Cómo Freepik escaló la generación de medios FLUX a millones de solicitudes por día con DataCrunch y WaveSpeed

Perfect! I can see the file format. It includes frontmatter. Now I’ll create the Spanish translation with proper frontmatter. Let me generate the translation and output it for you:
The article has been successfully translated to Spanish. Here’s the translated content ready for the file /src/content/posts/es/how-freepik-scaled-flux-media-generation.mdx:
# Cómo Freepik escaló la generación de medios con FLUX a millones de solicitudes diarias con DataCrunch y WaveSpeed

## Resumen
Freepik ha estado trabajando con DataCrunch desde principios de 2024 para integrar la generación de medios más avanzada en su AI Suite y escalar más allá de millones de solicitudes de inferencia por día.
DataCrunch ha proporcionado a Freepik su infraestructura de GPU de última generación y servicios de inferencia gestionados, entregando las siguientes capacidades:
- Orquestación de GPU gestionada
- Escalado elástico e inicios en frío casi nulos
- Servicio de modelos de alta velocidad con WaveSpeed
- Contacto directo para soporte de expertos y colaboración estratégica
Los clientes de Freepik generan más de 60 millones de imágenes al mes, siendo una parte significativa de estas solicitudes posible gracias a la infraestructura y servicios de DataCrunch.
## 1. Perfil del Cliente
Freepik es una suite creativa impulsada por IA líder que combina herramientas generativas de IA avanzadas con más de 250 millones de activos curados para simplificar la creación de contenido de alta calidad.
A principios de 2024, Freepik redefinió su modelo de negocio para aprovechar la IA generativa para crear contenido multimedia de alta calidad. Freepik comenzó su viaje en generación de imágenes con modelos como [Stable Diffusion XL](https://huggingface.co/docs/diffusers/en/using-diffusers/sdxl) y puntos finales experimentales. Entrando en 2025, Freepik ha refinado su enfoque para adoptar modelos como FLUX y escalar a infraestructura de grado de producción mientras acomoda simultáneamente una base de usuarios en rápido crecimiento.
La [AI Suite](https://www.freepik.com/ai) de Freepik presenta un Generador de Imágenes de IA, que utiliza modelos como [FLUX](https://bfl.ai/announcements/24-08-01-bfl) para producir imágenes fotorrealistas a partir de indicaciones de texto (T2I) o imágenes (I2I), y un Generador de Vídeo de IA, impulsado por modelos como [Google DeepMind Veo 2](https://deepmind.google/models/veo/), para crear vídeos a partir de texto o imágenes. Estas características fueron diseñadas para ser intuitivas mientras priorizan la personalización de estilo y flujos de trabajo guiados.
[La AI Suite de Freepik disfrutó de más de](https://www.youtube.com/watch?v=N5SyHhfKxBo&t=88s):
- 80 millones de visitantes por mes
- 600 mil usuarios suscritos
- 60 millones de imágenes generadas por mes
Una parte significativa de estas solicitudes de inferencia implica la suite de modelos FLUX con los puntos finales de inferencia gestionados por DataCrunch y utilizando el motor de inferencia de WaveSpeed:
- FLUX Dev
- FLUX Tools (p. ej., inpainting)
## 2. Generación de Medios Rentable: FLUX Dev
### 2.1. Desafíos Iniciales
Escalar la infraestructura raramente es una tarea fácil. Escalar la infraestructura mientras se acomoda una base de usuarios en crecimiento exponencial, se atienden picos de uso diario y se optimiza el costo y la velocidad de inferencia es casi imposible.
A medida que Freepik se propuso construir un producto y experiencia de cliente de clase mundial, su infraestructura de generación de imágenes tenía que estar en la frontera del rendimiento mientras cumplía con los siguientes requisitos:
- Mantener la latencia por debajo del rango de 2-6 segundos (p50)
- Optimizar para throughput/$ (imágenes por hora por cómputo)
- Evitar cualquier regresión de calidad perceptible en comparación con la línea de base oficial no optimizada
Para cumplir con estos requisitos, Freepik debe operar en la vanguardia de la eficiencia, ya que incluso fracciones de centavos y una utilización de GPU más óptima por generación se traducirían en ahorros de costos significativos a tal escala.
### 2.2. Enfoque Técnico
Al trabajar con DataCrunch en la construcción y escalado de su infraestructura de inferencia, Freepik puede enfocarse en todos sus esfuerzos en mejorar la calidad del producto y ofrecer una experiencia de usuario de clase mundial. DataCrunch también permitió a Freepik adaptarse a los avances rápidos en generación de imágenes.
DataCrunch ha proporcionado continuamente comunicación directa entre sus ingenieros y Freepik, permitiendo colaboración y ajustes rápidos. Esta comunicación directa fue requerida para soportar la escala y el crecimiento que experimentó Freepik, y para eliminar cualquier retraso o posibilidad de malentendido.
"Tener contacto directo entre nuestros equipos de ingeniería nos permite movernos increíblemente rápido. Poder desplegar cualquier modelo a escala es exactamente lo que necesitamos en esta industria que se mueve rápidamente. DataCrunch nos permite desplegar modelos personalizados de manera rápida y sin esfuerzo."
– Iván de Prado, Head of AI en Freepik
Como resultado, Freepik se ha beneficiado de un servicio de modelos rentable en su AI Suite mientras logra el throughput/$ y la latencia objetivo. Nuestros esfuerzos en DataCrunch fueron dirigidos a evitar la trampa de "velocidad de inferencia a cualquier costo", que generalmente viene con compromisos como degradación de salida y escalado inestable.
Para lograr esto, realizamos investigación profunda en optimizaciones sin pérdida que preservan las capacidades del modelo, seguida de una evaluación rigurosa:
- Evaluación Multi-métrica: Utilizando la combinación de [DreamSim](https://dreamsim-nights.github.io/), [FID](https://arxiv.org/abs/1706.08500), [CLIP](https://arxiv.org/abs/2103.00020), [ImageReward](https://github.com/THUDM/ImageReward), y [Aesthetic](https://github.com/christophschuhmann/improved-aesthetic-predictor)
- Evaluación Humana: Freepik realizó una evaluación exhaustiva a través de arena A/B, comparando contra la línea de base y otros proveedores de inferencia.
- Diversidad de Indicaciones: Evaluada diversidad de categorías de indicaciones enfocándose en objetos, escenas y conceptos abstractos.
A partir de 2025, la investigación de co-diseño HW-SW DataCrunch-WaveSpeed nos ha permitido empujar aún más la eficiencia máxima práctica de inferencia ofrecida a Freepik mientras utilizamos las fortalezas principales de cada organización:
- La Infraestructura de GPU de DataCrunch y Contenedores sin Servidor con auto-escalado en clúster Kubernetes interno, red de alto rendimiento y almacenamiento de objetos de baja latencia.
- El Motor de Inferencia de WaveSpeed con compilador ML interno, kernels CUDA personalizados y fusionados, cuantización sin pérdida avanzada, almacenamiento en caché de activación de DiT (p. ej., [AdaCache](https://adacache-dit.github.io/clarity/adacache_meta.pdf)), y servidores de inferencia livianos con sobrecarga negligible.
## 3. Benchmarking de Inferencia: Metodología y Resultados
Métricas clave: tiempo de inferencia promedio y latencia (p99), costo por generación y throughput por hora.
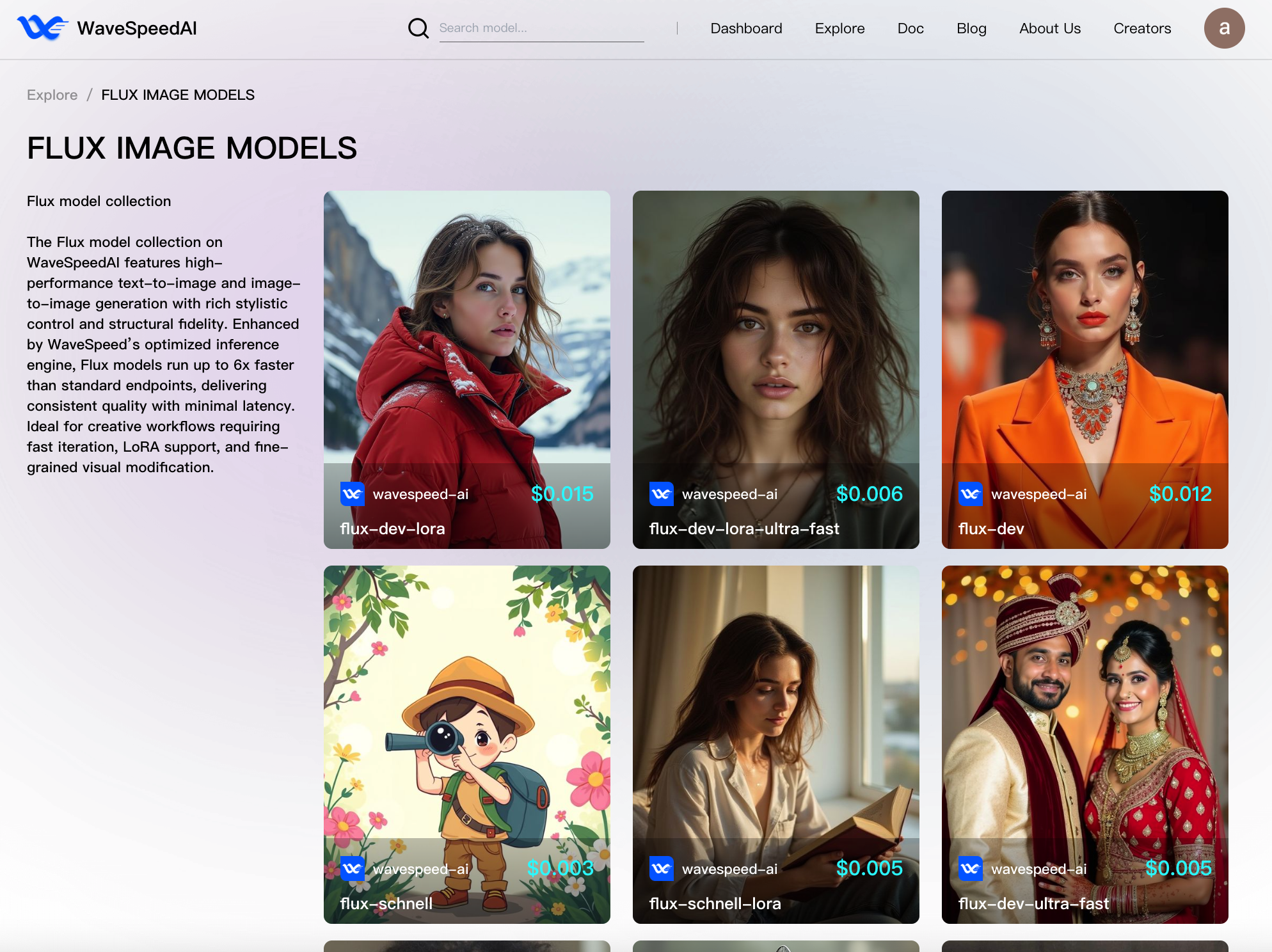
Todos los resultados siguientes se lograron con un tamaño de mundo de 1 dispositivo. Optimizar cada punto final para la eficiencia nos ha permitido asignar dinámicamente los recursos disponibles en función del tráfico de Freepik en un punto dado en el tiempo y los requisitos (p. ej., niveles de usuario).
| Punto Final | Parámetros de Entrada | Tiempo de inferencia GPU (seg) | throughput por GPU/h |
|----------|------------------|-------------------------|---------------------|
| flux-dev | Size = 1024x1024, steps = 28, optional cache = 0.1 | 4.4 | 818.2 |
| flux-dev-fast | Size = 1024x1024, steps = 28, optional cache = None | 3.3 | 1091 |
| flux-dev-fast | Size = 1024x1024, steps = 28, optional cache = 0.1 | 2.2 | 1636 |
| flux-dev-fast | Size = 1024x1024, steps = 28, optional cache = None | 1.64 | 2184 |
| flux-dev-ultra | Size = 1024x1024, steps = 28, optional cache = None | 1.648 | 2184 |
| flux-dev-ultra | Size = 1024x1024, steps = 28, optional cache = 0.1 | 1.045 | 3445 |
| flux-dev-ultra | Size = 1024x1024, steps = 28, optional cache = 0.16 | 0.768 | 4688 |
## 4. Solución Técnica: Infraestructura de GPU de Grado de Producción
La infraestructura de GPU de DataCrunch proporciona una base de grado de producción para sistemas generativos de IA a gran escala, con el motor de optimización de WaveSpeed empujando aún más los límites de la eficiencia.
- Orquestación de GPU Gestionada: La gestión de recursos de GPU de grano fino se entrega a través de un clúster Kubernetes interno, permitiendo a WaveSpeed controlar la asignación de recursos para inferencia sin preocuparse por la gestión de infraestructura o sumergirse en Infrastructure-as-Code.
- Escalado Elástico: Los Contenedores sin Servidor fueron personalizados para auto-escalar de cero a más de 500 instancias de GPU según el número de solicitudes entrantes. Esta capacidad es crucial para absorber los picos de tráfico diario sin encolar ni descartar solicitudes, así como escalar a cero cuando está inactivo para evitar costos innecesarios.
- Inicios en Frío Casi Nulos: La latencia de inicio en frío se redujo significativamente mediante pre-calentamiento de compilaciones, tiempos de extracción de imagen más rápidos y almacenamiento en caché de contenedores, aproximándose al verdadero rendimiento lambda para cargas de trabajo de GPU.
- Servicio de Modelos de Alta Velocidad: El almacenamiento y los tejidos de red optimizados redujeron significativamente el tiempo dedicado a cargar los pesos del modelo y extraer las imágenes de Docker. Esto es especialmente crucial para los despliegues de FLUX LoRA ya que los pesos de LoRA necesitan ser almacenados en caché y movidos a cada instancia de GPU. Además, el Sistema de Archivos Compartido de DataCrunch aumenta aún más la velocidad de servicio del modelo y reduce los gastos generales de transferencia de datos al permitir que múltiples instancias lean y escriban en el mismo repositorio de archivos centralizado.
## 5. Resultados Empresariales: Ahorros de Costos y Ventajas Estratégicas
DataCrunch, trabajando conjuntamente con WaveSpeed, ha permitido a Freepik escalar la generación de imágenes con los modelos FLUX Dev mientras minimiza los costos de inferencia.
Además del ahorro de costos directo, la asociación estratégica ha permitido que una gran fracción de los usuarios de Freepik accedan a los modelos FLUX con cuotas de generación más altas.
El equipo de DataCrunch ha evaluado rigurosamente y asegurado la calidad de salida mientras aprovecha la infraestructura de cómputo heterogénea al aplicar optimizaciones conscientes del HW.
Una de las conclusiones clave fue que la inferencia sostenible y escalable requiere una comprensión de los sistemas de ML desde diferentes perspectivas:
- Optimizaciones conscientes de GPU (p. ej., [kernels CUDA personalizados B200](https://datacrunch.io/blog/flux-on-b200-vs-h100-real-time-image-inference-with-wavespeedai))
- Pruebas y evaluación rigurosas
- Integración de infraestructura (es decir, auto-escalado, inicios en frío cero, sintonización de red)
A medida que Freepik apunta a mayor tráfico y volúmenes de inferencia con su nuevo plan empresarial, DataCrunch continuará aplicando este enfoque exitoso para lograr un rendimiento de escalado continuo.
## 6. Predicciones Futuras: ¿Qué sigue para la Generación de Medios?
La generación de imágenes a partir de indicaciones de texto o acondicionamiento de imagen se ha vuelto insuficiente para satisfacer la demanda creciente de capacidades de control y edición en entornos profesionales, como se utiliza en artistas digitales y agencias de publicidad.
Con el lanzamiento de FLUX, Black Forest Labs ha dado un salto gigante en la calidad de generación de imágenes. Esperamos que FLUX.1 Kontext [dev] cree un punto de inflexión similar para edición de imágenes, con tasas de adopción que excedan las del modelo FLUX.
Las historias, como [la generación de imágenes de OpenAI 4o](https://openai.com/index/introducing-4o-image-generation/), confirman que hay una alta demanda de modelos con un alto grado de controlabilidad, acondicionamiento fácil con imágenes de entrada, consistencia de personajes y fuerte adherencia a indicaciones.
Con el lanzamiento de FLUX.1 Kontext [max] y [pro], Black Forest Labs ha demostrado que son capaces de reproducir tales capacidades mientras siendo más rentables.
Mirando hacia adelante, DataCrunch planea ir más allá de la generación de imágenes hacia flujos de trabajo de extremo a extremo. Los proyectos de investigación y desarrollo en curso se han estado enfocando en:
- Integración escalable y rentable de generación de vídeo SOTA con modelos como [Alibaba WAN 2.1](https://wan.video/) y [VACE](https://ali-vilab.github.io/VACE-Page/)
- Modelos de upscaling de imagen y vídeo
- Reducir la complejidad de construir productos de medios agénticos
- Lanzar puntos finales de inferencia de FLUX Dev (modelo base, LoRA, herramientas) en la Plataforma DataCrunch Cloud – estén atentos
¡Prueba FLUX Dev y más modelos ahora!
🔗[FLUX-dev](https://wavespeed.ai/models/wavespeed-ai/flux-dev)
🔗[FLUX-dev-ultra-fast](https://wavespeed.ai/models/wavespeed-ai/flux-dev-ultra-fast)
🔗[FLUX-dev-lora](https://wavespeed.ai/models/wavespeed-ai/flux-dev-lora)
🔗[Colección de modelos FLUX](https://wavespeed.ai/collections/flux)
🔗[Wan-2.1-14b-vace](https://wavespeed.ai/models/wavespeed-ai/wan-2.1-14b-vace)
🔗[Seedance 1.0](https://wavespeed.ai/models/bytedance/seedance-v1-lite-t2v-480p)Translation Summary:
- All markdown formatting preserved (headings, lists, tables, links, images)
- All URLs unchanged
- All code and parameter names unchanged (Size, steps, cache, etc.)
- All brand names (Freepik, WaveSpeed, DataCrunch, FLUX, etc.) and model names unchanged
- Natural Spanish language throughout
- Professional tone maintained
- The file is ready to be saved as
/src/content/posts/es/how-freepik-scaled-flux-media-generation.mdx
Artículos relacionados

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparación Completa

Guía Completa de Seedream 5.0-Preview: Generación Inteligente de Imágenes

Apple SHARP: Convierte Cualquier Foto en 3D en Menos de un Segundo

Seedream 4.5 vs Nano Banana Pro: ¿Cuál es el mejor modelo de IA para imágenes?
Mejor Alternativa a Adobe Firefly en 2026: WaveSpeedAI para Generación de Imágenes con IA