Articles associés

Guide Complet Seedream 5.0-Preview : Génération d'Images Intelligente

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image : Comparaison Complète

Apple SHARP : Transformez n'importe quelle photo en 3D en moins d'une seconde

Seedream 4.5 vs Nano Banana Pro : Quel modèle d'IA pour la génération d'images est le meilleur ?
Meilleure alternative à Adobe Firefly en 2026 : WaveSpeedAI pour la génération d'images par IA