WaveSpeedAI X DataCrunch: Inferencia de Imágenes FLUX en Tiempo Real en B200

WaveSpeedAI X DataCrunch: Inferencia de Imágenes FLUX en Tiempo Real en B200
WaveSpeedAI se ha asociado con el proveedor de GPU en la nube europeo DataCrunch para lograr un avance significativo en la implementación de modelos generativos de imágenes y vídeos. Al optimizar el modelo de peso abierto FLUX-dev en la GPU NVIDIA B200 de última generación de DataCrunch, nuestra colaboración ofrece una inferencia de imágenes hasta 6× más rápida en comparación con los estándares de la industria.
En este artículo, proporcionamos una descripción técnica general del modelo FLUX-dev y la GPU B200, analizamos los desafíos de escalar FLUX-dev con pilas de inferencia estándar y compartimos resultados de evaluación comparativa que demuestran cómo el marco propietario de WaveSpeedAI mejora significativamente la latencia y la eficiencia de costos. Los equipos de ML empresariales aprenderán cómo esta solución WaveSpeedAI + DataCrunch se traduce en respuestas de API más rápidas y un costo significativamente reducido por imagen, potenciando aplicaciones de IA del mundo real. (WaveSpeedAI fue fundada por Zeyi Cheng, quien lidera nuestra misión para acelerar la inferencia de IA generativa.)
Este blog se comparte en el blog de DataCrunch.
FLUX-Dev: Modelo de generación de imágenes de última generación
FLUX-dev es un modelo de generación de imágenes de código abierto de última generación (SOTA) capaz de generar imágenes a partir de texto y de imagen a imagen. Sus capacidades incluyen una buena comprensión del mundo y adhesión a solicitudes (gracias al codificador de texto T5), diversidad de estilos, comprensión de semántica de escenas complejas y composición. La calidad de salida del modelo es comparable a o puede superar modelos populares de código cerrado como Midjourney v6.0, DALL·E 3 (HD) y SD3-Ultra. FLUX-dev se ha convertido rápidamente en el modelo de generación de imágenes más popular en la comunidad de código abierto, estableciendo un nuevo estándar de calidad, versatilidad y alineación de solicitudes.
FLUX-dev utiliza flow matching y su arquitectura de modelo se basa en una arquitectura híbrida de bloques multimodales y paralelos de transformador de difusión. La arquitectura tiene 12 mil millones de parámetros, aproximadamente 33 GB en fp16/bf16. Por lo tanto, FLUX-dev es computacionalmente exigente con este gran número de parámetros y proceso de difusión iterativo. La inferencia eficiente es esencial para escenarios de inferencia a gran escala donde la experiencia del usuario es crucial.
Arquitectura de GPU Blackwell de NVIDIA: B200
La arquitectura Blackwell incluye nuevas características como núcleos de tensor de 5ª generación (fp8, fp4), Memoria Tensor (TMEM) y pares CTA (2 CTA).
-
TMEM: La Memoria Tensor es un nuevo nivel de memoria en el chip, aumentando la jerarquía tradicional de registros, memoria compartida (L1/SMEM) y memoria global. En Hopper (p.ej. H100), los datos en el chip se gestionaban mediante registros (por hilo) y memoria compartida (por bloque de hilos o CTA), con transferencias de alta velocidad a través del Acelerador de Memoria Tensor (TMA) a la memoria compartida. Blackwell mantiene esos, pero añade TMEM como 256 KB extra de SRAM por SM dedicados a operaciones de núcleo de tensor. TMEM no cambia fundamentalmente cómo escribes kernels CUDA (el algoritmo lógico es el mismo) pero añade nuevas herramientas para optimizar el flujo de datos (ver ThunderKittens Now Optimized for NVIDIA Blackwell GPUs).
-
2CTA (Pares CTA) y Cooperación de Clústeres: Blackwell también introduce pares CTA como una forma de acoplar estrechamente dos CTAs en el mismo SM. Un par CTA es esencialmente un clúster de tamaño 2 (dos bloques de hilos programados concurrentemente en un SM con capacidades de sincronización especiales). Mientras que Hopper permite hasta 8 o 16 CTAs en un clúster para compartir datos a través de DSM, el par CTA de Blackwell les permite usar los núcleos de tensor en datos comunes colectivamente. De hecho, el modelo PTX de Blackwell permite que dos CTAs ejecuten instrucciones de núcleo de tensor que accedan a TMEM mutuamente.
-
Núcleos de tensor de 5ª generación (fp8, fp4): Los núcleos de tensor en el B200 son notablemente más grandes y ~2–2.5× más rápidos que los núcleos de tensor en el H100. La alta utilización de núcleos de tensor es crítica para lograr grandes aceleraciones de hardware de nueva generación (ver Benchmarking and Dissecting the Nvidia Hopper GPU Architecture).
Números de rendimiento sin esparcimiento
| Especificaciones Técnicas | ||
|---|---|---|
| H100 SXM | HGX B200 | |
| FP16/BF16 | 0.989 PFLOPS | 2.25 PFLOPS |
| INT8 | 1.979 PFLOPS | 4.5 PFLOPS |
| FP8 | 1.979 PFLOPS | 4.5 PFLOPS |
| FP4 | NaN | 9 PFLOPS |
| Memoria de GPU | 80 GB HBM3 | 180GB HBM3E |
| Ancho de banda de memoria de GPU | 3.35 TB/s | 7.7TB/s |
| Ancho de banda NVLink por GPU | 900GB/s | 1,800GB/s |
El microbenchmarking a nivel de operador de GEMM y atención muestra lo siguiente:
- Kernels BF16 y FP8 cuBLAS, CUTLASS GEMM: hasta 2× más rápido que GEMMs de cuBLAS en H100;
- Atención: la velocidad de cuDNN es 2× más rápida que FA3 en H100.
Los resultados de evaluación comparativa sugieren que el B200 es excepcionalmente bien adecuado para cargas de trabajo de IA a gran escala, especialmente modelos generativos que requieren alto rendimiento de memoria y computación densa.
Desafíos con Pilas de Inferencia Estándar
La ejecución de FLUX-dev en canalizaciones de inferencia típicas (p.ej. PyTorch + Hugging Face Diffusers), incluso en GPUs de gama alta como H100, presenta varios desafíos:
- Alta latencia por imagen debido a sobrecarga de CPU-GPU y falta de fusión de kernels;
- Utilización subóptima de GPU y núcleos de tensor inactivos;
- Cuellos de botella de memoria y ancho de banda durante pasos de difusión iterativos.
Los objetivos de optimización de servir inferencia a gran escala y de bajo costo son mayor rendimiento y menor latencia, reduciendo el costo de generación de imágenes.
Marco de Inferencia Propietario de WaveSpeedAI
WaveSpeedAI aborda estos cuellos de botella con un marco propietario construido específicamente para inferencia generativa. Desarrollado por el fundador Zeyi Cheng, este marco es nuestro motor de inferencia de alto rendimiento interno optimizado específicamente para modelos de transformador de difusión de última generación como FLUX-dev y Wan 2.1. Las innovaciones clave en el motor de inferencia incluyen:
- Ejecución de GPU de extremo a extremo eliminando cuellos de botella de CPU;
- Kernels CUDA personalizados y fusión de kernels para ejecución optimizada;
- Cuantización avanzada y precisión mixta (BF16/FP8) usando el Transformer Engine de Blackwell manteniendo la máxima precisión;
- Planificación y preasignación de memoria optimizadas;
- Mecanismos de programación centrados en latencia que priorizan la velocidad sobre la profundidad de lotes.
Nuestro motor de inferencia sigue un co-diseño HW-SW, utilizando completamente la capacidad de computación y memoria del B200. Representa un salto significativo hacia adelante en el servicio de modelos de IA, permitiéndonos ofrecer inferencia de latencia ultra-baja y alta eficiencia a escala de producción. Evaluamos cómo estas optimizaciones impactan la calidad de salida, priorizando optimizaciones sin pérdidas vs. sueltas. Es decir, no aplicamos optimización que pudiera reducir significativamente las capacidades del modelo o colapsar completamente la calidad de salida visible, como la representación de texto y la semántica de escenas.
Evaluación comparativa: WaveSpeedAI en B200 vs. línea base H100
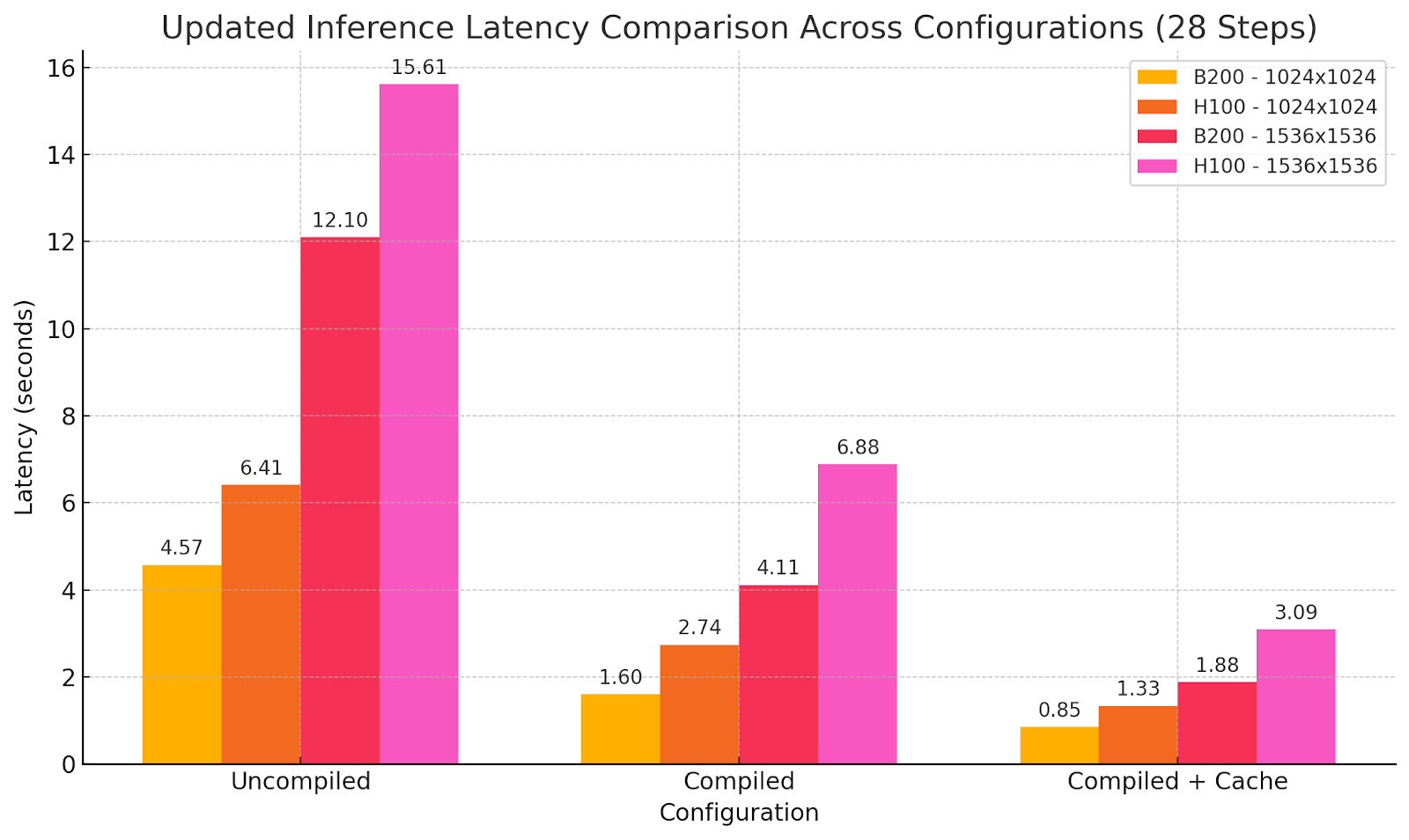
Salidas de modelo usando diferentes configuraciones de optimización:

Solicitud: fotografía de una mujer alternativa con una bandana naranja, cabello largo marrón claro, gafas de marco transparente, piercing en el tabique, petos beige colgando de un hombro, una camiseta blanca debajo, está sentada en su apartamento en una alfombra bohemia, en el estilo de una sesión de fotos de revista Vogue
Implicaciones
Las mejoras de rendimiento se traducen en:
- Diseño de algoritmos de IA (p.ej. caché de activación de DiT) y optimización de sistemas, usando kernels sintonizados para la arquitectura de GPU, para mejor utilización de HW;
- Latencia de inferencia reducida llevando a nuevas posibilidades (p.ej. Test-Time Compute in diffusion models);
- Menor costo por imagen debido a mejor eficiencia y utilización de hardware reducida.
Hemos logrado proporción de costo-rendimiento B200 igual a H100 pero con la mitad de latencia de generación. Por lo tanto, el costo por generación no aumenta mientras que ahora se habilitan nuevas posibilidades en tiempo real sin sacrificar las capacidades del modelo. A veces más no es más sino diferente, y aquí hemos logrado una nueva etapa de rendimiento, proporcionando un nuevo nivel de experiencia de usuario en generación de imágenes usando modelos SOTA.
Esto permite herramientas creativas receptivas, plataformas de contenido escalables y estructuras de costos sostenibles para IA generativa a escala.
Conclusión y Próximos Pasos
La implementación de FLUX-dev usando B200 demuestra lo que es posible cuando hardware de clase mundial se encuentra con software de la mejor clase. Estamos empujando las fronteras de la velocidad y eficiencia de inferencia en WaveSpeedAI, fundada por Zeyi Cheng — creador de stable-fast, ParaAttention y nuestro motor de inferencia interno. En los próximos lanzamientos, nos enfocaremos en inferencia eficiente de generación de vídeo y cómo lograr inferencia casi en tiempo real. Nuestra asociación con DataCrunch representa una oportunidad para acceder a GPUs de última generación como B200 y el próximo NVIDIA GB200 NVL72 (Pre-ordenar clústeres GB200 NVL72 de DataCrunch) mientras co-desarrollamos una pila crítica de infraestructura de inferencia.
Comienza Hoy:
- Sitio Web de WaveSpeedAI
- Todos los Modelos de WaveSpeedAI
- Documentación de API de WaveSpeedAI
- Instancias bajo demanda/spot B200 de DataCrunch
Únete a nosotros mientras construimos la infraestructura de inferencia generativa más rápida del mundo.
Artículos relacionados

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparación Completa

Guía Completa de Seedream 5.0-Preview: Generación Inteligente de Imágenes

Apple SHARP: Convierte Cualquier Foto en 3D en Menos de un Segundo

Seedream 4.5 vs Nano Banana Pro: ¿Cuál es el mejor modelo de IA para imágenes?
Mejor Alternativa a Adobe Firefly en 2026: WaveSpeedAI para Generación de Imágenes con IA