HunyuanImage-3.0 : Faire avancer l'imagerie multimodale open-source

Les générateurs d’images IA sont partout, mais soyons honnêtes — les résultats peuvent être inégaux, surtout avec des invites délicates ou beaucoup de détails.
C’est là que HunyuanImage-3.0 intervient ! C’est le premier modèle multimodal open-source, de qualité industrielle, créé pour la génération d’images, excellant en raisonnement, style, et même rendu de texte long.
Les Avantages Clés
Excellence Esthétique
HunyuanImage-3.0 démontre une compréhension profonde de l’esthétique orientale, incluant les festivals traditionnels, l’opéra et les symboles culturels. Le modèle peut générer des résultats authentiques et visuellement impressionnants. Il s’adapte également efficacement aux différents styles artistiques, de l’art occidental classique au design moderne et aux projets interculturels, en restant toujours fidèle à l’esthétique visée.
Raisonnement Basé sur les Connaissances Mondiales
Pensez à l’IA comme ayant un cerveau qui comprend les connaissances mondiales. Alimenté par une vaste base de connaissances, HunyuanImage-3.0 peut interpréter même des invites simples, comme créer un tutoriel de style bande dessinée — et les transformer en visuels clairs, créatifs et contextuellement riches.
Compréhension Sémantique Puissante
La plupart des générateurs d’images IA ont du mal avec les longs passages ou les petits caractères, mais HunyuanImage-3.0 excelle dans ces scénarios. Il possède une forte compréhension du texte, lui permettant de dépicturer avec précision du contenu textuel détaillé dans les images et de produire des résultats impressionnants.
Qualité Supérieure
Entraîné sur des ensembles de données curés et affiné avec RLHF, le modèle construit une forte conscience contextuelle, lui permettant de générer des résultats non seulement logiquement cohérents mais aussi visuellement époustouflants.
Voir en Pratique
Pour démontrer ces capacités. Maintenant, c’est le moment pour quelques exemples !!
Raisonnement Basé sur les Connaissances Mondiales
Puisque le modèle est rempli de toutes sortes de connaissances amusantes, voyons s’il peut nous guider à travers la fabrication de crème glacée.
Invite : Créer un tutoriel en bande dessinée sur la façon de faire de la crème glacée.

Quelle est la compréhension mathématique du modèle ? Essayons !
Invite : Dessinez le système suivant d’équations linéaires binaires et les étapes de solution correspondantes au tableau noir : 5x+2y= 26; 2x-y= 5.

Le modèle montre clairement une forte compréhension des équations mathématiques, en résolvant chaque étape correctement. Pour ajouter du plaisir, demandons-lui de générer des emojis !
Invite : Feuille de stickers d’un chat chibi orange mignon et expressif. Un ensemble de 12 stickers, chacun montrant une émotion ou une action différente comme pleurer, applaudir, en colère, désolé et confiant. Chaque sticker a une étiquette de texte correspondante (par exemple, “Désolé !”, “Je t’aime !”, “Laisse-moi faire !”). Le style est une illustration vectorielle minimaliste propre avec une bordure blanche épaisse, parfaite pour l’impression.
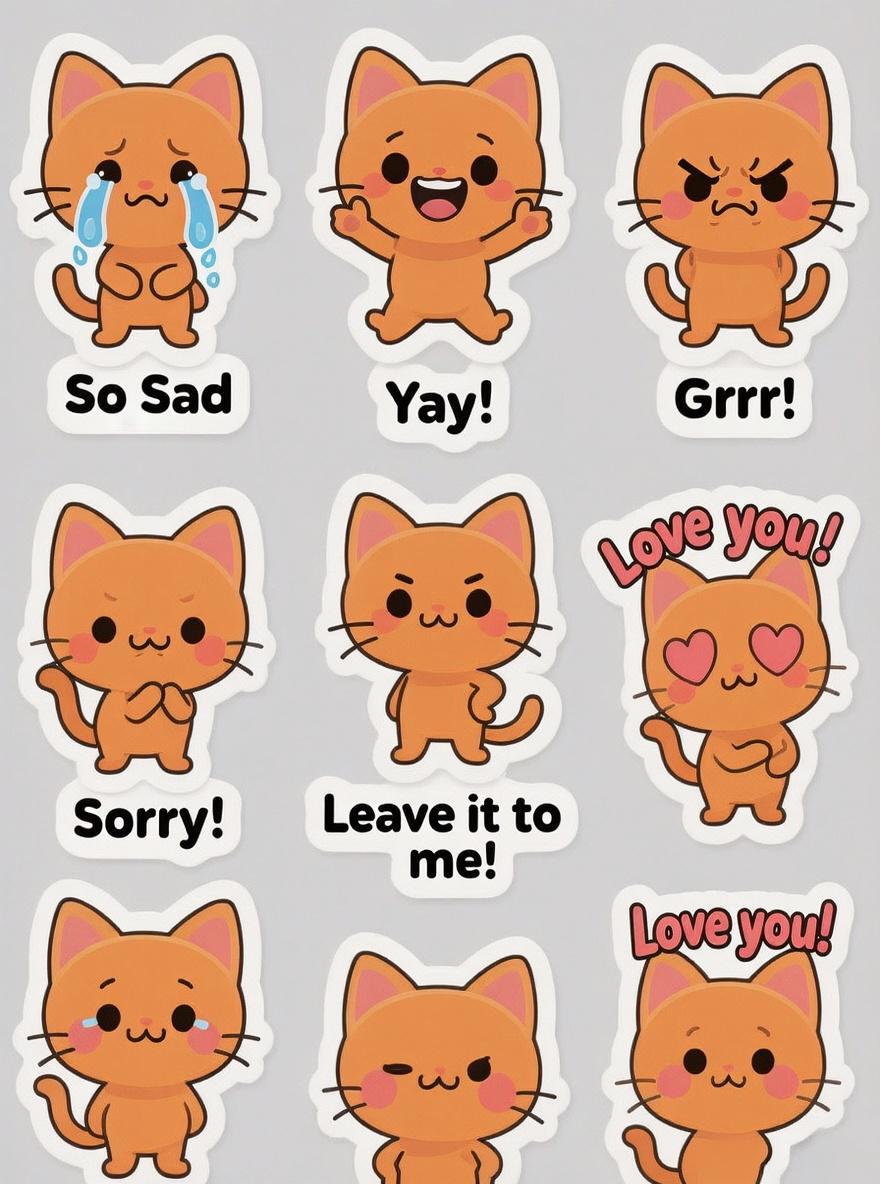
Compréhension Sémantique Super Forte
Pour évaluer la capacité du modèle avec le texte, nous allons sauter les tâches simples et passer directement à la partie difficile : écrire de longs passages au tableau noir !
Invite : Une large image prise avec un téléphone d’un tableau blanc en verre vue de face, dans une pièce donnant sur la baie de Shenzhen. Le champ de vision montre une femme pointant vers l’écriture manuscrite sur le tableau blanc. L’écriture manuscrite semble naturelle et un peu désordonnée. En haut, le titre se lit : “HunyuanImage 3.0”, suivi de deux paragraphes. Le premier paragraphe se lit : “HunyuanImage 3.0 est un modèle open-source de 80 milliards de paramètres qui génère des images à partir de texte complexe avec une qualité supérieure.”. Le deuxième paragraphe se lit : “Il exploite les connaissances mondiales et le raisonnement avancé pour aider les créateurs à produire des visuels professionnels efficacement.” En bas, il y a un sous-titre : “Caractéristiques Clés”, suivi de quatre points. Le premier est ”🧠 Modèle de Langage Multimodal Natif”. Le deuxième est ”🏆 Le Plus Grand Modèle MoE Text-to-Image”. Le troisième est ”🎨 Suivi d’Invites et Généralisation de Concepts”, et le quatrième est ”💭 Pensée Native et Recaption”.

Fantastique ! L’effet est merveilleux !
Excellence Esthétique
Le dernier point fort est la compréhension remarquable du modèle de l’esthétique orientale.
Invite : Une beauté chinoise dans un costume coloré de l’opéra de Pékin, avec un opéra Huadan tendance chinois, un gros plan de la moitié du corps mettant l’accent sur ses yeux captivants. L’image adopte un style de photographie macro, haute définition, imaginative, prise de photo de vraie personne, mettant l’accent sur les détails et le réalisme. La composition utilise une perspective rapprochée, avec la beauté au centre du cadre, ses yeux dominant la position, et l’arrière-plan flou pour mettre en évidence le charme profond de ses yeux. Une lumière froide mystérieuse brille en diagonale d’en haut, créant une atmosphère bleue froide et sévère, avec une lumière douce et concentrée pour rehausser le charme et le mystère de ses yeux. Ouverture f/2.8, objectif macro 100 mm, faible profondeur de champ, résolution 8K.

Invite : Un chat de compagnie mignon affiché dans une grille 3x3 sur un fond solide blanc cassé propre et brillant, présentant neuf poses à thème de la Fête de la Lune du Milieu d’Automne : 1. Portant un petit clip à cheveux en feuille d’érable, tirant la langue pour lécher les miettes de gâteau à la lune sur son nez, avec une expression espiègle. 2. Portant un petit pull de couleur caramel (avec une délicate broderie de lapin de jade), assis droit, tenant une mini lanterne chinoise avec ses pattes avant.

Réflexions Finales
HunyuanImage-3.0 élève la génération de texte en image du simplement fonctionnel au vraiment intelligent et de qualité professionnelle. Avec l’accélération WaveSpeedAI, ses avancées sont pratiques aussi — elles sont rapides, déployables et rentables.
Ensemble, HunyuanImage-3.0 et WaveSpeedAI transforment l’avenir de la création multimodale : plus intelligent, plus rapide et plus accessible !
De plus, vous pouvez nous contacter sur les réseaux sociaux ci-dessous.
Articles associés

Meilleurs éditeurs d'images IA en 2026 : Édition de photos professionnelle avec l'IA
Meilleure alternative à Tencent Hunyuan Image 3.0 en 2026 : WaveSpeedAI pour la génération d'images IA
Guide Complet Hunyuan Image 3.0 : Le Modèle IA à 80B Paramètres de Tencent
Hunyuan Image 3.0 vs Seedream 4.5 : Bataille des géants de l'IA asiatique
WaveSpeedAI vs Tencent Hunyuan Image 3.0 : Quelle plateforme IA offre de meilleurs résultats ?
