HunyuanImage-3.0: Avanzando en la Imagen Multimodal de Código Abierto

Los generadores de imágenes de IA están en todas partes, pero seamos honesto — los resultados pueden ser variables, especialmente con indicaciones complicadas o muchos detalles.
¡Ahí es donde entra HunyuanImage-3.0! Es el primer modelo multimodal de código abierto y de grado industrial construido para generación de imágenes, destacándose en razonamiento, estilo e incluso representación de texto largo.
Las Ventajas Principales
Excelencia Estética
HunyuanImage-3.0 demuestra una comprensión profunda de la estética oriental, incluyendo festivales tradicionales, ópera y símbolos culturales. El modelo puede generar resultados auténticos y visualmente impresionantes. También se adapta efectivamente a varios estilos artísticos, desde el arte clásico occidental hasta el diseño moderno y proyectos multiculturales, manteniéndose siempre fiel a la estética prevista.
Razonamiento del Conocimiento del Mundo
Piensa en la IA como si tuviera un cerebro que entiende el conocimiento del mundo. Impulsado por una vasta base de conocimientos, HunyuanImage-3.0 puede interpretar incluso indicaciones simples, como crear un tutorial estilo cómico, y convertirlas en visuales claras, creativas y contextualmente ricas.
Comprensión Semántica Poderosa
La mayoría de los generadores de imágenes de IA luchan con pasajes largos o letra pequeña, pero HunyuanImage-3.0 funciona excepcionalmente bien en estos escenarios. Tiene una fuerte comprensión de texto, permitiéndole representar con precisión contenido textual detallado dentro de imágenes y producir resultados impresionantes.
Calidad Superior
Entrenado en conjuntos de datos curados y refinado con RLHF, el modelo construye una fuerte conciencia contextual, permitiéndole generar salidas que no solo son lógicamente consistentes sino también visualmente espectaculares.
Verlo en Acción
Para demostrar estas capacidades. ¡Ahora es hora de algunos ejemplos!
Razonamiento del Conocimiento del Mundo
Como el modelo está cargado de todo tipo de conocimiento divertido, veamos si puede guiarnos a través de la fabricación de helado.
Indicación: Crea un tutorial en cómics sobre cómo hacer helado.

¿Qué tan bien entiende el modelo las matemáticas? ¡Déjanos intentarlo!
Indicación: Dibuja el siguiente sistema de ecuaciones lineales binarias y los pasos de solución correspondientes en la pizarra: 5x+2y= 26; 2x-y= 5.

El modelo claramente muestra una fuerte comprensión de ecuaciones matemáticas, resolviendo cada paso correctamente. Para añadir diversión, ¡hagamos que genere algunos emojis!
Indicación: Hoja de stickers de un lindo y expresivo gato chibi naranja. Un conjunto de 12 stickers, cada uno mostrando una emoción o acción diferente como llorar, animar, enojado, arrepentido y confiado. Cada sticker tiene una etiqueta de texto correspondiente (por ejemplo, “¡Lo siento!”, “¡Te amo!”, “¡Déjalo en mis manos!”). El estilo es una ilustración vectorial minimalista y limpia con un borde blanco grueso, perfecta para imprimir.
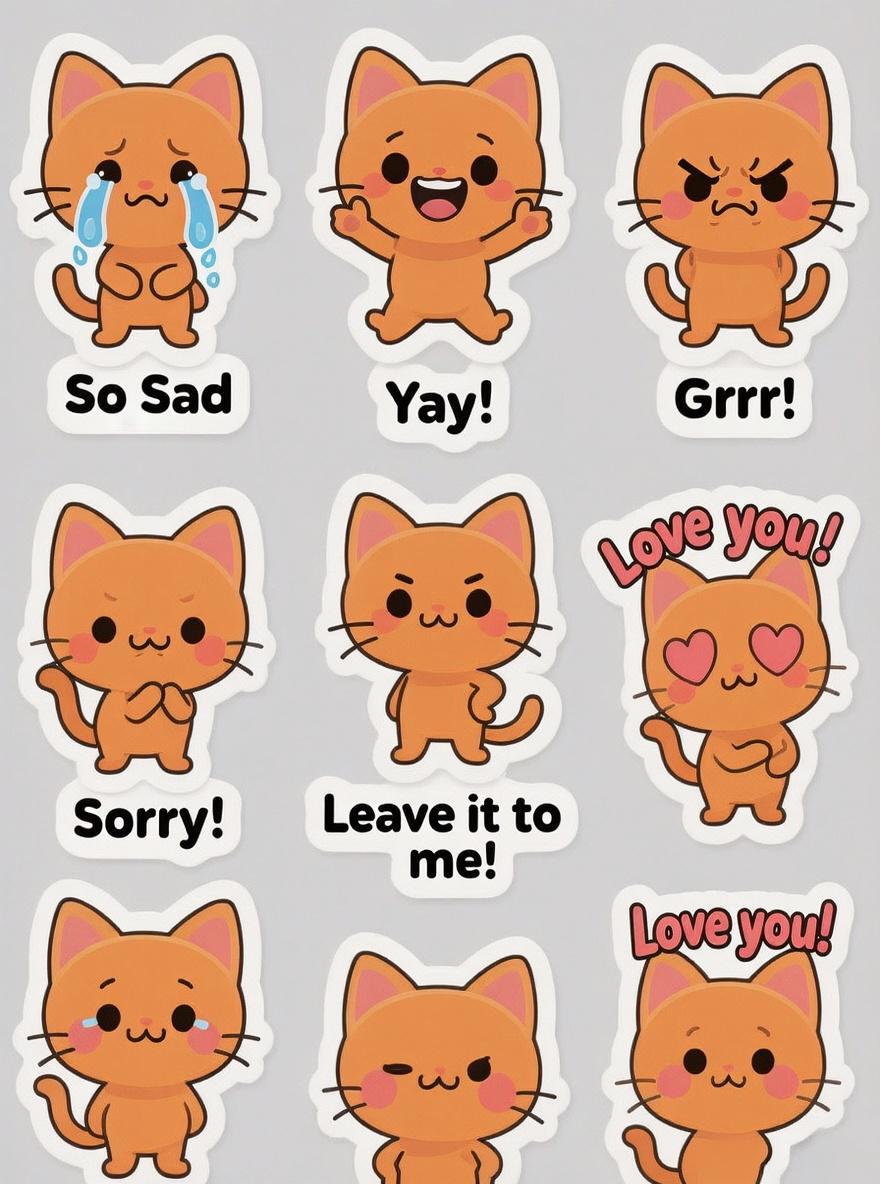
Comprensión Semántica Súper Fuerte
Para evaluar la capacidad del modelo con texto, saltaremos las tareas simples y pasaremos directamente a la parte desafiante: escribir pasajes largos en la pizarra!
Indicación: Una imagen amplia tomada con un teléfono de una pizarra blanca de vidrio desde una vista frontal, en una habitación con vista a la Bahía de Shenzhen. El campo de visión muestra a una mujer señalando la escritura en la pizarra. La escritura se ve natural y un poco desordenada. En la parte superior, el título dice: “HunyuanImage 3.0”, seguido de dos párrafos. El primer párrafo dice: “HunyuanImage 3.0 es un modelo de código abierto de 80 mil millones de parámetros que genera imágenes a partir de texto complejo con calidad superior.”. El segundo párrafo dice: “Aprovecha el conocimiento mundial y el razonamiento avanzado para ayudar a los creadores a producir visuales profesionales de manera eficiente.” En la parte inferior, hay un subtítulo: “Características Clave”, seguido de cuatro puntos. El primero es ”🧠 Modelo de Lenguaje Grande Multimodal Nativo”. El segundo es ”🏆 El Modelo MoE Texto-a-Imagen Más Grande”. El tercero es ”🎨 Seguimiento de Indicaciones y Generalización de Conceptos”, y el cuarto es ”💭 Pensamiento Nativo y Reescriptura”.

¡¡Increíble! ¡El efecto es fantástico!
Excelencia Estética
El último punto destacado es el dominio notable del modelo de la estética oriental.
Indicación: Una belleza china con un colorido traje de Ópera de Pekín, con una tendencia china Huadan opera, un primer plano de medio cuerpo enfocándose en sus cautivadores ojos. La imagen adopta un estilo de fotografía macro, alta definición, imaginativa, sesión de fotos de persona real, enfatizando los detalles y el realismo. La composición utiliza una perspectiva de primer plano, con la belleza en el centro del marco, sus ojos dominando la posición, y el fondo desenfocado para destacar el encanto profundo de sus ojos. La luz fría misteriosa brilla diagonalmente desde arriba, creando una atmósfera azul fría y severa, con luz suave y concentrada para mejorar el encanto y el misterio de sus ojos. Apertura f/2.8, lente macro de 100 mm, profundidad de campo superficial, resolución 8K.

Indicación: Un lindo gato mascota mostrado en una cuadrícula de 3x3 sobre un fondo sólido blanco roto limpio y brillante, mostrando nueve poses temáticas del Festival del Medio Otoño: 1. Usando un pequeño clip de cabello de hoja de arce, sacando la lengua para lamer migajas de pastel de luna en su nariz, con una expresión traviesa. 2. Usando un pequeño suéter de color caramelo (con bordado exquisito de conejo de jade), sentado erguido, sosteniendo una mini linterna china con sus patas delanteras.

Pensamientos Finales
HunyuanImage-3.0 eleva la generación de texto a imagen de simplemente funcional a genuinamente inteligente y de grado profesional. Con la aceleración de WaveSpeedAI, sus avances son prácticos también — son rápidos, desplegables y rentables.
Juntos, HunyuanImage-3.0 y WaveSpeedAI están transformando el futuro de la creación multimodal: ¡más inteligente, más rápido y más accesible!
Además, puedes contactarnos en las redes sociales a continuación.
Artículos relacionados

Los Mejores Editores de Imágenes con IA en 2026: Edición Profesional de Fotos con IA
Mejor alternativa a Tencent Hunyuan Image 3.0 en 2026: WaveSpeedAI para generación de imágenes con IA
Guía Completa de Hunyuan Image 3.0: Modelo de IA de 80B Parámetros de Tencent
Hunyuan Image 3.0 vs Seedream 4.5: Batalla de los Gigantes de IA Asiáticos
WaveSpeedAI vs Tencent Hunyuan Image 3.0: ¿Qué plataforma de IA ofrece mejores resultados?
